
幻灯片1.JPG

幻灯片2.JPG

幻灯片3.JPG

幻灯片4.JPG

幻灯片5.JPG
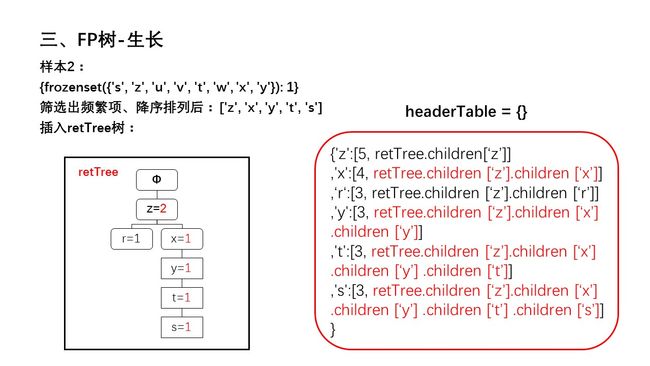
幻灯片6.JPG
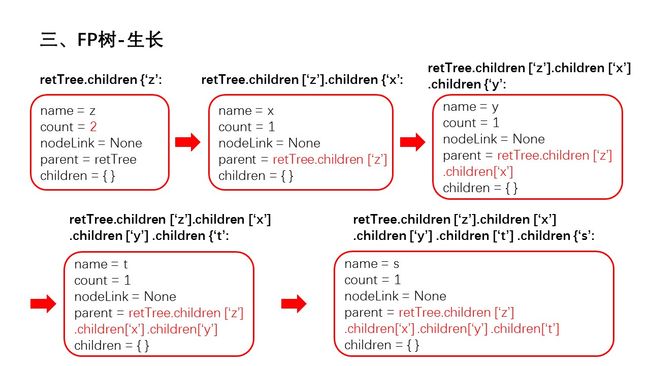
幻灯片7.JPG

幻灯片8.JPG

幻灯片9.JPG
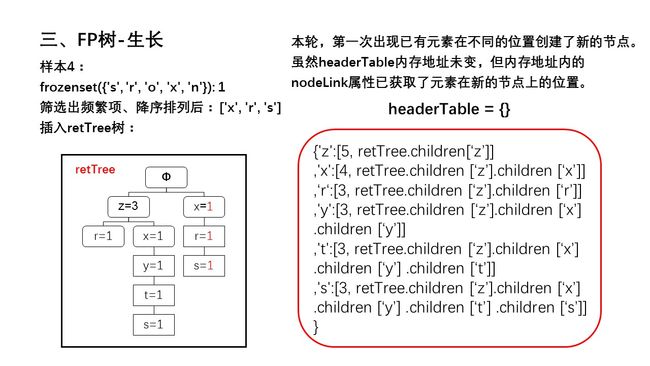
幻灯片10.JPG

幻灯片11.JPG
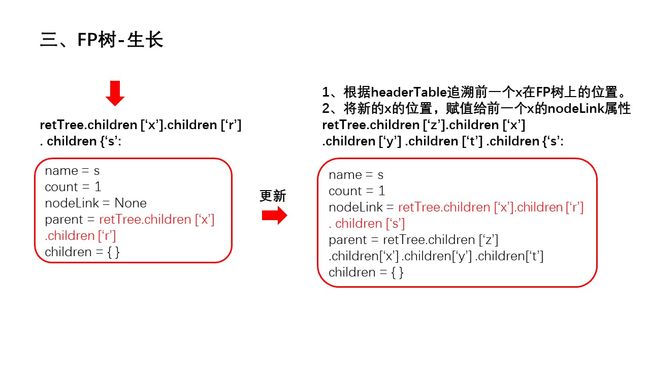
幻灯片12.JPG
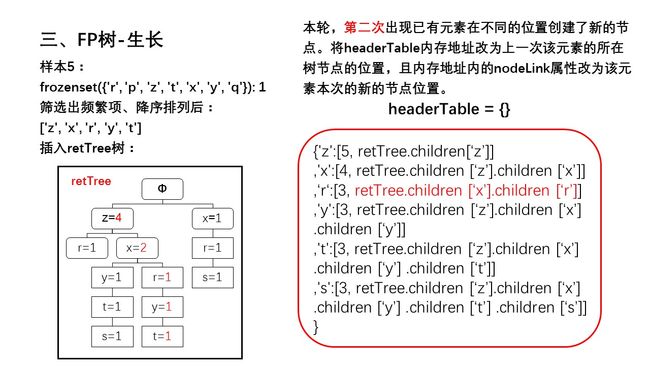
幻灯片13.JPG

幻灯片14.JPG
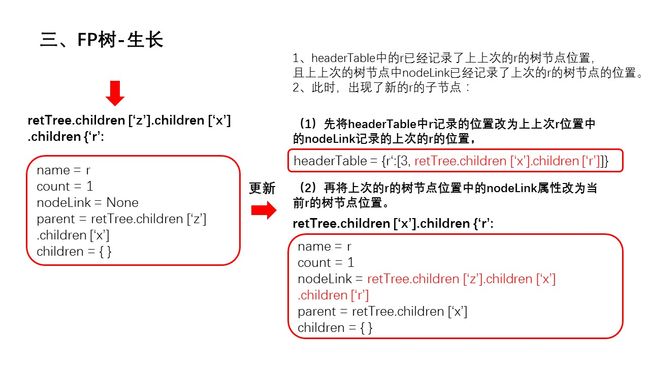
幻灯片15.JPG

幻灯片16.JPG
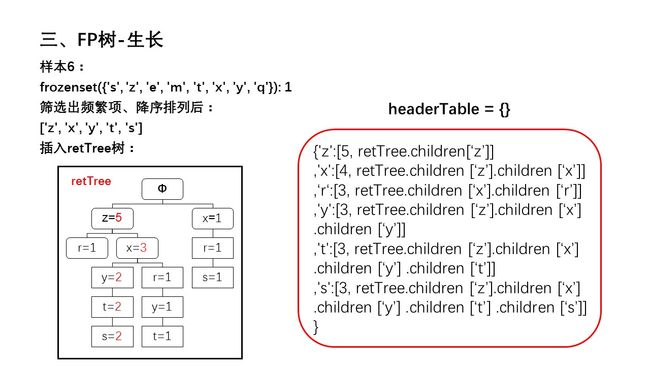
幻灯片17.JPG
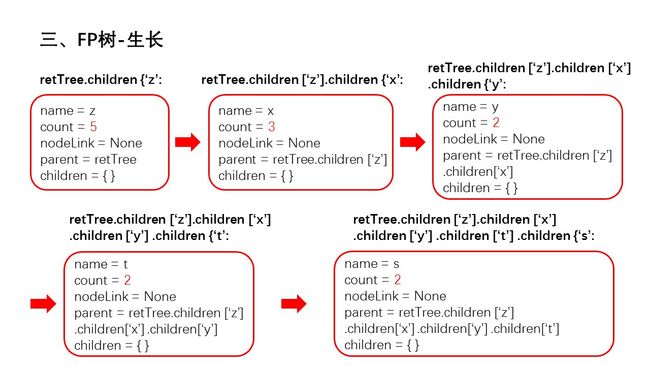
幻灯片18.JPG

幻灯片19.JPG
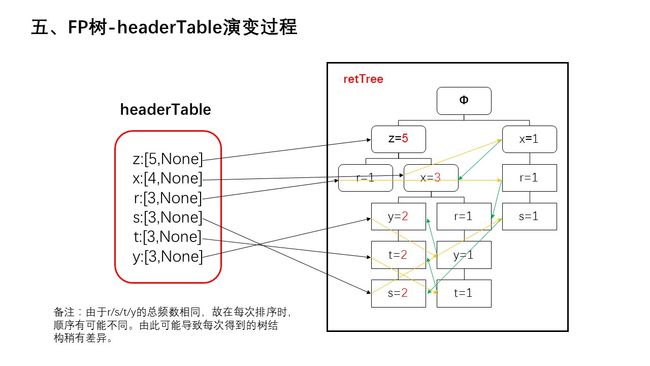
幻灯片20.JPG
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Leslie Dang
class treeNode():
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None # 存储元素下一次的树节点内存地址(同一个元素的节点链)
self.parent = parentNode # 存储元素的母节点的内存地址。(一颗树各子节点的链)
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=0):
# 用于将树以文本的形式展示
# 对构件树虽不是必要的,但是对于调试非常有用
print('|'+'- ' * ind, self.name, ':', self.count) # ' ' * ind用于缩进,表达树结构
for child in self.children.values():
child.disp(ind + 1)
def createTree(dataSet, minSup=1):
"""
创建FP树
:param dataSet: 样本数据,必须为dict型数据
:param minSup: 频繁项的最小频数(即:最小支持度)
:return: 返回创建的树、头指针表
"""
# 第一次遍历所有数据集,汇总每个元素的频数,得到headerTable头指针表
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 删除不满足最小支持度的项
# for k in headerTable.keys(): 将iteration转为list格式。
for k in list(headerTable.keys()):
if headerTable[k] < minSup:
del (headerTable[k])
# 得到频繁项元素集合
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0: return None, None
# 扩展headerTable,用于将来存放元素在树上的节点位置信息
for k in headerTable:
headerTable[k] = [headerTable[k], None]
# 创建FP树的树桩
retTree = treeNode('Null Set', 1, None)
# 第二次开始遍历数据集,创建FP-Growth树
for tranSet, count in dataSet.items():
# 汇总单个样本数据集中的频繁项的频数
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0] # headerTable = {'元素':[count,None]...}
# 当样本中的频繁项不为零时:
if len(localD) > 0:
# 对样本数据的频繁项,降序排列之后,获取它们的keys(这里的v[0],即元素名)
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
print('单个样本频繁项降序元素集合: orderedItems = ',orderedItems)
# 将单个样本数据集的频繁项,带入retTree进行树的扩展
updateTree(orderedItems, retTree, headerTable, count)
print('*****************************')
retTree.disp()
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
"""
对inTree树进行扩展(inTree不一定是retTree)
:param items: 频繁项元素列表
:param inTree: 本次扩展的母节点
:param headerTable: 头指针表
:param count: 相同样本数据集的个数
:return:
"""
# 检查样本频繁项数据集的第一项是否是inTree树的子节点
if items[0] in inTree.children:
# 如果是inTree树的子节点,则直接将样本频繁项数据集的第一项的频数,加到该子节点上
inTree.children[items[0]].inc(count)
# 第一个元素不是子节点时,创建新的子节点。
else:
inTree.children[items[0]] = treeNode(items[0], count, inTree)
# 头指针表中,第2项为空时,即该元素是第一次插入FP数,headerTable中还没有节点位置记录
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = inTree.children[items[0]]
# 将该元素第一次的节点位置,赋值给headerTable,在None处将该元素所在节点的内存地址存下来。
else:
# 如果headerTable已经存有地址了,则更新headerTable中的地址:
# headerTable[items[0]][1] :元素前一次的在FP树上的内存地址
# inTree.children[items[0]]:元素本次的在FP树上的内存地址
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
# 一个元素处理完毕后,检查样本频繁项集中,是否还有其它元素,有,则继续迭代处理
if len(items) > 1:
# !!!注意!!!样本集中后面的元素,是以样本集第一个元素的节点为根节点的,且前一个元素的节点是后一个元素的母节点。
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode):
"""
更新headerTable,使headerTable保存的是该元素倒数第二个子节点的内存地址,
且该节点的nodeLink属性保存了该元素最末端的子节点的位置。
:param nodeToTest:元素前一次的在FP树上的内存地址(前一次的地址被存放在HeaderTable中相应元素的位置上)
:param targetNode:元素本次的在FP树上的内存地址
:return:
"""
# 当headerTable中记录的上上次的元素所在的子节点已经记录了上次元素子节点的内存地址时:
while (nodeToTest.nodeLink != None):
# 将headerTable保存的地址改为该元素上一次的子节点的内存地址
nodeToTest = nodeToTest.nodeLink
# 将该元素本次(最末端)的子节点的位置,赋给headerTable保存的地址中的nodeLink属性。
nodeToTest.nodeLink = targetNode
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
# ['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
simpDat = loadSimpDat()
initSet = createInitSet(simpDat)
myFPtree, myHeaderTab = createTree(initSet, 3)
myFPtree.disp()