embeding自word2vec词嵌入后一战成名,在NLP领域得到了充分应用。embeding克服了onehot高维稀疏、无法表示不同特征相关性的缺点。因此,在很多领域都得到了充分的应用,出现了各种各样的embeding。下面做一个简单的介绍,如需详细了解,可阅读相关论文。
对于word2vec这里不再进行讨论,可参考《浅谈词嵌入(二):word2vec 词嵌入矩阵学习》。
《Entity Embeddings of Categorical Variables》
本文主要介绍的是针对高维类别特征的embeding。在建模过程,某一字段(特征)可能包括多个属性,如用户点击过的物品——包含很多物品。通常的处理方法可能是将这一个字段分解为多个字段然后使用onehot编码,如某个样本的物品字段为[item1, item2, item3],转化为onehot后则为三个0nehot编码的特征,如果物品的类别很多,转化为onehot后则会出现高维稀疏的问题。而使用embeding后,能有效解决高维稀疏问题,减少计算量,且可以揭示不同物品的内部相关性。
在本文中,embeding矩阵的训练方法与word2vec不同,word2vec中embeding通常是最终任务的一个预处理步骤,得到embeding向量,然后将每个词的embeding向量用作后续向量的输入特征,其训练是独立的。而在本文中,embeding矩阵的训练是与最终任务合并在一起的,如下:
其中A, B, C分别表示不同的包含多类别的字段。这个网络与一般的网络不同的地方在于其将A、B、C分开了以分别训练其embeding矩阵(一般的网络这里是全连接的,更改后能够减少很多计算量),从上面可以看到,A,B,C的embeding矩阵训练是与最终的分类模型合并在一起进行训练的。
不过这里需要思考的一点是,能否像word2vec一样将embeding训练提出来?个人认为应该是可以的,即每个样本的这个字段作为一个句子来使用word2vec进行训练。但是,这样做的话还存在一个问题,那就是顺序的问题——在word2vec中虽然训练时输入window中词汇是没有考虑顺序的,但是整体window滑动时候是考虑了顺序的。而在物品字段中,这些物品的先后顺序显然是没有那么大的意义的,这时候需要怎么处理?一个我能想到的处理方法是将每个长度大于window size的样本进行随机打乱顺序多次添加到训练集中。但是这么做是否有效仍然是有待证明的。
《Item2Vec: Neural Item Embedding for Collaborative Filtering》
在上面我们提出了一个问题,本文可以看作是对这个问题的最佳解答。
本文针对不同的Item,采用了不同的方式来看待:
- 1、若item是强时序关系的,那么对某一次序列中的item,可以看作是doc中的一个句子,使用word2vec进行训练;
- 2、若item是set-based,即无序的,不用考虑时序,则需要改变训练方法。
第一种看待方式就是word2vec的正常训练,而对于第二种方式,作者提出了两种解决方式:
- 1、改变滑动窗口,不在使用定长,而是将整个set里面的word进行两两组合成样本进行训练;
- 2、在训练过程中对每个set进行随机打乱顺序。
最后,作者发现两者结果是相同的。
《DeepWalk: Online Learning of Social Representations》
DeepWalk是使用embeding方法来学习表示图特征表示,即使用一个向量来表示图中的各个顶点。
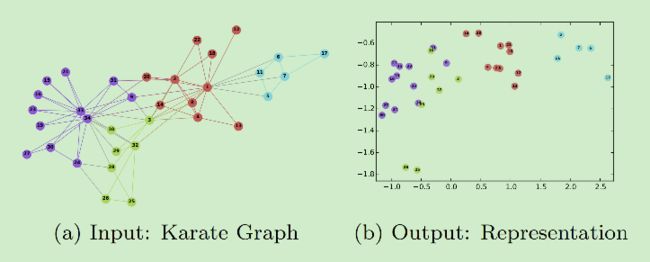
DeepWalk的网络嵌入学习主要包括两步:第一步是随机游走生成一系列顶点组成的序列,类比于word2vec中的句子;第二步则是与word2vec相同的,使用skip-gram进行训练。
《LINE: Large-scale Information Network Embedding》
作者认为现有的网络embeding方法大多无法应用在现实的大规模网络中,因此提出了一种新的网络embeding方法——LINE。论文中作者提到了网络中两个节点相似性的表达方式:
- 1、First-order Proximity(一阶相似度),网络中一阶相似度是指两个节点之间的自身相似(不考虑其他节点)。具体的表现方式是若一对节点之间有边直接相连,则他们具有一阶相似性,若是加权边的话,权重还可以表示相似的程度。
一阶相似度通常意味着现实世界网络中两个节点直接表现出来的相似性。例如,社交网络中相互交友的人往往有着相似的兴趣,在万维网上相互链接的页面倾向于谈论类似的话题。 -
2、Second-order Proximity(二阶相似度),网络中一对顶点(u, v)之间的二阶相似度是他们邻近网络结构之间的相似性。最简单的表现为两个节点相邻节点的交集,交集越大则二阶相似度越高。
由于有些节点之间虽然相似但是却没有直接边相连,因此一阶相似度不足以保存网络结构。因此提出共享相似相邻节点的节点相似,即二阶相似度。例如,在社交网络中,有共同朋友的人倾向于具有相似的兴趣,从而成为朋友;在词语共现网络中,总是与同一组词语共同出现的词往往具有相似的含义。
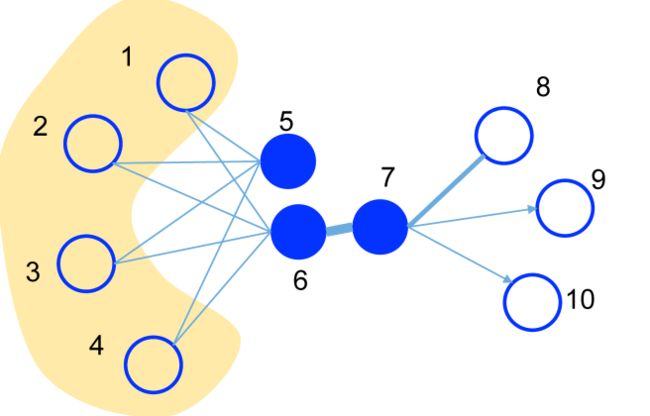 顶点6-7具有一阶相似性,而顶点5-6具有二阶相似性
顶点6-7具有一阶相似性,而顶点5-6具有二阶相似性
作者提到,deepwalk在随机游走的过程中其实是寻找二阶相似度的节点,因为随机游走找的是邻居节点(context node)。
在计算时,作者将这两种相似度分别建立目标函数进行优化,得到两个embeding矩阵,最后将这两个embeding矩阵相加得到最终的embeding矩阵。
同时,训练时作者还采用了几个小trick(具体可参考原文和https://www.jianshu.com/p/8bb4cd0df840):
- 1、负采样,这里的负采样与word2vec的负采样类似;
- 2、边采样。由于不同边的权重大小变化很大,不利于模型收敛。因此作者使用了边采样。这里的边采样其实与word2vec的负采样也有几分相似,其先将一个加权边转为多个无权边(如权重为5转化为5个无权边),这样边的权重就变成了binary的了。而采样的时候,权重大的边出现次数较多,也更容易被采到,与负采样类似;
- 3、稀疏节点处理。稀疏节点(即邻接节点非常少)使用其邻接节点的邻接节点作为其邻接节点以扩增其邻接节点数量以解决稀疏性问题。
《Structural Deep Network Embedding》
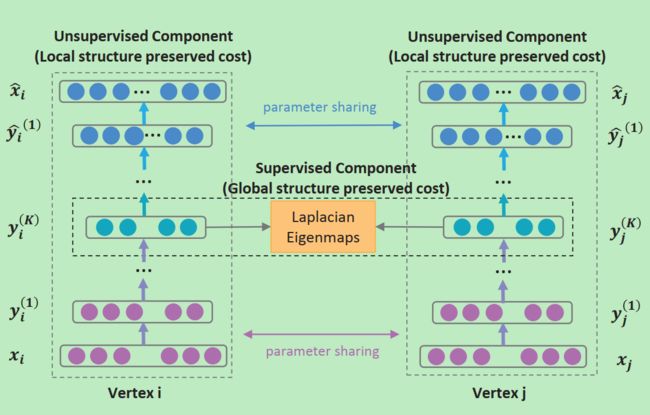
本论文作者认为已有的网络embeding模型都过于简单无法很好地拟合网络中复杂的非线性关系,且很多已有的方法都只考虑到了网络中的局部相似性和全局相似性的一部分。因此,作者提出了基于神经网络的半监督模型以用来生成embeding矩阵。
此神经网络是一个自编码器(autoencoder),其中自编码器的编码部分就可以看作是embeding矩阵,自编码模型是无监督模型。自编码器的输入使用的二阶相似性数据,即某个节点的所有附近节点。但是这样是不够的,没有考虑到一阶相似性,因此作者将一阶相似性整合到网络中,用来调整使得网络对于两个相邻节点(即一阶相似性,这是标注出来的,属于有监督)的embeding是相似的(即给编码矩阵部分又加上一个条件)。最后的目标函数如下:
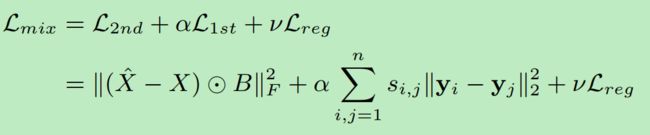
即原始自编码器的loss加上一阶相似数据精修带来的loss以及自编码器的正则项。
《node2vec: Scalable Feature Learning for Networks》
node2vec是对DeepWalk的一次改进,deepwalk使用的随机游走可看作深度优先算法,但是其没有考虑到广度优先遍历带来的周围邻居的影响。因此,node2vec在随机游走生成序列时不仅考虑了深度优先遍历还考虑了广度优先遍历。
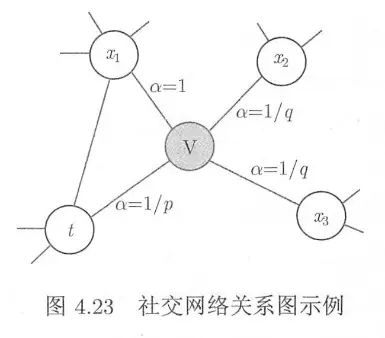
在论文中,作者使用了p和q两个参数来调节游走,首先计算其邻居节点与上一节点t的距离d,根据下面的公式得到α:
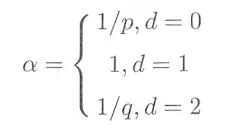
上式中p用来控制往回走(也可理解为广度优先遍历)的,p越大,广度优先遍历可能性越小;q用来控制深度优先遍历,q越大,深度优先遍历的可能性越小。当下一个顶点、当前顶点和上一个顶点构成三角形时(即上图t, v, x1),距离为1,α=1。
一般从每个节点开始游走5~10次,步长则根据点的数量N游走根号N步。如此便可通过random walk生成点的序列样本。
最后,在各个节点的转移概率为:
其中α通过上面的式子计算得到,而w则是节点间连接的边的权重。
得到序列之后,便可以通过word2vec的方式训练得到各个用户的特征向量,通过余弦相似度便可以计算各个用户的相似度了。有了相似度,便可以使用基于用户的推荐算法了。
《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》
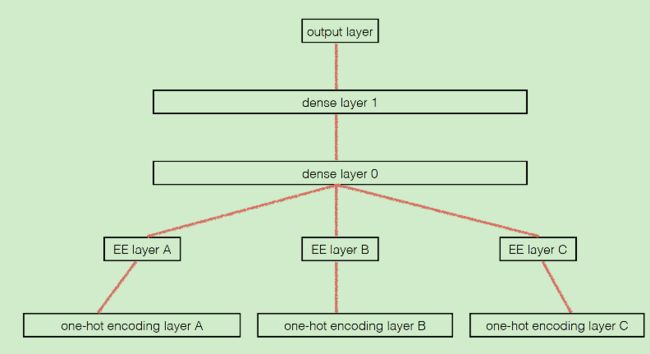
在本文中,作者针对大型电商平台推荐系统存在的三大挑战——大规模,稀疏性以及物品冷启动,提出一个新的物品embeding模型。该模型以deepwalk为基础,附加额外的信息(物品所属类别、商店、品牌等信息),训练出了一个stage-of-art的embeding方法。
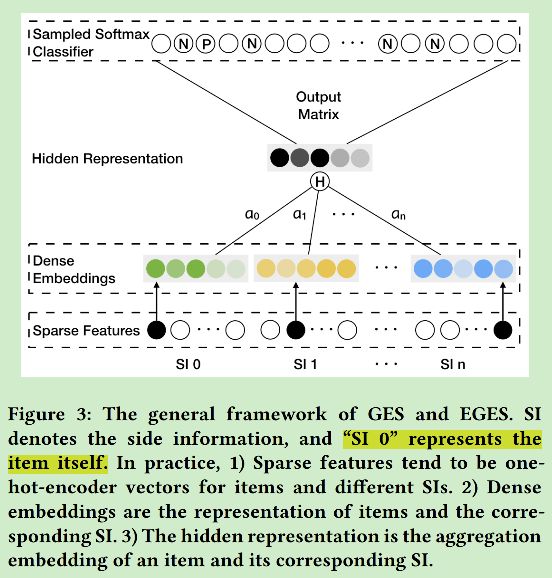
如上图,显示的是embeding模型的框架,这个框架是基于skip-gram的,其中sparse features层中的输入是多个onehot向量,分别表示item和附加信息(类别、品牌等,每一个附加信息就是一个onehot向量)。第二层就是embeding矩阵层,每个稀疏层一个embeding矩阵。第三层是隐藏层,在输入隐藏层之前,第二层的各个embeding向量结果需要经过组合,在文中作者使用了两种组合方式:最简单的取平均以及根据重要性加权的方式,结果显示加权的方式更好。
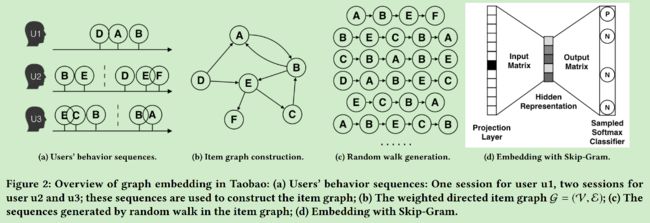
文中模型的效果较之前模型好很容易理解——添加了附加信息。但是有一点需要指出的是,如果作者只是基于deepwalk来生成item序列的话,只能得到一阶相似性。如果使用与node2vec类似的随机游走方式的话是否能得到更好的结果呢?不过没看过源码,也无从得知作者采用的随机游走方式。