附上链接:
凌风探梅的卷积神经网络(CNN)新手指南 http://blog.csdn.NET/real_myth/article/details/52273930;
深度学习笔记整理系列:http://blog.csdn.Net/zouxy09/article/details/8775360 ;(xy)
http://xiahouzuoxin.github.io/notes/html/深度卷积网络CNN与图像语义分割.html(佐鑫)
总结些心得,写一下认识。
1.深度学习的发展
BP浅层神经网络早在20世纪80年代末期就已掀起了基于统计模型的机器学习热潮,只是BP只有一个隐层,人们对于bp没有很完整的理论推导而且调参问题不少,这样深度神经网就被搁置了。相比而言,20世纪90年代,各种各样的浅层机器学习模型相继被提出,例如支撑向量机(SVM,Support Vector Machines)、 Boosting、最大熵方法(如LR,Logistic Regression)等。这些模型的结构基本上可以看成带有一层隐层节点(如SVM、Boosting),或没有隐层节点(如LR)。这些模型无论是在理论分析还是应用中都获得了巨大的成功。
直到2006年,加拿大多伦多大学教授、机器学习领域的泰斗Geoffrey Hinton和他的学生RuslanSalakhutdinov在《科学》上发表了一篇文章,开启了深度学习在学术界和工业界的浪潮。这篇文章有两个主要观点:1)多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;2)深度神经网络在训练上的难度,可以通过“逐层初始化”(layer-wise pre-training)来有效克服,在这篇文章中,逐层初始化是通过无监督学习实现的。(摘抄自xy哥哥那里,哈)
2012年神经网络又开始崭露头角,那一年Alex Krizhevskyj在ImageNet竞赛上(ImageNet可以算是竞赛计算机视觉领域一年一度的“奥运会”竞赛)将分类错误记录从26%降低到15%,这在当时是一个相当惊人的进步。从那时起许多公司开始将深度学习应用在他们的核心服务上,如Facebook将神经网络应用到他们的自动标注算法中,Google(谷歌)将其应用到图片搜索里,Amazon(亚马逊)将其应用到产品推荐服务,Pinterest将其应用到主页个性化信息流中,Instagram也将深度学习应用到它们的图像搜索架构中。
深度学习作为人工智能的一个方向,迅速风靡。
2011 Google Brain(内部共有10亿个节点,人脑中可是有150多亿个神经元)
2012 Google 实验室,百度研究院
2014 Facebook的DeepFace
2015 亚马逊发布了自己的机器学习平台;微软创分布式机器学习工具包
2016 谷歌人工智能算法 AlphaGo (1959年美国的塞缪尔(Samuel)就已经设计了一个下棋程序)
2.深度学习与特征提取
(1)深度学习是用来干啥的,可以理解为自动提取特征。
我理解的特征就是在各种算法中都需要做大量工作来得到训练样本的描述,并将此特征通过函数和层级结构等记录下来,将来进行测试比对。
(2)提取特征也是有故事的,表示最喜欢听故事了,(*^__^*) 嘻嘻……
据说是小猫头颅开了个小孔,然后不断在其眼前闪过不同类型、不同强弱的刺激。然后测试大脑视觉皮层细胞的响应,最后发现只有部分细胞响应。David Hubel 和Torsten Wiesel 发现了一种被称为“方向选择性细胞(Orientation Selective Cell)”的神经元细胞。当瞳孔发现了眼前的物体的边缘,而且这个边缘指向某个方向时,这种神经元细胞就会活跃。
这个启发了深度神经网络,比如我们要识别出图片中的小猫,并不需要像之前的全连接的结构,因为大量图片物体识别起来参数会相当多。我们在第一层卷积层得到的是各物体边缘特征,(接着pooling),第二个卷积层可能就得到边缘的组合或者小猫的部位碎片,...到最后就会得到诸如爪子呀,眼睛之类的高层特征啦。
所谓:仿视觉皮层(多层),局部特征组合与抽象。
高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。
3.CNN之所以能识别图像的直观理解
核心是卷积(滤波器的概念)。
如输入的是一个32×32×3的系列像素值,(不懂参见上一篇哈),滤波器相当于人的眼睛,来提取图像的底层特征,比如滤波器大小是5×5×3的,被这个小眼睛看到的地方称作接受场或者局部感受野,所以我们的这个小眼睛需要不断的移动,对应卷积下图。
这样进行相应卷积运算(点乘再相加)就得到了一个feature map。如你想的那样我们往往需要多个滤波器,来从不同视角看物体,得到多个feature map。那为什么这样就得到物体的底层特征了呢?比如说边缘特征?
滤波器着实神奇,其实你可以想象过滤器是矩阵。都是数字,然后和输入的局部像素值相乘相加得到最终的结果。如果过滤器中大的参数值刚好摆出某一个形状,而物体中刚好也有这样的形状的话,是不是更加强效果啦?看下图就立马明白:
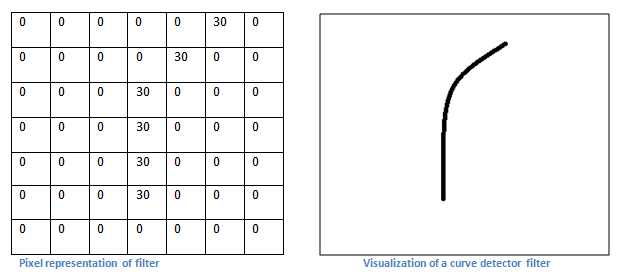
这是一个可以检测曲线的滤波器。突然想起之前学信号老见滤波器却从来不明白其中的道理,这下加深理解了,谢谢凌风探梅博主!
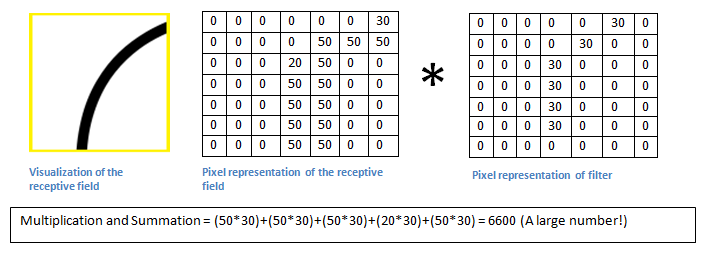
基本上在输入图像中,如果有一个形状是类似于这种滤波器的代表曲线,那么所有的乘积累加在一起会导致较大的值!现在让我们看看当我们移动我们的过滤器时会发生什么。可以看到结果值是0哦,为什么?还不明白么,因为耳朵的边缘和刚刚尾股部曲线太不同了。

这样的多个滤波器就可以在大量数据的训练下得到大量特征了不是。训练就是为了得到合适的滤波器的值,权值偏置等。自动进行特征学习就是这个道理。
4.CNN多层结构及实现技巧
![]()
(1)修正线性单元(ReLU)层
在每个卷积层后,习惯在其后马上添加一个非线性层(或激活层)。这一层的目的是将非线性引入系统,基本上是在卷积层进行线性运算(只是元素的乘法和累加)。在过去都是像tanh 或者sigmoid的线性算法,但研究人员发现ReLU层效果更好,因为网络训练速度能加快很多(因为计算效率)且精度没有显著差异。它也有助于缓解消失的梯度问题,这是因为网络训练较低层的速度非常缓慢,梯度通过不同的层级指数下降。ReLU层的采用的函数f(x)= max(0,x)所有值的输入量。基本上,这一层将所有的负激活变成了0。这一层提高了模型的非线性特性,且整体网络不影响卷积层的接受场。感兴趣的还可以参看深度学习之父Geoffrey Hinton的论文Geoffrey Hinton
(2)卷积和子采样pool过程:卷积过程包括:用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map了),然后加一个偏置bx,得到卷积层Cx。子采样过程包括:每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。
pool的作用:首先是参数或权重的量减少了75%,从而降低了计算成本。其次,控制过度拟合。
(3)还有步长stride滤波器移动时候需要,零填充(zero padding)为了卷积之后尺寸不变,降层(Dropout Layers)防止过拟合,网络层网络不太明白(滤波器是1*1*N的卷积层)...这些概念参见凌风探梅的文章。
(4)这个好有用:迁移学习(Transfer Learning):比如利用已经训练好的动物识别的程序与参数(冻结),只改变最后吼类别直接相关的层,拿自己的数据微调,然后效果也不错。区别更多在于高层特征的道理~
5.分类,定位,检测,分割 ,图像级与像素级语义
图像分类任务是将输入图像识别并输入一系列的图像类别的过程,然而当我们将对象定位作为任务时,我们的工作不仅是得到一个分类标签,另外还需要划定一个对象在图像中的范围。
同样还有对象检测(分类与定位结合)任务,需要将图像中所有对象进行图像定位任务。因此,在图像中将会有多个划定范围还有多个分类标签。
最后,还有对象分割任务,对象分割任务指的是输出一个类的标签,以及输入图像中的每一个对象的轮廓。
图像级与像素级语义: 简单理解了一下,像素级分两类:语义级图像分割和边缘检测。主要是语义相同的像素被分割在同一区域。
super pixel:比如识别人像各区域属于人体哪个部位。