干货!华为AutoML助力AI开发效率提升攻略
欢
迎
光
临
~

你是不是还在为掌握的AI算法少而烦恼?
你是不是还在为选择某个处理方法而犹豫不决?
你是不是还在为调参四处寻求帮助?
你是不是因为超参优化的龟速而愤慨?
你是不是还在为持续优化某个模型而感到寸步难行?
从现在开始,有了华为NAIE AutoML,这些都不是事啦!
为解决AI工程师在开发AI应用场景所遇到的问题,NAIE平台落地AutoML框架(工具)来辅助大家更高效、更迅速解决AI开发问题。
Follow me,看我们如何用NAIE AutoML逐个击破开发难题!
一个完整的机器学习应用开发主要包括数据预处理、特征工程、模型选择和超参优化这些关键模块,每个关键模块里面又有很多子模块,如下图所示。

而每个模块中又有很多不同的方法。针对特定的数据集,选取每个子模块的方法并按照一定的逻辑拼接起来,就构成了一个pipeLine,运行整个pipeline即可得到一个模型。但是这样的 pipeline 的量级大多在百万级以上,我们该如何从这些pipeline中选择最优的呢?
在AI场景的预研阶段,算法工程师会有很多的想法。针对每个想法,需要快速验证可行性。你是不是因为不了解某个算法而不断光顾各大论坛,去了解算法的调用和调参技巧?你是不是经历过“刚学懂某个算法,其他团队都已经落地了”这种尴尬局面。你是不是经历过“1000次的超参迭代需要3天才能知道结果”?我们无法忍受算法入门的高门槛、调参的炼金术和迭代的漫长等待。对于一个刚入门的AI算法工程师,如何进行快速验证AI算法的可行性是一个非常迫切的问题。
1.3 如何进行持续的调优学习?
在AI的调优中,由于有限的时间和算力,我们是无法遍历所有可能的调优方式。AI工程师通常会根据经验设定少数几个pipeline,根据pipeline的运行结果,再根据经验来调整pipeline中各个模块的方法或超参。这样的人工调整操作费时费力,通常一天只能进行十几次的尝试。对于海量的搜索空间来说,基本是大海捞针。再加上专家的精力和时间有限,因此,对一个特定任务进行持续的调优学习是非常大的挑战。
在AI应用开发的过程中,你是不是偶尔调到一个很好的模型沾沾自喜,但是给领导演示时结果却不能复现而尴尬万分。为了避免这种尴尬的局面,我们需要在每次的试验中做到结果的可重复。一般情况下,我们会设定随机种子来确定。设定了随机种子后,结果一定是可以复现的吗?不是的,有些算法是多线程的,如lightgbm,同时线程的个数也会影响算法的结果。另外,交叉验证数据的划分、基于模型的超参选择等均具有随机性。如何做到结果的可复现,对AI工程师也是一个比较大的挑战。
那么面对这些困难和挑战,华为NAIE AutoML是如何逐个攻破的呢?
AutoML(Automatic Machine Learning)是一个自动化机器学习分析系统,可以让普通的开发人员、业务人员参与机器学习建模,同时能把数据科学家从繁琐、反复的算法调优中解放出来,降低机器学习的使用门槛,提升工作效率。究其根本AutoML能有如此功效,主要是它把机器学习中的数据预处理、特征工程、算法模型、集成学习等经验性工作自动化,达到提升开发效率的结果。
下面我们将介绍NAIE平台AutoML技术。
NAIE平台AutoML采用业界经典的AutoML框架,主要包括数据预处理、特征工程、算法模型、超参优化、集成学习五个模块,其中,超参优化模块是对数据预处理、特征工程、算法模型构成的pipeline进行超参寻优。主要框架图如下:
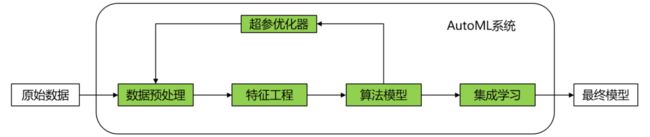
华为NAIE AutoML的设计主要考虑到以下两个方面:
1. 对于普通AI开发者,可以调用NAIE AutoML来处理大部分业务场景问题;
2. 对于专业AI开发者,NAIE AutoML提供高可扩展的接口供用户针对业务场景自定义相关模块来解决相应的业务问题。
在AI应用的实战中,需要不断地尝试各种策略,如增加优化的迭代次数、更换评估指标等。NAIE平台AutoML框架提供基于Pipeline的超参优化、持续的超参优化、分布式超参优化加速、可扩展、可复现等特性,使得用户能够快速试验超大的超参迭代次数、自定义针对业务问题的算法模块、复现已有的探索结果,显著提高用户的开发效率。
1)支持pipeline 的超参寻优
NAIE AutoML不仅支持由数据预处理、特征工程和模型所构成pipeline的超参优化,同时也支持针对模型的超参优化,仅需要把数据预处理和特征工程部分关闭即可。
2)支持分布式并行加速
业界在使用AutoML技术的过程中,由于参数空间非常大,一般地,需要将迭代次数设置为2000次或更多。单个节点,运行2000次超参,非常耗时。NAIE 平台AutoML可以采用多节点并行技术,通过Master-Worker机制大大缩短了时间。

图:分布式实现示意图
3)支持超参的持续学习
在实际的场景中,我们并不清楚终止的条件对不对,因此,我们只能在测试数据上不断的验证。当验证的效果随着迭代次数显著提升时,用户仍然想迭代更多的次数。为了节省资源和时间,NAIE AutoML实现了增量的超参优化,且能够做到100+50=150,即第一次运行迭代100次,基于第一次任务再增量迭代50次,最终得到的结果与单次运行迭代150次的结果保持一致。
不同数据挖掘算法都有对应的适用条件,并非都能适用所有场景及数据,NAIE AutoML通过集成学习技术实现对多个算法进行融合得到最佳的模型,让最终模型更加鲁棒 (robust)。具体实现流程如下:
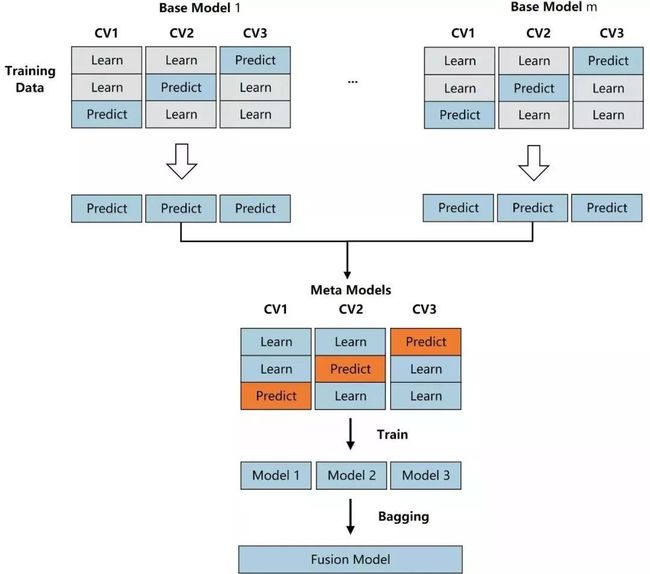 2.1.3 可扩展
2.1.3 可扩展
1. 自定义算法模型
一般AutoML会针对不同的任务提供了内置的算法模型,内置算法支持指定某几种算法来参与建模。然而几种内置算法无法覆盖所有的应用场景需求,因此NAIE AutoML提供了自定义算法模型能力,用户可以根据框架规范开发相应的接口来实现自定义算法模型。
2.自定义评估指标
AutoML针对不同的任务,提供了内置的评估指标,如对于分类问题,提供precision、recall、f1等评估指标。但是很多业务场景问题,往往这些评估指标是不够的,如设备故障检测场景中,业务指标是满足误报率(False Alarm Rate) <= 0.1%情况下, 查全率(Fault Detection Rate) 要尽量高。类似设备故障检测这样的场景,需要根据业务问题来设自定义置评估指标,NAIE AutoML提供自定义评估指标接口。
3. 自定义交叉验证
AutoML中内置了交叉验证,但内置交叉验证无法覆盖所有用户的需求。因此,NAIE AutoML也提供了自定义交叉验证接口。
在AutoML中,超参的选取、代理模型的生成、模型的训练等均受到随机种子的影响。NAIE AutoML将所有涉及随机的模块,采用统一的随机种子参数来控制。除此之外,当设定随机种子时,我们会自动把影响算法运行结果的线程数设置为1。这样便使得NAIE AutoML试验具备可重复性,即相同的AutoML配置,在不同的时间点运行,结果是相同的。
下面我们以“设备故障检测场景”为案例给大家介绍NAIE AutoML的具体应用效果。
网络设备故障经常发生,且在故障发生后才感知,极大影响运维效率和成本。传统的方法是当故障出现后,需要投入大量人力和物力去定位故障、恢复业务。
如何使用AI技术来提前预测故障发生的时间点,提前采取措施?针对这一业务问题,业务部门提出以下业务目标:在FAR<=0.1% 下,FDR尽量大,其中,
简而言之就是,在保证低误报率的情形下,尽量不要漏掉故障。
对于设备故障检测应用,AI算法里面是一个二分类问题,把故障情况看作是正样本,把其他情况看作是负样本,则业务指标FDR与FAR对应为二分类中ROC曲线中的 True Positive Rate与False Positive Rate,见下图。
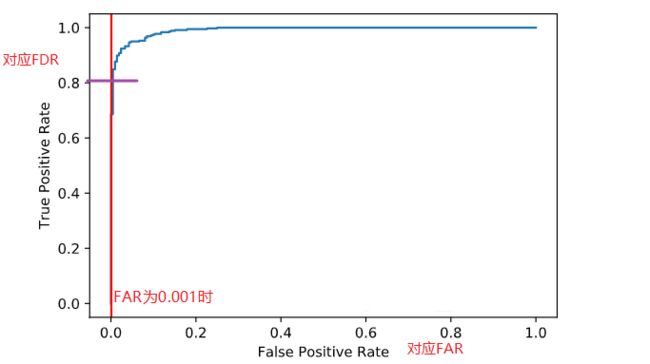
图:业务目标FDR与FAR与ROC曲线的对应关系
根据上图可以得到业务目标的表达式,代码如下:
from sklearn.metrics import roc_curve
def fdr_score(y_true, y_proba):
"""
对模型预测概率与真实的标签进行评分
FAR、FDR分别为ROC图中的fpr、tpr
Parameters
__________
y_true : numpy.array
测试数据的真实标签,值为1或0
y_proba : numpy.array
模型对类别1的预测概率,值为0-1之间的浮点数
Return
_______
max_tpr: float
当误报率FAR<0.1%时,检出率FDR的最大值
"""
fpr, tpr, _ = roc_curve(y_true, y_proba)
max_tpr = tpr[np.where(fpr < 0.001)][-1]
return max_tpr
3.3.1 设备故障检测场景的特殊性
设备故障检测场景的业务目标跟分类问题中的 precision、recall、f1等分类评估指标不同,是根据业务问题得到的。为了保证超参优化的目标与业务目标是一致的,可以使用NAIE AutoML提供的注册自定义评估指标来实现。
3.3.2 极简代码调用
调用步骤:
Step1:初始化NAIE AutoML类
Step2:注册自定义评估指标 fdr_score
Step3: 进行训练
代码如下:
from naie.automl import VegaAutoML
# Step1:初始化VegaAutoML
automl = VegaAutoML(model_type="classifier",
target_column="failure",
ignored_columns=["disk_sn"],
train_data_reference=get_data_reference(dataset="data", dataset_entity="train"),
optimization_method="SMAC",
included_models=['lightgbm'],
n_folds=5,
metrics="fdr",
workers=5,
max_trial_number=1000,
random_state=1)
# Step2:注册自定义评估指标(fdr_score)
automl.register_metric_evaluator("fdr", fdr_score)
# Step3: 开始训练
automl.train()
参数简要说明:
1. optimization_method:超参优化方法,当前支持网格搜索、随机搜索和SMAC优化算法
2. included_models:默认为None, 表示搜索所有内置的模型。通过该配置参数,实现只对部分模型进行搜索。
3. metrics:评估指标,可以是内置的评估指标,也可以是自定义的评估指标;
4. workers: 并行数,通过该配置参数,实现分布式加速;
5. random_state: 随机种子,指定该配置,可以实现AutoML过程的可重复性。
3.3.3 效果
经过简单的几行代码即可实现在设备故障检测场景上的建模。试验展示,经过1000次的迭代即可达到专家经验的水平。
华为开发者大会HDC.Cloud是华为面向ICT(信息与通信)领域全球开发者的年度顶级旗舰活动。大会旨在搭建一个全球性的交流和实践平台,开放华为30年积累的ICT技术和能力,以“鲲鹏+昇腾”硬核双引擎,为开发者提供澎湃动力,改变世界,变不可能为可能。我们期待与你共创计算新时代,在一起,梦飞扬!
关注人工智能园地公众号,点击【菜单栏】-【开发者】- HDC,了解更多网络人工智能(NAIE)展区详情。

人工智能园地,力求打造运营商领域第一的人工智能交流平台,促进华为iMaster NAIE理念在业界(尤其通信行业)形成影响力!



