之前网站的自动爬虫已经启动了,那每天至少有文章可以更新了,暂时不用管了,所以最近开始着手想做点数据可视化的内容,毕竟NBA的数据信息是非常大而且每年更新的。
所以今天开始初学一下python数据可视化最有名的库Matplotlib
而里面关于2D图最有名的莫过于Pyplot
还是跟着官方文档来学一下
1:最简单的二维图
首先我们创建最简单的程序
import matplotlib.pyplot as plt
plt.plot([1,2,3,4]) #设置图表的坐标
plt.ylabel('y axis') #在y轴上显示的文字
plt.show() #运行后会让图表显示出来
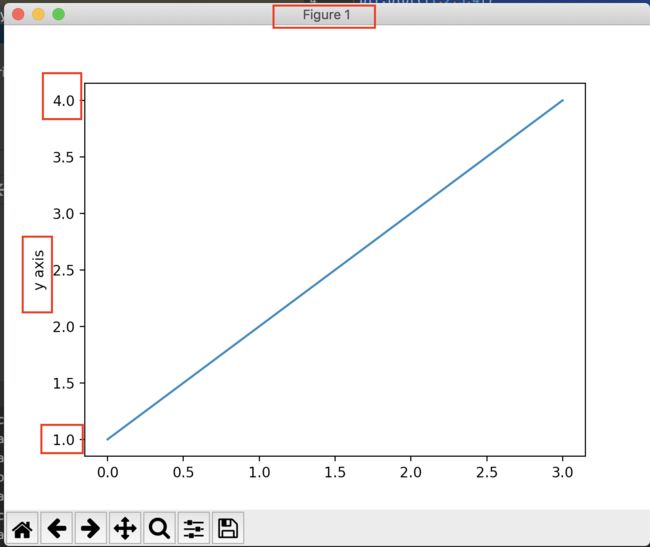
注意到,Y轴的名称已经如我们设置,成了‘y axis’,而y轴的坐标是1到4,但是x轴的坐标为什么却是0到3呢?
因为如文档所述:如果在plot的参数里面只输入一个序列的话,他会默认认为是Y轴的数据,而X轴则会根据python的默认规则来进行显示,而python的range是从0开始的。
而最重要的是,他会根据y轴的长度,来一样显示x轴的长度,所以x是0到3.
然后我们再看一下,设置x和设置y的情况下,图标是什么样子。
import matplotlib.pyplot as plt
plt.plot([1,2,3,4],[1,2,3,4])
plt.show()
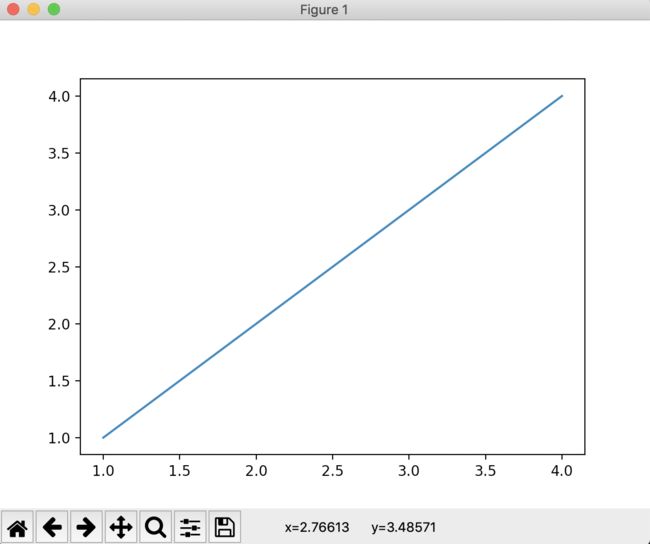
2:不同的表现形式
可以看到,这个线的起点和终点和表格的范围是一致的。
那有没有办法是显示范围比线条的范围大么?
这时候,我们就要用到第三个参数
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro') #第三个参数可以设置表现形式
plt.axis([0, 6, 0, 20]) #axis里面可以头两个参数设置的是x的起点终点,后两个参数是y的起点终点
plt.show()
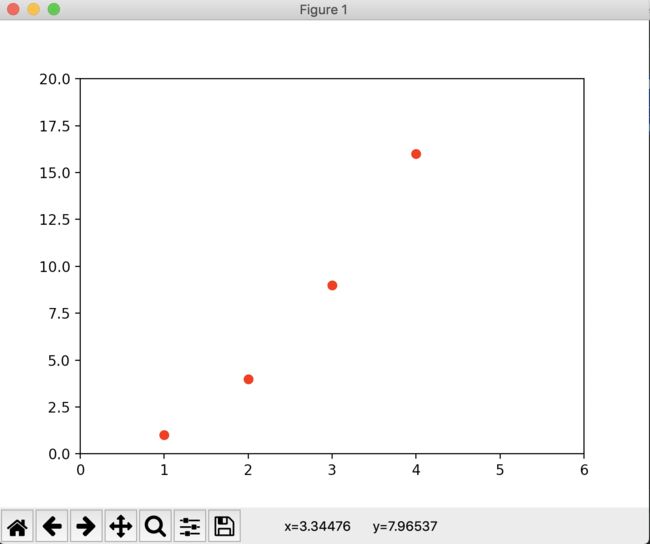

3:同一个表格中同时表现几根线
前面用到的全部是一个表格一条线例子,下面试一下一个表格多条线的表现形式。
同时我们还需要引入numpy的使用,在数据分析中,numpy和pandas的使用是非常频繁的。
我们来看一下例子
import matplotlib.pyplot as plt
import numpy as np
# 从0.0到5.0之内,每隔0.2
t = np.arange(0., 5., 0.2)
# 红色线段, 蓝色方点 和绿色上箭头
plt.plot(t, t, 'r--', t, t**2, 'bs', t, t**3, 'g^')
plt.show()

4: 点状分布图
这篇的最后再生成一个点状分布图
import numpy as np
import matplotlib.pyplot as plt
data = {'a': np.arange(50),
'c': np.random.randint(0, 50, 50),
'd': np.random.randn(50)}
data['b'] = data['a'] + 10 * np.random.randn(50)
data['d'] = np.abs(data['d']) * 100
plt.scatter('a', 'b', c='c', s='d', data=data)
plt.xlabel('entry a')
plt.ylabel('entry b')
plt.show()
这里一下子用到的变量和参数变多了,来一一解释一下
以上面的例子,scatter一般有几个参数
scatter(x,y,c,s,data)
x和y就是表示每个点的坐标,这里看到
a是arange(50),也就是从0开始不包括50,一共50个位置。
c是0到50之间,50个随机整数
d是从0到1之间,满足正态分布的50个数值
再来看b实际上是基于a的数值,加上对应50个正太分布数值乘以10的集合,这里一定要注意,x有多少数值,y也一定要有多少数值,不然等于坐标少数值了.
再来看参数c和s
c其实对应的是颜色,color的缩写,他可以接受字符串描述,也可以
s其实就是点的大小,size的缩写,这里是按照d的100倍来进行随机设置.
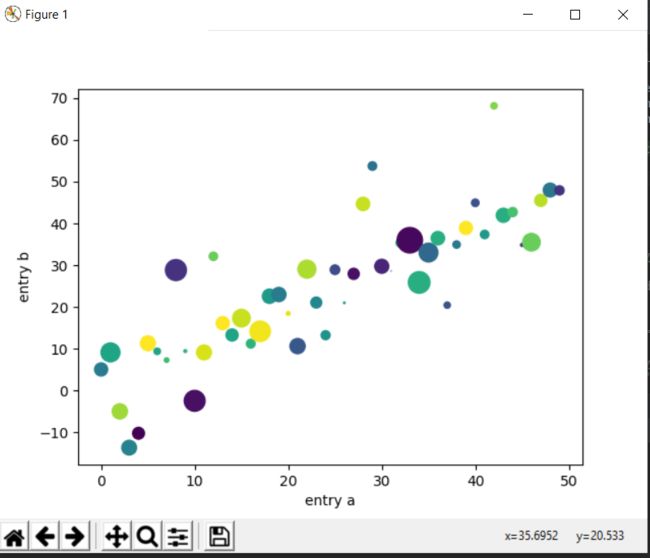
这个scatter功能就是散点图,我们来看一下官方文档中的定义.
matplotlib.pyplot.``scatter`(*x*, *y*, *s=None*, *c=None*,
*marker=None*, *cmap=None*, *norm=None*, *vmin=None*, *vmax=None*,
*alpha=None*, *linewidths=None*, *verts=None*,
*edgecolors=None*, ***, *plotnonfinite=False*,
*data=None*, ***kwargs*)
其中比较重要的其他几个参数就是,cmap,norm,vmin和vmax
cmap是告诉scatter,选用哪个色图,有没有想过,我写了上面的代码,为什么出来的是这几个颜色?
因为scatter默认的色图是
viridis
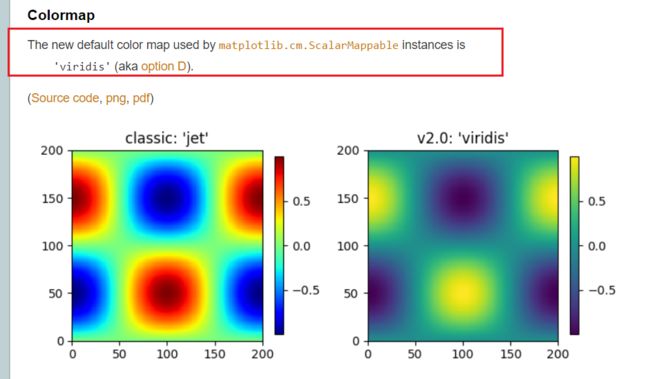 image.png
image.png
你可以给参数cmap重新设定其他的色图,你就可以呈现其他颜色了。
另外一个,norm,vmin和vmax
实际上,如果你在scatter内给到c参数一个数字的数列以后,内部会把数量进行标准化,什么是标准化,我也讲不清楚,功能就是把数列对应成[0,1]的范围内,比如你给的序列是[0,2,4,6,8],那序列化以后,0就代表0位,也就是最左端,8就代表最右端。
当你不设置norm的时候,他默认就是这样,用序列最小的数字做vmin,最大的数字做vmax。
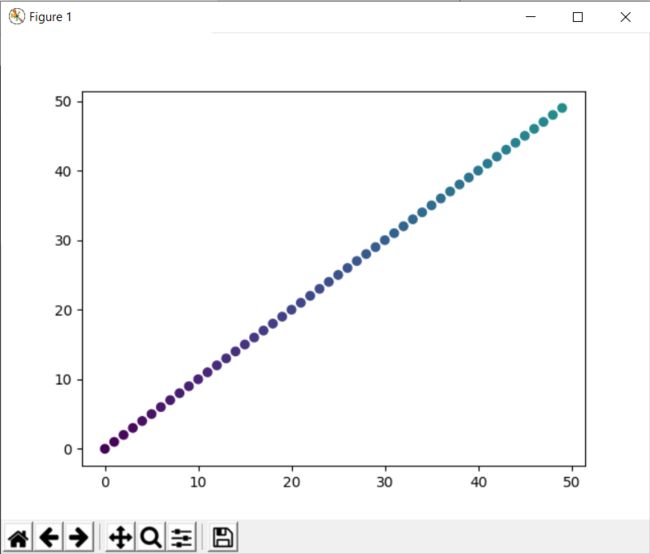
我们来看一个更加简单的例子
x = np.arange(50)
y = x
z = np.arange(50)
plt.scatter(x,y, c = z)
plt.show()

他这样就是,将50个数,序列化到0到1之间的了,所以这个图的从头到尾,颜色是均匀分布的。
vmin和vmax的作用
我们再来设置一下vmin和vmax对色图产生的作用
这个数字序列最大的是50,那我想把50的颜色只显示为中间段的墨绿色,而不是顶部的黄色,该如何做呢?
答案是将vmin设为0,vmax设为100,这样,相当于做了一把比例尺,将色图拉成了原来的2倍长,而50这个数字正好落在了色图的中间。
这样,初步的scatter用途第一篇就记录到这里。
看了不少文章
参考资料如下:
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.scatter.html#matplotlib.pyplot.scatter
https://stackoverflow.com/questions/52108558/how-does-parameters-c-and-cmap-behave-in-a-matplotlib-scatter-plot