这篇文章主要通过工作中shell脚本案例,介绍shell脚本中常用知识点
下面的这个脚本表示使用sqoop把生产数据库mysql中的商户交易数据导入到hive数据库,且生产数据库中商户交易数据是分库分表存放的(10个库100个表中),分表分库原则根据商户F_merchant_id来分的,比如说一个商户号F_merchant_id='xxxxx855',可以看到商户号是倒数第三位是8,分库的时候会存放到第8个数据库中,最后两位数字是55,所以分表的时候会存放到第55张表中。所以对于商户号xxxxx855的所有交易数据会存放到第8个数据库,第55个表中。
#抽取从2019年1月4号到2019年2月10日的所有商户交易数据
begin_date="20190104" #定义开始时间变量
end_date="20190210" #定义结束时间变量
while [ "$begin_date" -le "$end_date" ] #$begin_date表示参数的引用
do
y=${begin_date:0:4}
m=${begin_date:4:2}
d=${begin_date:6:2}
echo "${y}-${m}"
begin_date=$(date -d "${begin_date}+1days" +%Y%m%d)
y1=${begin_date:0:4}
m1=${begin_date:4:2}
d1=${begin_date:6:2}
for ((db=0;db<=9;db=db+1)) #从0到9,每次加1,共迭代10次 循环10个库
do
for ((j=0;j<=99;j=j+10))
do
querystr=''
for((k=1;k<=10;k++))#一次union 10个表
do
tb1[$k]=$[(${j}+k-1)/10] #相除
tb2[$k]=$[(${j}+k-1)%10] #取余
table[$k]="select F_transaction_id,F_order_id,F_merchant_id from datafrog${db}.t_transaction_operation_by_merchant_${tb1[$k]}${tb2[$k]} where F_time>='${y}-${m}-${d}' AND F_time<'${y1}-${m1}-${d1}' "
if [ $k -gt 1 ]
then
querystr="${querystr} union all ${table[$k]} "
else
querystr="${table[$k]}"
fi
done
#下面的脚本大家不需要看,是为整体效果做的展示
sqoop import \
--connect "jdbc:mysql://192.XXX.XX.XX/datafrog?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false" \
--driver com.mysql.jdbc.Driver \
--username datafrog \
--password www.datafrog.com \
--query \
"${querystr}" \
--fields-terminated-by '\t' \
--fetch-size 50000 \
--direct \
--append \
--target-dir /user/hadoop/sqoop/notcm/tran/$y$m$d \
-m 1
done
done
done
1.创建一个shell脚本
linux 系统中打开文本编辑器(可以使用 vi/vim命令来创建文件),新建一个文件 test.sh,扩展名为sh(sh代表shell)。输入一些代码,第一行一般是这样:
如下:
#!/bin/bash
echo "Hello World !"
2.给shell脚本赋权限
一般写好的shell脚本要先赋权限然才能后执行
chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本
3.shell脚本中while循环使用
while 语句格式
while condition
do
command
done
while循环案例
#!/bin/bash
int=1
while(( $int<=5 ))
do
echo $int
let "int++"
done
运行脚本,输出:
1
2
3
4
5
使用中使用了 Bash let 命令,它用于执行一个或多个表达式,变量计算中不需要加上$来表示变量
4.shell脚本中for 循环使用
for 循环与其他编程语言类似,Shell支持for循环。for循环一般格式为:
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
例如,顺序输出当前列表中的数字:
for loop in 1 2 3 4 5
do
echo "The value is: $loop"
done
输出结果:
The value is: 1
The value is: 2
The value is: 3
The value is: 4
The value is: 5
5.Shell脚本中字符串的拼接
如果想要在字符串变量后面拼接一个字符,可以用下面的方法:
value1=home
value2=${value1}"=" # 或者$value2=${value1}=
echo $value2
把要添加的字符串变量添加{}中,并且需要把$放到外面,上面的结果是:home=
还可以如下面的
[root@localhost sh]# var1=/etc/
[root@localhost sh]# var2=yum.repos.d/
[root@localhost sh]# var3=${var1}${var2}
[root@localhost sh]# echo $var3
/etc/yum.repos.d/
6.shell脚本中的关系运算符
- -eq:等于 equal
- -ne:不等于 not equal
- -le:小于等于 less equal
- -ge:大于等于 greater equal
- -lt:小于 less than
- -gt:大于 greater than
7.shell脚本中获取系统时间的方法
获取今天时期:
$(date +%Y%m%d)或$(date +%F或$(date +%y%m%d)获取昨天时期:
$(date -d yesterday +%Y%m%d)获取前天日期:
$(date -d -2day +%Y%m%d)获取10天前的日期:
$(date -d -10day +%Y%m%d)n天前的
$(date -d "n days ago" +%y%m%d)明天:
$(date -d tomorrow +%y%m%d)
- 给定的日期减一天
$(date -d "20150416 -1 days" +%Y%m%d)
- 给定的日期减去三天
$(date -d "20150416 -3 days" +%Y%m%d)
- 给定的日期加上三天
date -d "20150416 3 days" "+%Y%m%d"
7.shell脚本中字符串截取
可以使用这样的方法截取,表示从左边第几个字符开始以及字符的个数,用法为:start:len
例如:
str='http://www.
你的域名.com/cut-string.html'
echo ${str:0:5}
输出结果
结果是:http:
其中的 0 表示左边第一个字符开始,5 表示字符的总个数。
8.shell脚本中数组的使用
数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小,与大部分编程语言类似,数组元素的下标由0开始。
(1)创建数组
shell数组用括号来表示,元素用"空格"符号分割开,语法格式如下:
array_name=(value1 ... valuen)
实列
#!/bin/bash
my_array=(A B "C" D)
我们也可以使用下标来定义数组:
array_name[0]=value0
array_name[1]=value1
array_name[2]=value2
(2)读取数组
读取数组元素值的一般格式是:
${array_name[index]}
实例
#!/bin/bash
my_array=(A B "C" D)
echo "第一个元素为: ${my_array[0]}"
echo "第二个元素为: ${my_array[1]}"
echo "第三个元素为: ${my_array[2]}"
echo "第四个元素为: ${my_array[3]}"
执行脚本,输出结果如下所示:
$ chmod +x test.sh
$ ./test.sh
第一个元素为: A
第二个元素为: B
第三个元素为: C
第四个元素为: D
9.shell脚本中重定向
针对于上面提到的sqoop抽取数据的脚本,工作中是使用azkaban做任务调度。但是有时候做其他的定时任务也使用crontab做来任务调度
比如下面的数据蛙课程案例,每天定时发送邮件的定时任务
35 8 * * * /root/anaconda3/bin/python3.6 /root/project/datafrog/datafrog_adventure.py >/tmp/load.log 2>&1 #邮件发送by 数据蛙
这个里面就涉及到了shell脚本中的重定向,下面一起看看把
我们先来看下linux命令的执行过程
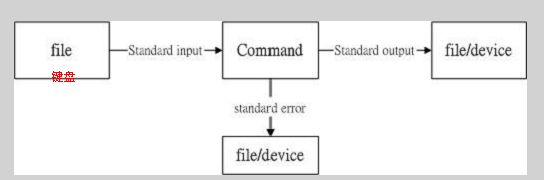
我们一起来看下,比如说一条linux命令
一开始可能需要给这个命令一个输入值,这个就叫标准输入(Standard input),简写stdin
,其中可以通过键盘或者是文件的形式给命令一个输入接着就开始执行命令,命令执行成功,就会把成功的结果输出到屏幕上来,这个就叫标准输出(standard output),简写stout
若是命令行执行错误,就会把报错的结果输出到屏幕上来,这个就叫做标准错误(standard error),简写stderr
有时候我们在命令使用时,若不想命令的执行结果输出的屏幕,需要输入输出到制定文件或者设备,就需要使用输入、输出重定向。
先看下输出重定向的例子
#默认情况下,stdout和stderr默认输出到屏幕
[root@st ~]# ls ks.cfg wrongfile
ls: cannot access wrongfile: No such file or directory
ks.cfg
#标准输出重定向到stdout.txt文件中,错误输出默认到屏幕。1>与>等价
[root@st ~]# ls ks.cfg wrongfile >stdout.txt
ls: cannot access wrongfile: No such file or directory
[root@st ~]# cat stdout.txt
ks.cfg
#标准输出重定向到stdout.txt,错误输出到err.txt。也可以使用追加>>模式。
[root@st ~]# ls ks.cfg wrongfile >stdout.txt 2>err.txt
[root@st ~]# cat stdout.txt err.txt
ks.cfg
ls: cannot access wrongfile: No such file or directory
#将错误输出关闭,输出到null。同样也可以将stdout重定向到null或关闭
# &1代表标准输出,&2代表标准错误,&-代表关闭与它绑定的描述符
[root@st ~]# ls ks.cfg wrongfile 2>&-
ks.cfg
[root@st ~]# ls ks.cfg wrongfile 2>/dev/null
ks.cfg
#将错误输出传递给stdout,然后stdout重定向给xx.txt,也可以重定向给null。顺序为stderr的内容先到xx.txt,stdout后到。
[root@st ~]# ls ks.cfg wrongfile >xx.txt 2>&1
#将stdout和stderr重定向到null
[root@st ~]# ls ks.cfg wrongfile &>/dev/null
注意关于2>&1的理解
- 含义:将标准错误输出重定向到标准输出
- 符号>&是一个整体,不可分开,分开后就不是上述含义了。比如有些人可能会这么想:2是标准错误输入,1是标准输出,>是重定向符号,那么"将标准错误输出重定向到标准输出"是不是就应该写成"2>1"就行了?是这样吗?如果是尝试过,你就知道2>1的写法其实是将标准错误输出重定向到名为"1"的文件里去了
- 写成2&>1也是不可以的
输入重定向
#从stdin(键盘)获取数据,然后输出到catfile文件,按Ctrl+d结束
[root@st ~]# cat >catfile
this
is
catfile
[root@st ~]# cat catfile
this
is
catfile
#输入特定字符eof,自动结束stdin
[root@st ~]# cat >catfile < this
> is
> catfile
> eof
[root@st ~]# cat catfile
this
is
catfile
如果大家正在学习shell脚本使用的话,不防好好读下sqoop抽取数据的脚本,通过实际的案例学习,成长速度会更快些