
iOS 底层探索系列
上一篇我们一起探索了 iOS 类的底层原理,其中比较重要的四个属性我们都简单的过了一遍,我们接下来要重点探索第三个属性 cache_t,对于这个属性,我们可以学习到苹果对于缓存的设计与理解,同时也会接触到消息发送相关的知识。
一、探索 cache_t
1.1 cache_t 基本结构
我们还是先过一遍 OC 中类的结构:
struct objc_class : objc_object {
// Class ISA;
Class superclass;
cache_t cache; // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
class_rw_t *data() {
return bits.data();
}
...省略代码...
}接着我们查看源码中 cache_t 的定义:
struct cache_t {
struct bucket_t *_buckets;
mask_t _mask;
mask_t _occupied;
...省略代码...
}然后我们发现 cache_t 结构体的第一个成员 _buckets 也是一个结构体类型 bucket_t,我们再查看一下 bucket_t 的定义:
struct bucket_t {
private:
// IMP-first is better for arm64e ptrauth and no worse for arm64.
// SEL-first is better for armv7* and i386 and x86_64.
#if __arm64__
MethodCacheIMP _imp;
cache_key_t _key;
#else
cache_key_t _key;
MethodCacheIMP _imp;
#endif
public:
inline cache_key_t key() const { return _key; }
inline IMP imp() const { return (IMP)_imp; }
inline void setKey(cache_key_t newKey) { _key = newKey; }
inline void setImp(IMP newImp) { _imp = newImp; }
void set(cache_key_t newKey, IMP newImp);
};从源码定义中不难看出,bucket_t 其实缓存的是方法实现 IMP。这里有一个注意点,就是 IMP-first 和 SEL-first。
IMP-first is better for arm64e ptrauth and no worse for arm64.
- IMP-first 对 arm64e 的效果更好,对 arm64 不会有坏的影响。
SEL-first is better for armv7* and i386 and x86_64.
- SEL-first 适用于 armv7 * 和 i386 和 x86_64。
如果对 SEL 和 IMP 不是很熟悉的同学可以去 objc4-756 源码中查看方法 method_t 的定义:
struct method_t {
SEL name; // 方法选择器
const char *types; // 方法类型字符串
MethodListIMP imp; // 方法实现
...省略代码...
};通过上面的源码,我们大致了解了 bucket_t 类型的结构,那么现在问题来了,类中的 cache 是在什么时候以什么样的方式来进行缓存的呢?
1.2 LLDB 大法
了解到 cache_t 和 bucket_t 的基本结构后,我们可以通过 LLDB 来打印验证一下:

cache_t 内部的这三个属性,我们从其名称不难看出 _occupied 应该是表示当前已经占用了多少缓存,_mask 暂时不知道,_buckets 应该是存放具体缓存的地方。那么为了验证我们的猜想,我们调用代码来测试:

我们发现,断点断到 45 行的时候,_ocuupied 的值为 1,我们打印一下 _buckets 里面的内容看看:

我们可以看到,打印到 _buckets 的第三个元素的时候,我们的 init 方法被缓存了,也就是说 _ocuupied 确实是表示当前被缓存方法的个数。这里可能读者会说为什么 alloc 和 class 为什么没有被缓存呢?其实这是因为 alloc 和 class 是类方法,而根据我们前面探索类底层原理的时候,类方法是存储在元类里面的,所以这里类的缓存里面只会存储对象方法。
我们接着把断点过到 46 行:

_ocuupied 的值果然发生了变化,我们刚才的猜想进一步得到了验证,我们再往下面走一行:

此时 _ocuupied 值已经为 3 了,我们回顾一下当前缓存里面缓存的方法:
| _ocuupied 的值 | 缓存的方法 |
|---|---|
| 1 | NSObject下的init |
| 2 | NSObject下的init,person下的 sayHello |
| 3 | NSObject下的init,person下的 sayHello, person下的 sayCode |
那么,当我们的断点断到下一行的时候,是不是 _ocuupied 就会变为 4 呢? 我们接着往下走:

令人惊奇的事情发生了,_ocuupied 的值变成了 1,而 _mask 变成了 7。这是为什么呢?
如果读者了解并掌握散列表这种数据结构的话,相信已经看出端倪了。是的,这里其实就是用到了 开放寻址法 来解决散列冲突(哈希冲突)。
关于哈希冲突,可以借助鸽笼理论,即把 11 只鸽子放进 10 个抽屉里面,肯定会有一个抽屉里面有 2 只鸽子。是不是理解起来很简单? :)
通过上面的测试,我们明确了方法缓存使用的是哈希表存储,并且为了解决无法避免的哈希冲突使用的是开放寻址法,而开放寻址法必然要在合适的时机进行扩容,这个时机肯定不是会在数据已经装满的时候,我们可以进源码探索一下,我们快速定位到 cache_t 的源码处:
void cache_t::expand()
{
cacheUpdateLock.assertLocked();
uint32_t oldCapacity = capacity();
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;
if ((uint32_t)(mask_t)newCapacity != newCapacity) {
// mask overflow - can't grow further
// fixme this wastes one bit of mask
newCapacity = oldCapacity;
}
reallocate(oldCapacity, newCapacity);
}从上面的代码不难看出 expand 方法就是扩容的核心算法,我们梳理一下里面的逻辑:
cacheUpdateLock.assertLocked();- 缓存锁断言一下判断当前执行上下文是否已经上锁
uint32_t oldCapacity = capacity();- 通过
capacity()方法获取当前的容量大小
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;- 判断当前的容量大小,如果为0,则赋值为
INIT_CACHE_SIZE,而根据
enum {
INIT_CACHE_SIZE_LOG2 = 2,
INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2)
};可知 INIT_CACHE_SIZE 初始值为 4;如果当前容量大小不为 0,则直接翻倍。
到了这里相信聪明的读者根据我们上面的测试应该猜到了,我们的 _mask 其实就是容量大小减 1 后的结果。
reallocate(oldCapacity, newCapacity);- 最后调用
reallocate方法进行缓存大小的重置
我们接着进入 reallocate 内部一探究竟:
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity)
{
bool freeOld = canBeFreed();
bucket_t *oldBuckets = buckets();
bucket_t *newBuckets = allocateBuckets(newCapacity);
assert(newCapacity > 0);
assert((uintptr_t)(mask_t)(newCapacity-1) == newCapacity-1);
setBucketsAndMask(newBuckets, newCapacity - 1);
if (freeOld) {
cache_collect_free(oldBuckets, oldCapacity);
cache_collect(false);
}
}
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask)
{
mega_barrier();
_buckets = newBuckets;
mega_barrier();
_mask = newMask;
_occupied = 0;
}显然,_mask 是这一步 setBucketsAndMask(newBuckets, newCapacity - 1); 被赋值为容量减 1 的。
同样的,我们还可以通过 capacity 方法来验证
mask_t cache_t::capacity()
{
return mask() ? mask()+1 : 0;
}二、深入 cache_t
其实我们在探索 iOS 底层的时候,尽量不要站在上帝视角去审视相应的技术点,我们可以尽量给自己多抛出几个问题,然后尝试去解决每个问题,通过这样的探索,对提高我们阅读源码的能力十分重要。
通过前面的探索,我们知道了 cache_t 实质上是缓存了我们类的实例方法,那么对于类方法来说,自然就是缓存在了元类上了。这一点我相信读者应该都能理解。
2.1 方法缓存策略
按照最常规的思维,缓存内容最省时省力的办法肯定是来一个缓存一个,那么我们的 cache_t 是不是这么做的呢,实践出真知,我们一试便知。
我们在源码中搜索 capacity() 方法,我们找到了 cache_fill_nolock 方法:
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver)
{
cacheUpdateLock.assertLocked();
// Never cache before +initialize is done
if (!cls->isInitialized()) return;
// Make sure the entry wasn't added to the cache by some other thread
// before we grabbed the cacheUpdateLock.
if (cache_getImp(cls, sel)) return;
cache_t *cache = getCache(cls);
cache_key_t key = getKey(sel);
// Use the cache as-is if it is less than 3/4 full
mask_t newOccupied = cache->occupied() + 1;
mask_t capacity = cache->capacity();
if (cache->isConstantEmptyCache()) {
// Cache is read-only. Replace it.
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
}
else if (newOccupied <= capacity / 4 * 3) {
// Cache is less than 3/4 full. Use it as-is.
}
else {
// Cache is too full. Expand it.
cache->expand();
}
// Scan for the first unused slot and insert there.
// There is guaranteed to be an empty slot because the
// minimum size is 4 and we resized at 3/4 full.
bucket_t *bucket = cache->find(key, receiver);
if (bucket->key() == 0) cache->incrementOccupied();
bucket->set(key, imp);
}cache_fill_nolock 方法乍一看有些复杂,我们不妨将它分解一下:
第一行代码还是加锁的判断,我们直接略过,来到第二行:
if (cache_getImp(cls, sel)) return;- 通过
cache_getImp来判断当前cls下的sel是否已经被缓存了,如果是,直接返回。而cache_getImp底层实现是_cache_getImp,并且是在汇编层实现的。
cache_t *cache = getCache(cls);
cache_key_t key = getKey(sel);- 调用
getCache来获取cls的方法缓存,然后通过getKey来获取到缓存的key,这里的getKey其实是将SEL类型强转成cache_key_t类型。
mask_t newOccupied = cache->occupied() + 1;- 在
cache已经占用的基础上进行加 1,得到的是新的缓存占用大小newOccupied。
mask_t capacity = cache->capacity();- 然后读取现在缓存的容量
capacity。
然后接下来是一系列的判断:
if (cache->isConstantEmptyCache()) {
// Cache is read-only. Replace it.
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
}- 如果缓存为空了,那么就重新申请一下内存并覆盖之前的缓存,之所以这样做是因为缓存是只读的。
else if (newOccupied <= capacity / 4 * 3) {
// Cache is less than 3/4 full. Use it as-is.
}- 如果新的缓存占用大小
小于等于缓存容量的四分之三,则可以进行缓存流程
else {
// Cache is too full. Expand it.
cache->expand();
}- 如果缓存不为空,且缓存占用大小已经超过了容量的四分之三,则需要进行扩容。
bucket_t *bucket = cache->find(key, receiver);- 通过前面生成的
key在缓存中查找对应的bucket_t,也就是对应的方法实现。
if (bucket->key() == 0) cache->incrementOccupied();
bucket->set(key, imp);- 判断获取到的桶
bucket是否是新的桶,如果是的话,就在缓存里面增加一个占用大小。然后把key和imp放到桶里面。
cache_fill_nolock 的基本流程我们分析完了,这个方法主要针对的是没有缓存的情况。
但是这个方法里面的 cache->find 我们并不知道是怎么实现的,我们接着探索这个方法:
2.2 查找缓存策略
bucket_t * cache_t::find(cache_key_t k, id receiver)
{
assert(k != 0);
bucket_t *b = buckets();
mask_t m = mask();
mask_t begin = cache_hash(k, m);
mask_t i = begin;
do {
if (b[i].key() == 0 || b[i].key() == k) {
return &b[i];
}
} while ((i = cache_next(i, m)) != begin);
// hack
Class cls = (Class)((uintptr_t)this - offsetof(objc_class, cache));
cache_t::bad_cache(receiver, (SEL)k, cls);
}find 方法我们乍一看会发现有一个 do-while 循环,因为这个方法的作用是根据 key 查找 IMP,但需要注意的是,这里返回的并不是一个 IMP,而是 bucket_t 结构体指针。
- 通过
buckets()方法获取当前cache_t下所有的缓存桶。 - 通过
mask()方法获取当前cache_t的缓存大小减一的值mask_t。 - 然后把
mask_t的值作为循环的索引。 - 在
do-while循环里遍历整个bucket_t,如果key为 0,说明当前索引位置上还没有缓存过方法,则需要停止循环,返回当前位置上的bucket_t;如果key为要查询的k,说明缓存命中了,则直接返回结果。 - 这里的循环遍历是通过
cache_next方法实现的,这个方法内部就是当前下标i与mask_t的值进行与操作,来实现索引更新的。
三、cache_t 探索后的疑问点
整个 cache_t 的工作流程,简略描述如下:
- 当前查找的
IMP没有被缓存,调用cache_fill_nolock方法进行填充缓存。 -
当前查找的
IMP已经被缓存了,然后判断缓存容量是否已经达到3/4的临界点- 如果已经到了临界点,则需要进行扩容,扩容大小为原来缓存大小的 2 倍。扩容后处于效率的考虑,会清空之前的内容,然后把当前要查找的
IMP通过cache_fill_nolock方法缓存起来。 - 如果没有到临界点,那么直接返回找到的
IMP。
- 如果已经到了临界点,则需要进行扩容,扩容大小为原来缓存大小的 2 倍。扩容后处于效率的考虑,会清空之前的内容,然后把当前要查找的
我们梳理完 cache_t 的大致流程之后,我们还有一些遗留问题没有解决,接下来一一来解决一下。
3.1 mask 的作用
我们先回顾一下 mask 出现在了哪些地方:
setBucketsAndMask(newBuckets, newCapacity - 1);
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask)
{
mega_barrier();
_buckets = newBuckets;
mega_barrier();
_mask = newMask;
_occupied = 0;
}
mask_t cache_t::capacity()
{
return mask() ? mask()+1 : 0;
}首先,mask 是作为 cache_t 的属性存在的,它代表的是缓存容量的大小减一的值。这一点在 setBucketsAndMask 与 capacity 方法中可以得到证实。
cache_fill_nolock {
cache_key_t key = getKey(sel);
bucket_t *bucket = cache->find(key, receiver);
}
find {
// Class points to cache. SEL is key. Cache buckets store SEL+IMP.
// Caches are never built in the dyld shared cache.
static inline mask_t cache_hash(cache_key_t key, mask_t mask)
{
return (mask_t)(key & mask);
}
static inline mask_t cache_next(mask_t i, mask_t mask) {
return (i+1) & mask;
}
}根据上面的伪代码,cache_fill_nolock 方法里面,会先根据要查找的 sel 强转成 cache_key_t 结构,这是因为 sel 其实为方法名:
而经过强转之后为:

也就是说最后缓存的 key 其实是一个无符号长整型值,这样相对于直接拿字符串来作为键值,明显效率更高。
经过强转之后,把 key 传给 find 方法。然后会有一个 cache_hash 方法,其注释如下:
类指向缓存,SEL是键,buckets缓存存储的是SEL+IMP。
方法缓存永远不会存储在dyld共享缓存里面。
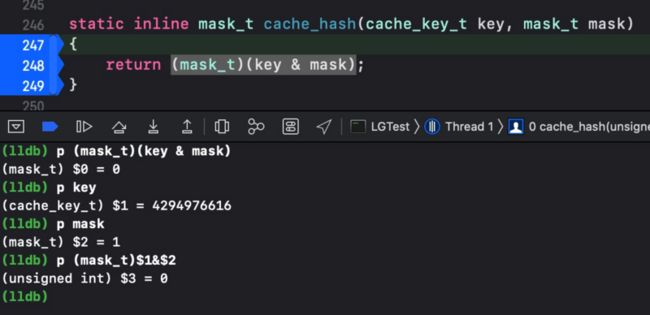
实际测试如上图所示,cache_hash 方法其实就是哈希算法,得到的是一个哈希值。拿到这个哈希值后就可以在哈希表中进行查询。在 find 方法中就是获得索引的起始值。

通过上图的测试我们可以得出这里是使用的 LRU 缓存算法。
LRU算法的全称是Least Recently Used,也就是最近最少使用策略。这个策略的核心思想就是先淘汰最近最少使用的内容。
3.2 capacity 的变化
capacity 的变化主要发生在扩容的时候,当缓存已经占满了四分之三的时候,会进行两倍原来缓存空间大小的扩容,这一步是为了避免哈希冲突。
3.3 为什么是在 3/4 时进行扩容
在哈希这种数据结构里面,有一个概念叫装载因子,装载因子是用来表示空位的多少。其公式为:
散列表的装载因子=填入表中的元素个数/散列表的长度装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
苹果这里设计的装载因子显然为 1 - 3/4 = 1/4 => 0.25 。
因为本质上方法缓存就是为了更快的执行效率,所以为了避免发生哈希冲突,在采用开放寻址法的前提下,尽可能小的装载因子可以提高散列表的性能。
/* Initial cache bucket count. INIT_CACHE_SIZE must be a power of two. */
enum {
INIT_CACHE_SIZE_LOG2 = 2,
INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2)
};
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);初始化的缓存大小是 1 左移 2,结果为 4。然后在 reallocate 方法进行一下缓存的重新开辟。这也就意味着初始的缓存空间大小为 4。
3.4 方法缓存是否有序
方法缓存是无序的,这是因为计算缓存下标是一个哈希算法:
static inline mask_t cache_hash(cache_key_t key, mask_t mask)
{
return (mask_t)(key & mask);
}通过 cache_hash 之后计算出来的下标并不是有序的,下标值取决于 key 和 mask 的值。
3.5 bucket 与 mask, capacity, sel, imp 的关系
一个类有一个属性 cache_t,而一个 cache_t 的 buckets 会有多个 bucket。一个 bucket 存储的是 imp 和 cache_key_t 。
mask 的值对于 bucket 来说,主要是用来在缓存查找时的哈希算法。
而 capacity 则可以获取到 cache_t 中 bucket 的数量。
sel 在缓存的时候是被强转成了 cache_key_t 的形式,更方便查询使用。imp 则是函数指针,也就是方法的具体实现,缓存的主要目的就是通过一系列策略让编译器更快的执行消息发送的逻辑。
四、总结
-
OC中实例方法缓存在类上面,类方法缓存在元类上面。 -
cache_t缓存会提前进行扩容防止溢出。 - 方法缓存是为了最大化的提高程序的执行效率。
- 苹果在方法缓存这里用的是
开放寻址法来解决哈希冲突。 - 通过
cache_t我们可以进一步延伸去探究objc_msgSend,因为查找方法缓存是属于objc_msgSend查找方法实现的快速流程。
我们下一篇将开始探索 iOS 中方法的底层原理,敬请期待~