今天我将介绍在SQLServer 中的三种连接操作符类型,分别是:循环嵌套、哈希匹配和合并连接。主要对这三种连接的不同、复杂度用范例的形式一一介绍。
本文中使用了示例数据库AdventureWorks ,下面是下载地址:http://msftdbprodsamples.codeplex.com/releases/view/4004
简介:什么是连接操作符
连接操作符是一种算法类型,它是SQLServer优化器为了实现两个数据集合之间的逻辑连接选择的操作符。优化器可以基于请求查询、可用索引、统计信息和估计行数等不同的场景为每一套数据选择不同的算法
通过查看执行计划可以发现操作符如何被使用。接下来我们看一下如何具体使用。
NESTED LOOPS(循环嵌套)
我们通过下面的例子来展示一下(查询2001年7月份的数据):
SELECT OH.OrderDate, OD.OrderQty, OD.ProductID, OD.UnitPrice FROM Sales.SalesOrderHeader AS OH JOIN Sales.SalesOrderDetail AS OD ON OH.SalesOrderID = OD.SalesOrderID WHERE OH.OrderDate BETWEEN '2001-07-01' AND '2001-07-31'
执行计划的结果如下:
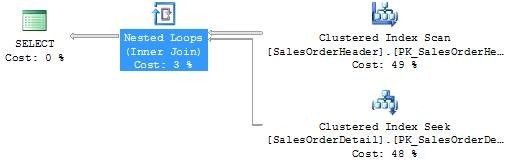
图右上方的叫“outer input”,在其下面的叫做“inner input”
本质上讲,“Nested Loops”操作符就是:为每一个记录的外部输入找到内部输入的匹配行。
技术上讲,这意味着外表聚集索引被扫描获取外部输入相关的记录,然后内表聚集索引查找每一个匹配外表索引的记录。
我们可以通过把鼠标放在聚集索引扫描操作符上面来验证这个信息,请看这个tooltip:

看这个执行的估计行数是1,索引查找tooltip如下:
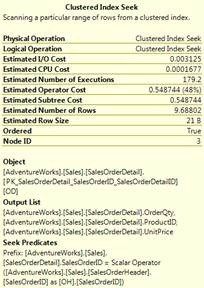
这次发现执行的估计行数是179,这是很接近返回的外部输入行的。
按照复杂度计算(假设N是外部输出的行数,M是总行数在SalesOrderDetai表的):查询复杂度是O(NlogM),这里logM是在内部输入表的每次查找的复杂度。
当外部输入比较小并且内部输入有索引在连接的字段上的时候SQLServer 优化器更喜欢选择这种操作符类型(Nested Loop)。外部和内部输入的数据行差距越大,这个操作符提供的性能越高。
MERGE Join(合并连接)
“Merge”算法是连接两个较大且按序存储的在连接键上最有效的方式。请看一下下面这个查询例子(查询返回用户和销售表的ID):
SELECT OC.CustomerID, OH.SalesOrderID FROM Sales.SalesOrderHeader AS OH JOIN Sales.Customer AS OC ON OH.CustomerID = OC.CustomerID
查询执行计划如下:
- 首先我们注意到两套数据是在CustomerID上是有序的:因为聚集索引是有序的且在SalesorderHeader表上该字段是非聚集索引。
- 根据在操作符的箭头(鼠标放在上面),我们能看到每个返回结果行数都是很大的。
- 除此之外,在On 的子句后面要用=操作符。
就是这三个因素会导致优化器选择Merge Join查询操作符。
使用这种连接操作符的最大的性能就是两个输入操作符执行一次。我们能把鼠标放在两个数据的上面看一下执行的次数都是1,也就是说算法是很有效率的。
合并连接同时读取两个输入然后比较他们。如果匹配就返回,否则,行数较小的被放弃,因为两边输入是有序的。放弃的行不再匹配任何行。
知道其中一个表完毕一直重复匹配,即使另一个表还有数据,那么最大的时间复杂的消耗就是两个表完全不同键值,那么最大的复杂度就是: O(N+M)。
HASH Match(哈希匹配)
“Hash”连接是我们称为 “the go-to guy” 的操作符。当其他连接操作符都不支持的场景时,就会选择这种操作符。比如当表恰好不排序,或者没有索引时。当优化器选择这种操作符,一般来说可能是我们没有做好一些基础工作(例如,加索引)。但是有些情况(复杂查询)没有别的方式,只能选择它。
请看下面这个查询(获取contacts 表中姓和名中以“John”开始的包含销售的ID字段的数据集):
SELECT OC.FirstName, OC.LastName, OH.SalesOrderID FROM Sales.SalesOrderHeader AS OH JOIN Person.Contact AS OC ON OH.ContactID = OC.ContactID WHERE OC.FirstName LIKE 'John%'
The execution plan looks like this:
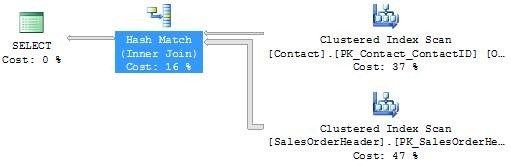
由于ContactID列没有索引,所以选择哈希操作符。
在深入理解这个例子之前,介绍两个重要的概念:一个是“Hashing”函数,一个是“Hash Table”。
函数是一个程序性函数,它接收1或者多个值然后转换他们为一个符号值(通常是数字)。这个函数通常是单向的,意味着不能反转回来原始值,但是确定性保证如果你提供了相同的值,符号值是完全一样的。也就是说,几个不同的输入值,可以有相同的Hash值。
“Hash Table”是一个数据结构,把所有行都放到一个相同尺寸的桶里面。每一个桶代表一个哈希值。这意味着当你激活函数的行,使用结果你就会知道它属于哪个桶。
利用统计信息,SQLServer 会选择较小的两个数据输入来提供构造输入,并且输入被用来在内存中创建哈希表。如果没有足够的内存,在tempdb中会使用物理磁盘。在哈希表建立后,SQLServer将从较大的表中得到数据,叫做探测输入。利用哈希匹配函数与哈希表比较,然后返回匹配行。在图形执行计划中,构造输入的查询在上面,探测输入的查询在下面。
只要较小的表非常小,这个算法就是非常有效的。但是如果两个表都非常大,这可能是非常低效的执行计划。
查询Hints
利用Hints,破事SQLServer使用指定的连接类型。但是强烈不推荐这么做,尤其在生产环境,因为没有永恒的最佳选择(因为数据在变化),并且优化器通常是正确的。
添加OPTION 子句作为查询的结尾,使用关键字LOOP JOIN, MERGE JOIN 或者 HASH JOIN可以强制执行连接。
看看如何实现:
SELECT OC.CustomerID, OH.SalesOrderID FROM Sales.SalesOrderHeader AS OH JOIN Sales.Customer AS OC ON OH.CustomerID = OC.CustomerID OPTION (HASH JOIN) SELECT OC.FirstName, OC.LastName, OH.SalesOrderID FROM Sales.SalesOrderHeader AS OH JOIN Person.Contact AS OC ON OH.ContactID = OC.ContactID WHERE OC.FirstName LIKE 'John%' OPTION (LOOP JOIN) SELECT OC.FirstName, OC.LastName, OH.SalesOrderID FROM Sales.SalesOrderHeader AS OH JOIN Person.Contact AS OC ON OH.ContactID = OC.ContactID WHERE OC.FirstName LIKE 'John%' OPTION (MERGE JOIN)
总结
Nested Loops
- 复杂度: O(NlogM)。
- 其中一个表很小的时候。
- 较大的表允许使用索引查找连接字段。
Merge Join
- 复杂度: O(N+M)。
- 两个输入的连接字段是有序的。
- 使用=操作符
- 适合非常大的表
Hash Match
- 复杂度: O(N*hc+M*hm+J)
- 最后默认的操作符
- 使用哈希表和动态哈希匹配函数匹配行
本篇随笔详细介绍了三种链接操作符和它们的触发机制,当然这些也都是动态的,就像前面说的没有最佳的操作符,只有最合适的,要根据实际请款选择不同的操作符。