https://www.lousenjay.top/2018/12/21/%E6%95%B0%E6%A0%88-%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E8%A7%84%E8%8C%83/
术语解释
ODS(Operational Data Store):操作型数据,即源数据,指结构与源系统基本保持一致的增量或全量数据。作为DW数据的一个数据准备区,同时又承担基础数据记录历史变化。
CDM(Common Data Model):通用数据模型(数据中间层),包含DWD和DWS。
DWD(Data Warehouse Detail):数据仓库明细层数据。
DWS(Data Warehouse Summary):数据仓库汇总层数据。
ADS(Application Data Service):面向应用的数据服务层。
冒烟测试:文本中指代码运行能否正常结束,属于功能性测试。
数据处理流程
1.离线数据处理流程
如图所示,离线数据公共层模型层次分为4个层次,其中DWD、DWS属于中间层(CDM)。

2.实时数据处理流程
如图所示,实时数据公共层模型层次分为3个层次,其中DWD、DWS属于中间层(CDM),其中DWD落地供后续应用(ADS)订阅使用,DWS为各数据域的中间汇总层。

项目管理
1.项目命名
ODS层项目以ods为后缀,如mtods。
中间层项目以cdm为后缀,如mtcdm。
应用层项目分两类:
第一类,数据报表、数据分析等应用以bi为后缀,如mtbi。
第二类,数据产品等应用以app为后缀,如magicapp等。
数据报表:报表就是用表格、图表等格式来动态显示数据,可以用公式表示为:“报表 = 多样的格式 + 动态的数据”。
数据分析:数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
2.项目空间目录结构
a.工作流
应初始化2层目录(根目录算第0层)结构,第一层目录表示数据域(对于中间层项目)或业务线(对于应用层项目),如渠道、消费者、商品、交易、仓储物流、服务、营销、社交、日志,第二层目录表示层次,如DWD、DWS、DIM以及数据同步任务。
另外,建议增加三个一级目录为RESOURCE、TEMP和VIRTUAL NODE,其中RESOURCE目录主要放置资源文件,按照节点类型再进行细分,如UDF、JAR、SHELL等,TEMP目录按照开发人员姓名再进行细分,VIRTUAL NODE放置虚拟节点。如果虚拟节点或者UDF、JAR、SHELL 只是作用于某个表时,这些虚拟节点、资源请放在表级目录下,如果是公用的请放在RESOURE、TEMP和VIRTUAL NODE相应的目录下。
一般是:根目录(工作流)—>数据域(交易)—>数据层次(DWD)—>表名称(dwd_mt_ord_evt_di)
b.临时查询
临时查询TAB页建议以开发人员姓名作为文件夹进行管理,以避免临时查询文件列表过多。
3.工作流节点类型及命名

4.工作流起始节点
每个Project必须设立一个起始节点,命名为vt_{project_name}_start,表示该project的任务起点。
5.资源文件
项目中公用的资源文件建议放在RESOURCE目录中,资源名称需有后缀表示资源类型,如.java、.py、.sh等。如果某个资源文件如java只是服务于某个表,请把这个资源文件放在表级目录下。
表与视图
1.表的命名
DWD表与视图命名规范:
dwd_{业务BU缩写/pub}_{数据域缩写}_{业务过程缩写}[_{自定义表命名标签缩写}]_{刷新周期标识}_{单分区增量全量标识}
例如:dwd_mt_ord_evt_di
DWS表与视图命名规范:
dws_{业务BU缩写/pub}_{数据域缩写}_{数据粒度缩写}[_{自定义表命名标签缩写}]_{统计时间周期范围缩写}[_刷新周期标识][_单分区增量全量标识]
关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近一天(_1d),最近N天(_nd)和历史截至当天(_td)三个表,如果出现_nd的表字段过多,需要拆分之时,只允许以一个统计周期单元作为原子拆分,也就是说一个统计周期拆分一个表,比如最近7天(_1w)拆分一个表;不允许拆分出来的一个表存储多个统计周期的。
例如:dws_mt_ord_shp_1d
ADS表命名不做强制要求,以下是命名建议:
{project_name}.ads_{业务BU缩写/pub}_{应用名称}[_数据粒度] [_{自定义表命名标签缩写}]_刷新周期标识
2.表的创建
创建表之前必须按照数据模型规范确定表和字段的命名,并根据需求确认表的生命周期并给表和字段加上完整的注释。分区字段必须加上注释。
建表样例:
1
2
3
4
5
6
7
8
9
10
create table if not exists dwd_mt_explore_item_di(
stat_date STRING COMMENT '统计日期,星期日'
,seller_user_id BIGINT COMMENT '卖家ID'
,device_type STRING COMMENT '所属访问终端类型'
,item_id BIGINT COMMENT '宝贝ID'
,uv_cnt_cw_144 BIGINT COMMENT '自然周访客UV'
,dpv_cnt_cw_058 BIGINT COMMENT '自然周被浏览DPV'
)
comment '宝贝浏览自然周表'
partitioned by (ds STRING COMMENT '账期分区,格式yyyymmdd')
3.视图
视图的命名为{表名}_v。
视图应创建独立的刷新任务以产生视图,刷新任务脚本为视图创建脚本。
创建视图样例:
1
2
3
create or replace view dwd_mt_explore_item_di_v as
select stat_date, seller_user_id
from tbcdm.dwd_mt_explore_item_di;
编码
1.编码原则
要求代码行清晰、整齐,具有一定的可观赏性;
代码编写要充分考虑执行速度最优的原则;
代码行整体层次分明、结构化强;
代码中应有必要的注释以增强代码的可读性;
代码要做到整个节点可以多次重跑,结果不变;
规范要求非强制性约束代码开发人员的代码编写行为,在实际应用中在不违反常规要求的前提下允许存在可理解的偏差;
2.基本要求
代码段中应用到的所有SQL关键字、保留字都使用全大写或小写,不能使用大小写混合的方式,如Select或seLECT等方式;
代码段中应用到的除关键字、保留字之外,都使用小写;
四个空格为一个缩进量,所有的缩进皆为一个缩进量的整数倍;
最外层禁止使用select *操作,所有操作必须明确指定列名;
禁止使用insert into语句,用union all代替;
Where条件中字段空和空字符串要进行必要的coalesce处理;
对应的括号通常要求在同一列的位置上。
3.数据类型
一般情况下,使用以下四种:
Bigint
String
Double
Datetime
由于潜在的兼容性问题和扩展性问题,不建议使用Boolean类型。
在对精度要求极其严格的场景下谨慎使用Decimal类型。
具体类型,如下图所示:

4.编码规范
a.代码头部
代码头部添加主题、功能描述、作者、日期等信息,并预留修改日志及标题栏,以便后续修改同学添加修改记录。注意每一行不超过80个字符。以下是模板:
1
2
3
4
5
6
7
8
9
--**************************************************************************
--所属主题: 日志域(项目名称)
--功能描述: 页面引导成交
--创建者 : XX
--创建日期: 20171017
--修改日期 修改人 修改内容
--20130826 XX init
--20150127 YY 修改订单取数口径,只取支付订单
--**************************************************************************
b.字段排列要求
SELECT语句选择的字段按每行一个字段方式编排;
SELECT单字后面一个缩进量后直接跟首个选择的字段,即字段离首起二个缩进量;
其它字段前导二个缩进量再跟一‘,’点后放置字段名;
两个字段之间的‘,’点分割符紧跟在第二个字段的前面
‘AS’语句应与相应的字段在同一行;多个字段的‘AS’建议尽量对齐在同一列上;
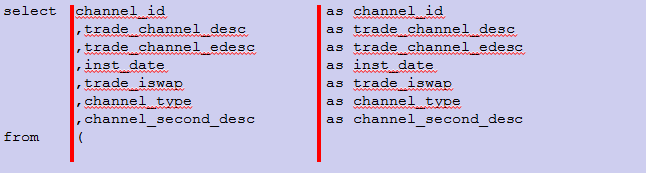
c.select子句排列要求
SELECT语句中所用到的FROM、WHERE、GROUP BY、HAVING、ORDER BY、JOIN、UNION等子句,需要遵循如下要求:
换行编写;
与相应的SELECT语句左对齐编排;
子句后续的代码离子句首字母二个缩进量起编写;
WHERE 子句下的逻辑判断符 AND、OR等与WHERE左对齐编排;
超过两个缩进量长度的子句加一空格后编写后续代码,如:ORDER BY、GROUP BY等;

d.运算符前后间隔要求
算术运算符、逻辑运算符的前后要保留一个空格
e.case语句的编写规范
SELECT语句中对字段值进行判断取值的操作将用到的CASE语句,正确的编排CASE语句的写法对加强代码行的可阅读性也是很关键的一部分。
对CASE语句编排作如下约定:
WHEN子语在CASE语句的同一行并缩进一个缩进量后开始编写;
每个WHEN子句一行编写,当然如果语句较长可换行编排;
CASE语句必须包含ELSE子语,ELSE子句与WHEN子句对齐;
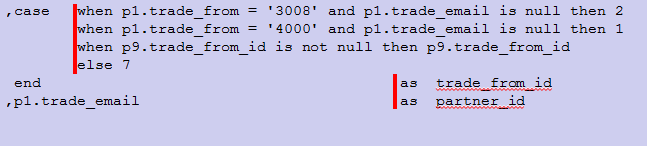
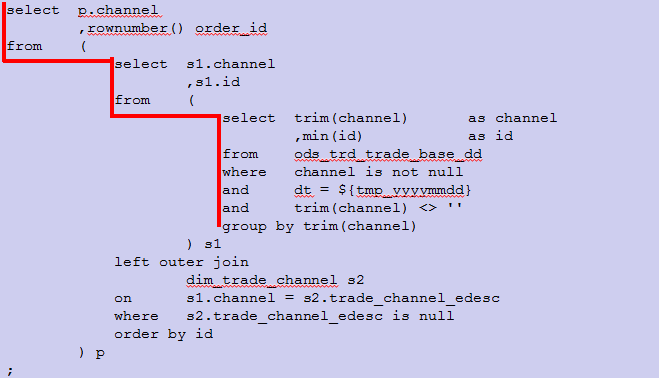
f.子查询嵌套语句的编写规范
子查询嵌套在数据仓库系统ETL开发中是经常要用到,因此代码的分层编排就非常重要。
g.sql注释的编写规范
每条SQL语句均应添加注释说明;
每条SQL语句的注释单独成行、放在语句前面;
字段注释紧跟在字段后面;
应对不易理解的分支条件表达式加注释;
对重要的计算应说明其功能;
过长的函数实现,应将其语句按实现的功能分段加以概括性说明;
常量及变量注释时,应注释被保存值的含义(必须),合法取值的范围(可选);
节点配置规范
1.小时任务配置
时间参数: date=$[yyyymmdd] hour=$[hh24], ‘${date}’,’${hour}’ 可在代码中直接作为变量使用。Eg: insert overwrite table tmp_dwd_mt_ord_evt_hh partition (ds=’${date}’, hh=’${hour}’).
时间属性:开始时间必须选择00:59。
2.天任务配置
时间参数: bizdate=$bizdate;’${ bizdate }’可在代码中直接作为变量使用。
3.调度依赖
调度任务必须选择“自动解析”。 自动解析会把所有的from表作为input ,所有的insert的表作为输出。对于程序中辅助程序开发的过程表、临时表也会被解析出来,因此必须对这些临时表进行过滤。
在代码头部加入exclude 语句即可过滤相对应的表,调度依赖中就不会显示依赖关系。
1
2
--@exclude_output=tmp_dwd_tb_trd_ord_subpay_di_1
--@exclude_input=tmp_dwd_tb_trd_ord_subpay_di_1
测试及质量保证
1.新增业务需求测试项

2.数据迁移/重构/修改
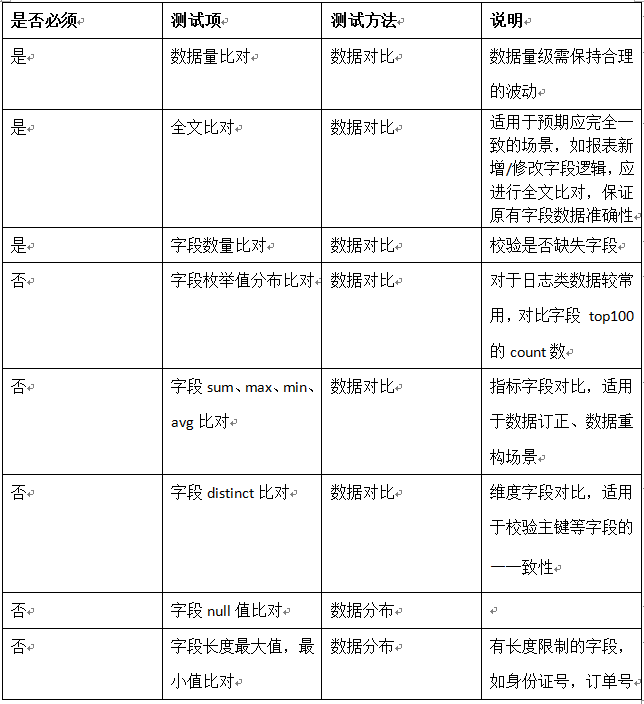
发布上线
无QA(质量保证)参与的项目,由开发负责自测,在开发测试环境通过后再自行发布到生产环境。有QA参与的项目必须由开发与QA都测试通过后方可发布。
维护及故障处理
1.数据重刷
如果任务运行失败,请直接重跑,如果是由于代码变更或上游数据变更导致输出数据发送变更,请预先评估给下游带来的影响而决定是否需要重跑。重跑之(前)后,一定要通知直接下游或重要的间接下游,让下游采取相关的措施。
2.补数据
补数据如果只是针对历史分区回刷,可以直接执行补数操作。如果补数据还会对现有分区数据造成影响,请预先评估给下游带来的影响而决定是否需要进行相关操作,补数据(前)后,一定要通知直接下游或重要的间接下游,让下游采取相关的措施。
3.口径修改
如果表的取数口径或者字段口径算法发生变更,必须提前通知下游并与下游达成一致后,方可进行后续操作。
4.故障处理
遇到任务报错、上游问题、平台问题符合数据质量故障的走数据质量故障流程,不符合的走数据质量事件。对于他人转过来的流程请及时处理。
5.工作交接
数据工程师在转岗、离职前,必须将手头任务转给相关的接手人,如在转岗、离职后还未交接的,该任务归属其主管负责。