我们在使用爬虫脚本抓取数据时通常都会有定时更新的需求,下面跟大家介绍一款python语言中非常流行的定时任务执行框架———apscheduler
apscheduler简介:
APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个python定时任务系统。
使用方法:
安装:pip install apscheduler
重点介绍该框架最实用的两种功能
功能一:interval: 每隔一段时间执行一次weeks=0 | days=0 | hours=0 | minutes=0 | seconds=0, start_date=None, end_date=None, timezone=None
功能二:cron:在固定时间点执行一次year=0|month = 0|day = 0|hour = 0|minute = 0|second = 0
使用例子:
表示2017年3月22日17时19分07秒执行该程序
sched.add_job(my_job, 'cron', year=2017,month = 03,day = 22,hour = 17,minute = 19,second = 07)
#表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
#表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
sched.add_job(my_job(), 'cron', day_of_week='mon-fri', hour=5, minute=30,end_date='2014-05-30')
#表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
sched.add_job(my_job, 'cron',second = '*/5')
demo代码:
# coding=utf8
from apscheduler.schedulers.blocking import BlockingScheduler
import time
def my_job(): # 需要重复执行的任务
print("job_start:",time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
time.sleep(3)
print("job_end:",time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
sched = BlockingScheduler()
# 方式一
sched.add_job(my_job, 'interval', seconds=6) # 把任务添加到执行队列中,每间隔6s执行一次。
#方式二
sched.add_job(my_job, 'corn', hour=0) # 把任务添加到执行队列中,每天零点执行。
sched.start() # 任务开始
以每间隔6s启动一次的任务作为测试案例:
输出:
(py3_django) E:\spider\test_ap>python test_ap.py
Pending jobs:
my_job (trigger: interval[0:00:06], pending)
job_start: 2018-09-16 10:25:06
job_end: 2018-09-16 10:25:09
job_start: 2018-09-16 10:25:12
job_end: 2018-09-16 10:25:15
这时细心的读者可以发现一个有趣的现象,明明之前设置的的间隔时间是6s,但是第一个任务结束到第二个任务开始只隔了3s。由此可以得出一个重要的结论:apscheduler在执行任务时,只要任务开始就计时,而不是等任务结束才计时。
同时衍生出另一个问题:如果任务执行的时间超过间隔时间会怎样?
测试二:将demo中的sleep参数改成8,其余不变:
输出
Pending jobs:
my_job (trigger: interval[0:00:06], pending)
job_start: 2018-09-16 10:51:15
Execution of job "my_job (trigger: interval[0:00:06], next run at: 2018-09-16 10:51:21 CST)" skipped: maximum number of running instances reached (1)
job_end: 2018-09-16 10:51:23
job_start: 2018-09-16 10:51:27
Execution of job "my_job (trigger: interval[0:00:06], next run at: 2018-09-16 10:51:33 CST)" skipped: maximum number of running instances reached (1)
job_end: 2018-09-16 10:51:35
通过以上的测试结果可以得出结论:当任务执行所花费的时间大于间隔时间时,apscheduler会抛出一个异常,但是不会影响任务正常执行。它会自动跳过,开始下轮计时。所以6+6-8=4,第一个任务结束,和下一个任务开始间隔时间为4秒。
当需要定时执行的代码出现异常会怎样:
测试三:让被执行的任务抛出一个异常
输出
job_start: 2018-09-16 11:04:53
Job "my_job (trigger: interval[0:00:06], next run at: 2018-09-16 11:04:59 CST)" raised an exception
Traceback (most recent call last):
File "C:\Users\lenovo\Anaconda3\envs\py3_django\lib\site-packages\apscheduler\executors\base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "test_ap.py", line 21, in my_job
print(a)
NameError: name 'a' is not defined
job_start: 2018-09-16 11:04:59
Job "my_job (trigger: interval[0:00:06], next run at: 2018-09-16 11:05:05 CST)" raised an exception
Traceback (most recent call last):
File "C:\Users\lenovo\Anaconda3\envs\py3_django\lib\site-packages\apscheduler\executors\base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "test_ap.py", line 21, in my_job
print(a)
NameError: name 'a' is not defined
由以上的测试结果可以得出一个结论:当被定时执行的任务抛出异常时,定时循环并不会终止,等到下一轮仍然继续执行。
我们在日常开发中会经常碰到需要修改代码的情况,当我们修改了爬虫代码,在不重新启动定时任务的情况下修改会不会生效呢?经过实践,我发现当采用命令行方式启动修改会生效,直接调用函数改动不会生效。
测试四:修改代码后,不重启定时任务,修改是否生效。
# 调用函数启动任务
代码修改前:

输出:

代码修改后:

输出

可以看出使用调用函数方法启动时,没有重启定时任务的情况下,修改没有生效。
# 命令行方式启动
代码修改前

输出
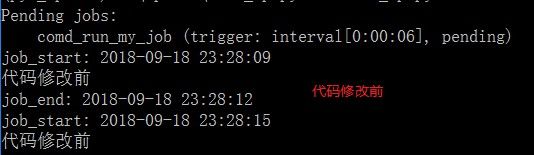
代码修改后
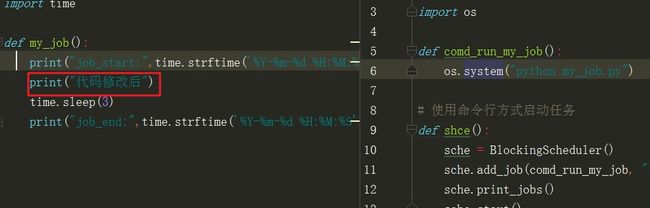
输出
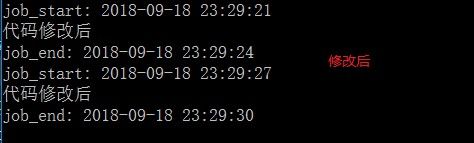
由此可以看出,当使用命令行方式启动时,修改代码后,即使没有重新启动定时任务代码的修改是可以生效的,所以如需要频繁修改代码,建议采用命令行的方式启动爬虫。