测试环境和生产环境结构是一样的:
国信的容器云、redis、mysql双主和集成的mysql主从用的是一个集群,redis、mysql双主、mysql主从用的是一个broker一个catalog,容器云是一个独立的,租户从云门户同步过来是一个租户一个namespace,不知道容器云和catalog那个建namespace快,慢的发现已经有namespace就会冲突报错,需要租户同步进去时先判断一下,报错如下:
租户底层资源初始化失败
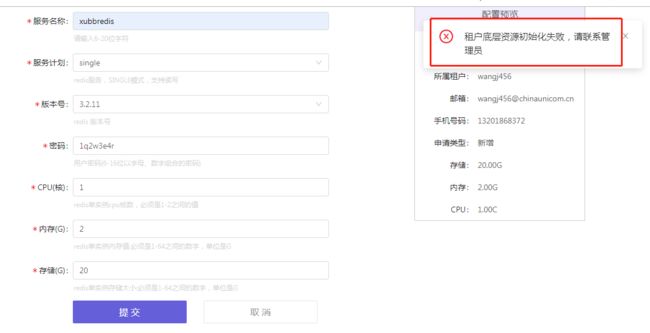
生产环境:
10.168.26.10生产kubectl所在服务器mcloud密码2w#E4r%T6y&Uqwas
查看K8s节点状态:kubectl get node
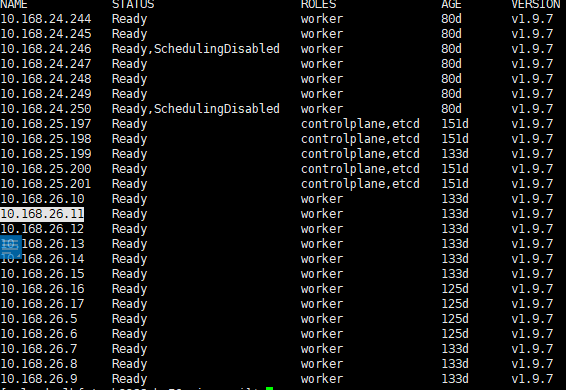
访问dashboard地址:
https://10.168.26.9:9090
管理员令牌:
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWd2dHJiIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI2MGY3M2UwNy00NTYzLTExZTktOWQxYy02YzkyYmZjNDU0ODQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.M-59rlfjOYGr83Px1qX2PL-onfA8YLEFqLXnspvLcoKysuZJuLimjaY0To2o7JyIvOFtMPrpJAZ09K2VOfit6omlXskbgKhCrxqVl9UKFwH8_rHpnK5Hc_7_AXme8H-kpyZKtRsrHhVvH-aYxIxh7TpNkjA_qDdWFjXX2VUQn9zVpt0sx0wtwC2ODdvPuqSIgpF-UDD931gB9Jn1Ep0GJ_Wez6HdSjSJtOdHbSclfEzQjveZB0Yi2SIOtMkqd3rl2NuEZVFr5C-EdlWW9oXsfzZj2fdCaUmP2v66iRzdKoKOgMiiqprfcFSOq2B3TFSxv7zzHm6sdBiZMOoGoFUZrg
用户令牌
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJvcmRpbmFyeS11c2VyLXRva2VuLXRrNnh3Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6Im9yZGluYXJ5LXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI2NGQ4MGRhYi00NTYzLTExZTktOWQxYy02YzkyYmZjNDU0ODQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06b3JkaW5hcnktdXNlciJ9.z5ZSLL1SANmvtNuw2n8EBwYSy3iyGbVcxgJTm-WYIMG1E5i81tbxiWvLHMxBReTB9inqOzXP_nkTpgyUenxjnbb8fLsCTMKSyNA3A7G-diaOG0Blw58L1b1IceJ-r9YRrRSsXLse16YgEbI-r0CpO4fXdPvZPmL8rK_cvc1GrVn1uwN1FadBuewXLHpqMnSrQB5O90HCNrmFRVAJHWoL2LJisYuJUGgBWfR7AaevHED1H9HbxLous_MPS6muwiSdo8lzawiY2PeJoN103qgRmtLWhfl4cU02c055zoTVuDx2M-fDnwiASIGbaI_x9gFwiJIVRd3sHGKaqtrMIqEXlQ
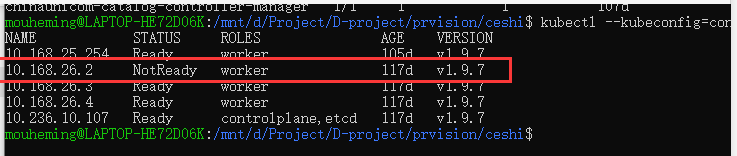
测试环境:
10.168.26.2\3\4 mcloud 2w#E4r%T6y&Uqwas
lvm是在每个node节点上装,master节点不安装(创建mysql主从的随机分配到node上),
10.168.26.2这台机器就没有装lvm,所以调度不上,是有vg,但是没有装flexvolume插件,vg已经创建好了,装一下插件就可以了。一般有这个目录就是装了的,没有这个目录就是没装

查看k8s集群节点状态:
1.查看mysql实例状态;都处于running
2.访问dashboard确认从pod本地连接mysql可行
http://10.236.0.79:8088/CUDOP/D-DCOS/broker/self-broker/backend/docs/blob/master/%E8%BF%90%E7%BB%B4%E6%96%87%E6%A1%A3/%E8%BF%90%E7%BB%B4%E6%89%8B%E5%86%8C-D%E5%9F%9F%E8%83%BD%E5%8A%9B%E5%BC%80%E6%94%BE%E5%B9%B3%E5%8F%B0.md
运维手册-D域能力开放平台
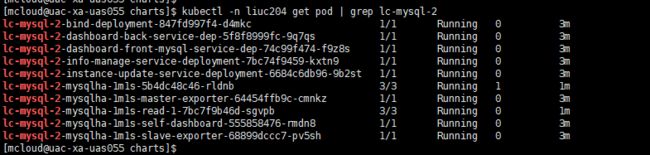
1、mysqlha-1m1s拉起异常
问题描述:在内部开发环境的liuc204命名空间下,尝试拉起一个名为ha1m1s-lc的mysqlha-1m1s实例,该实例长时间未能创建成功。
错误定位办法:
登录配有该环境的kubectl的服务器(10.236.5.12),通过kubectl命令查看该实例。发现该实例的ha1m1s-lc-mysqlha-1m1s-self-dashboard长时间处于init状态。
kubectl -n liuc204 get pod | grep ha1m1s-lc
kubectl -n nium get pod -o wide| grep i2292
kubectl delete pod -n nium i2295-mysqlha-1m1s-master-exporter-65bd8d87ff-fztd8
helm list --all | 实例名
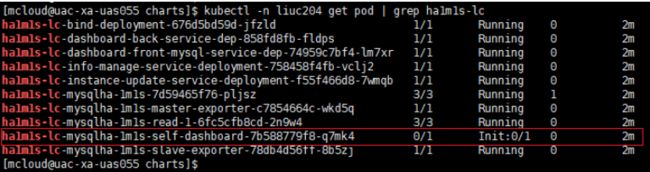
2、通过kubectl describe命令可以查看到该pod的初始化容器和容器。如下图所示,该pod有一个名为bingding-node的初始化容器,以及名为self-dashboard的普通容器。
kubectl -n liuc204 describe pod ha1m1s-lc-mysqlha-1m1s-self-dashboard-7b588779f8-q7mk4
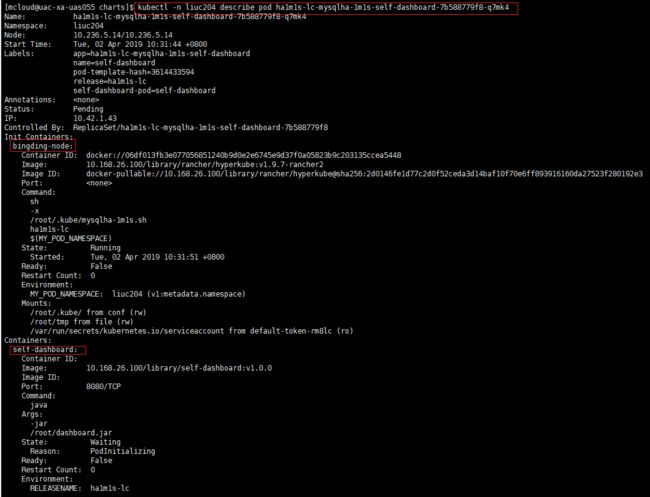
并且可以看到该pod并没有异常事件。
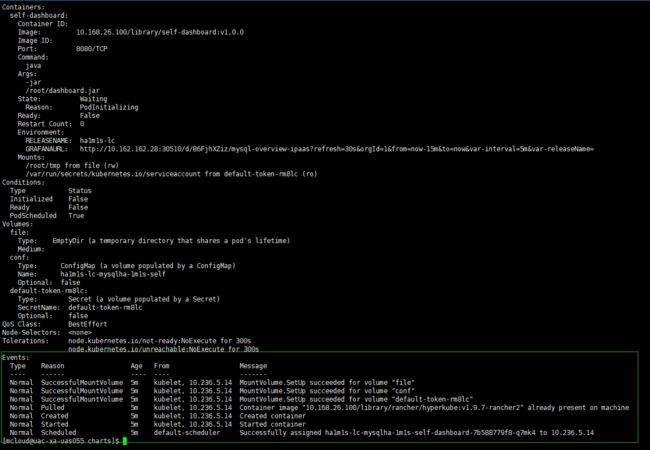
3、通过kubectl logs命令查看self-dashboard容器日志和bingding-node的日志,发现bingding-node的日志中有连接被拒绝的异常。
kubectl -n liuc204 logs ha1m1s-lc-mysqlha-1m1s-self-dashboard-7b588779f8-q7mk4 -c self-dashboard
kubectl -n liuc204 logs ha1m1s-lc-mysqlha-1m1s-self-dashboard-7b588779f8-q7mk4 -c bingding-node
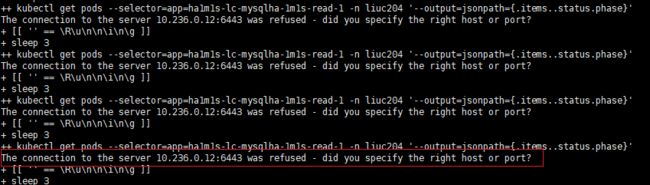
4、6443端口是kube-apiserver的端口,但是10.236.0.12并不是集群中kube-apiserver的IP,说明配置kube-apiserver出现了错误。ha1m1s-lc-mysqlha-1m1s-self-dashboard是在configmap-self.yaml中配置kube-apiserver的,所以检查chart包中的templates/configmap-self.yaml。
5、检查发现确实是configmap-self.yaml配置错误。
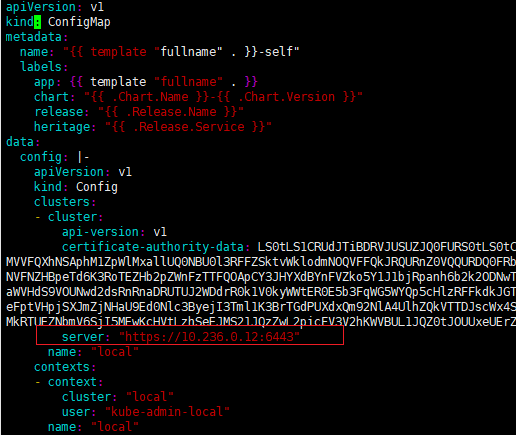
原因简介:经过错误定位判断,是chart包中的configmap-self.yaml中的kubeconfig配置错误。
解决办法:
(1)登录chart包所在服务器(10.236.5.12)的对应路径/home/mcloud/developer/liuc204/charts下,修改mysqlha-1m1s中的templates/configmap-self.yaml文件。
(2)修改configmap-self.yaml中关于kubeconfig的配置。将图中红框内容替换为当前集群的kubeconfig。

(3)使用helm package命令重新打包,并将新生成的chart包mysqlha-1m1s-0.3.10.tgz上传至harbor中。
helm package mysqlha-1m1s
(4)通过kubectl删除后端服务的pod
kubectl -n liuc204 delete pod self-backend-service-dep-lc-6c7bd5b686-zqzrh
检验方法:
在内部开发环境重新拉起一个mysqlha-1m1s的实例并且拉起成功,则表明问题维护成功。如图所示。
二、服务长时间未拉起(mysql超过5分钟,redis超过3分钟)
问题描述:生产环境下,尝试拉起一个名为i1902的mysqlha-1m1s实例,该实例长时间未能创建成功。
服务负责人:秦英瑜
错误定位办法:
(1)查询backend所在pod
kubectl get pod -n d-cmp | grep backend
(2)查看backend service日志
kubectl logs -f self-backend-service-dep-76d5b8699-7g849
(3)查找拉起失败的实例对应编号(使用ftp的搜索功能),若查不到对应请求,则直接将错误报送至service broker(由山分负责)
(4)若backend收到请求,且有报错信息,可根据报错信息排查问题,下文中异常情况1,2,3是可能出现的报错信息
(5)若backend收到请求,但并没有任何报错信息,则可能是异常情况4
异常情况1: chart包异常
provision:找不到chart包
原因简介:可能是backend service中配置的chart包仓库地址有误
解决办法:
查看/home/mcloud/backend-k8s-d-cmp/deployment.yaml文件
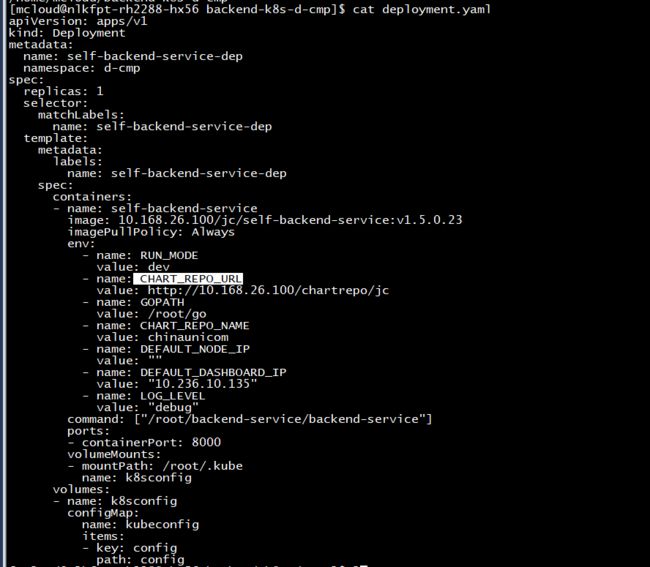
进入 CHART_REPO_URL对应仓库地址查看是否有对应镜像(所需镜像的版本可根据报错信息查看)
异常情况2 绑定异常————status:400
bind:json解析异常
原因简介:可能是broker传参时,参数的json不规范或不符合backend service所定义的参数类型(此种情况一般出现于联调阶段,手动调用接口传参时导致参数异常情况)
解决办法:
检查传参内容的json格式是否正确;对照backend service接口文档中的参数类型,检查传参类型是否正确
异常情况3 绑定异常————status:409
bind:重复绑定(解绑)
原因简介:可能由于某种原因,service broker反复调用backend service的绑定(解绑)接口导致(此种情况一般出现于联调阶段,service broker反复调用绑定接口,可请山分协助定位此问题)
异常情况4 磁盘空间不足
后端日志没有任何报错,但查询的实例状态始终是in progress状态(调用get status查询实例接口返回的查询结果)
原因简介:可能是分配主机的磁盘空间不足了
解决办法:
查看该实例所对应的所有pod
kubectl get pod -n demotenant | grep i1009 (i1009是实例名称)

如有某一个pod始终为init状态,则查看该pod的拉起日志
kubectl describe pod -n demotenant i1902-mysqlha-1m2s-master-exporter-55c7dd6765-jg78s
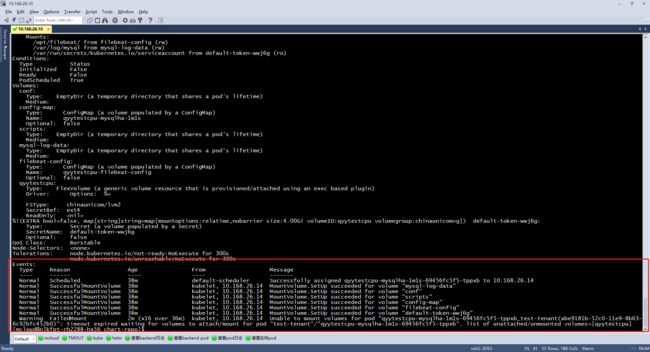
此时可以注意到最后一条事件(event)为FaildMount日志信息为:
Unable to mount volumes for pod "qyytestcpu-mysqlha-1m1s-69456fc5f5-tppxb_test-tenant(abe9181b-52c0-11e9-8b63-6c92bfc452b0)": timeout expired waiting for volumes to attach/mount for pod "test-tenant"/"qyytestcpu-mysqlha-1m1s-69456fc5f5-tppxb". list of unattached/unmounted volumes=[qyytestcpu]
由该日志信息可以初步判断为集群磁盘空间不足,清理集群的方法可参考lv操作手册
检验方法:
集群清理后重新拉起一个mysqlha-1m1s的实例,若能拉起成功,则表明问题维护成功。如图所示。
三、dashboard打开异常
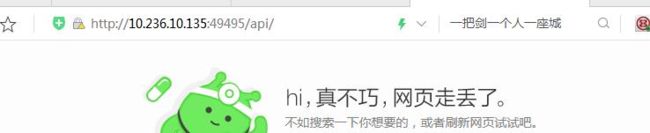
问题描述:生产环境下,拉起一个名为i1902的mysqlha-1m1s实例,实例的dashboard无法正常访问。
错误定位办法:
1.查询实例所在主机
kubectl get pods -n uni018 -o wide | grep i489

2.查询实例前端端口号
get svc -n uni018 | grep i489

3.访问前端地址http://10.168.26.7:49495/api可以看到浏览器是可以正常访问的(由于需要单点登录所以会跳转到登录页面,但是出现了页面就说明在集群内打开dashboard页面是没有问题的)

此时可以排除dashbard本身的问题,推测可能是F5(负载均衡)出现了问题,可以联系相关负责人定位问题
解决办法:当dashboard打不开时,除了定位问题以外,应第一时间给用户提供访问地址及账号密码
1.访问地址查询方法
查询实例所在主机kubectl get pods -n uni018 -o wide | grep i489

注:主节点为i489-mysqlha-1m1s所对应的ip地址
从节点为i489-mysqlha-1m1s-read1所对应的ip地址查询实例前端端口号get svc -n uni018 | grep i489

注:主节点为i489-mysqlha-1m1s所对应的端口地址
从节点为i489-mysqlha-1m1s-read1所对应的端口地址
2.账户名密码查询方法
kubectl get secret -n uni018 | grep i489
kubectl get secret -n uni018 i489-mysqlha-1m1s -o json
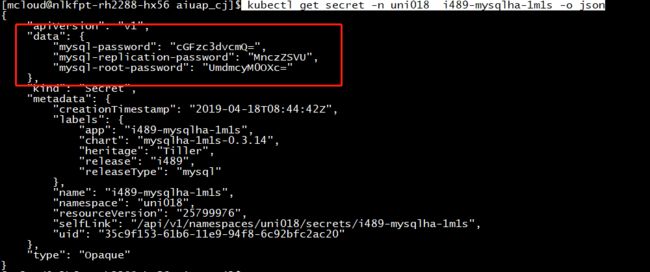
此为base64的密码 ,需要进行转换
转换指令:
echo "cGFzc3dvcmQ=" | base64 --decode
kubectl get pod -n xiying5 -o wide 查看主从状态以及在哪台机子上,不知道命名空间时
$ kubectl get pods --all-namespaces | grep 实例名 #列出所有namespace中的pod,也可以是services、deployment等
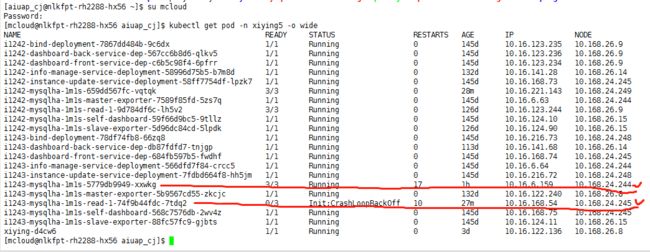
然后ssh登录到机子上ssh [email protected],看容器:docker ps -a | grep 实例名
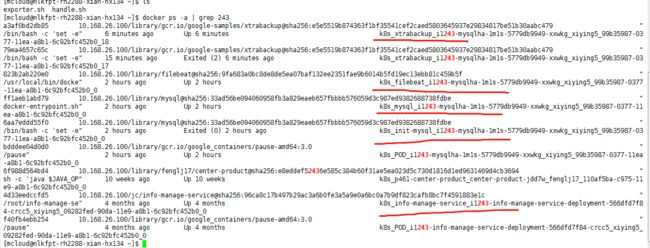
mysql\xbackup\filebeat他们三个共享存储,看mysql的错误日志和删除mysql的二进制日志,mysql容器没起来没法进去看或删时(k8s的dashboard容器组显示的日志是起来后报的,没起来是没有日志的),可以进filebeat和xbackup容器里面进行查看和删除,mysql错误日志/var/log/mysql/error.log ,mysql二进制日志在xbackup容器中的/var/lib/mysql目录下
进去容器:docker exec -it 283372f73fd8 bash
docker exec -it 容器id bash
接下来操作和在虚拟机上操作方法是一样的。
k8s的dashboard的配置字典是配置文件信息
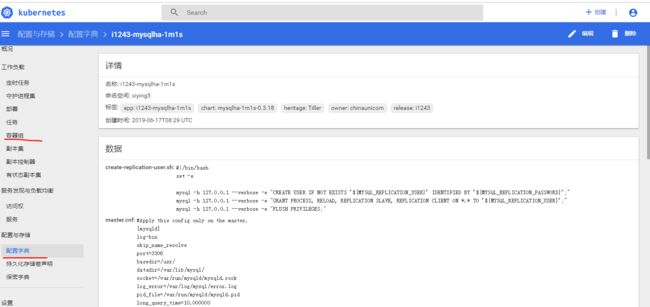
集群里任何ip加上此实例前端服务端口查看mysql dashboard
http://10.236.10.135:50407/
kubectl get svc -n xiying5 | grep 243
kubectl get svc -n xiying5 | grep 实例名
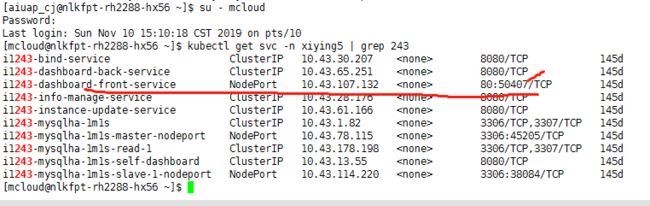
查看所有命名空间