线段树Segment Tree
对于有一类问题,时常关注的是一个区间或者是一个线段,那么就可以使用线段树来解决。比较经典的问题,就是区间染色问题:有一面墙,长度为n,每次选择一段墙来染色,一开始4-6绘制成黄色,然后1-10绘制蓝色,2-7绘制红色,若干次绘色之后能看见多少种颜色,或者是在区间「i,j」区间里面可以看到多少种颜色。所以主要有两个操作,染色操作和查询操作。使用数组操作其实是可以的,染色就只需要把对应下标的内容,修改就好了;查找只需要遍历,这样复杂度就都是,这样很明显效率是不够的。
实质的应用就是区间查询,比如统计2017年的消费最高的用户,或者是某一个太空区间天体的总量。使用线段树的之后:
| 使用数组实现 | 使用线段树实现 | |
|---|---|---|
| 更新 | ||
| 查询 |
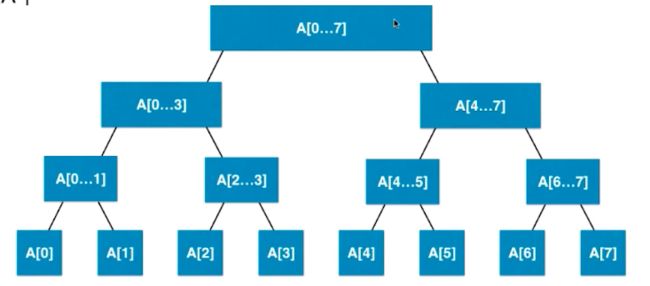
线段树大致的样子。 可以看到线段树不是完全二叉树,因为如果是十个元素,是不一定都集中在左边的,这时候就不一定是完全二叉树了,但是一定是平衡二叉树。平衡二叉树的定义是,最短深度和最大深度的差只能为1,也就是不能超过1。虽然不是完全二叉树,但是依然可以用数组来表示,将下面的空节点全部补全,这样这棵树就变成满二叉树了。如果区间有n个元素,而
Create
创建线段树其实很简单,可以看到上面是对半分开。
private int leftChild(int index) {
return 2 * index + 1;
}
private int rightChild(int index) {
return 2 * index + 2;
}
求左右子树的下标。
public class SegmentTree {
private E[] data;
private E[] tree;
private Merger merger;
public SegmentTree(E[] arr, Merger merger) {
this.merger = merger;
data = (E[]) new Object[arr.length];
for (int i = 0; i < arr.length; i++) {
data[i] = arr[i];
}
tree = (E[]) new Object[4 * arr.length];
buildSegmentTree(0, 0, data.length - 1);
}
data是传进来的数据,tree是树的数据merger是操作。还是递归,因为树这种数据结构用起递归是天然的方便。参数要有两个主要的参数,左边和右边的边界,其实按照上面的图就是中分。当l >= r的时候就是递归的最终条件,这个时候直接相等即可,否则就递归构建。
private void buildSegmentTree(int treeIndex, int l, int r) {
if (l >= r) {
tree[treeIndex] = data[l];
return;
} else {
int leftTreeIndex = leftChild(treeIndex);
int rightTreeIndex = rightChild(treeIndex);
int mid = l + (r - l) / 2;
buildSegmentTree(leftTreeIndex, l, mid);
buildSegmentTree(rightTreeIndex, mid + 1, r);
tree[treeIndex] = merger.merger(tree[leftTreeIndex], tree[rightTreeIndex]);
}
}
merger是一个接口,这是因为如果把这个功能写死了,那么线段树的功能就死了。比如求和,如果写死了那么这个树就只能求和。而如果加上了接口,最小值最大值也是可以的。线段树其实也是一种空间换时间的做法。
public static void main(String[] args) {
Integer[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
SegmentTree segmentTree = new SegmentTree(arr, (a, b) -> a > b?a:b);
segmentTree.show();
}
查找最大值。Merger就是就是一个接口,具体实现是看业务需求。
Query
线段树是二分的,那么这个时候如果要查找的区间并不是是刚刚好二分的一边那就需要一个区间找一点一个区间找一点这样的来组合了。比如找A[2,5],那么[0,3]找一边,[4,7]找一边就好了。
同样是使用递归实现,首先参数要包含的就是树的边界和要求的边界,如果边界是完全一样的,直接把当前树对应的值返回即可,如果边界是在左边,那就递归左边找,右边就右边找,两边都包含还是递归相加返回即可。
ry(int queryL, int queryR) {
if (queryL < 0 || queryL >= data.length || queryR < 0 || queryR >= data.length || queryL > queryR) {
throw new IllegalArgumentException("permater is illgel!");
}
return query(0, 0, data.length - 1, queryL, queryR);
}
private E query(int treeIndex, int l, int r, int queryL, int queryR) {
if (l == queryL && r == queryR) {
return tree[treeIndex];
}
int mid = l + (r - l) / 2;
int left = leftChild(treeIndex);
int right = rightChild(treeIndex);
if (queryL >= mid + 1) {
return query(right, mid + 1, r, queryL, queryR);
} else if (queryR <= mid) {
return query(left, l, mid, queryL, queryR);
} else {
return merger.merger(query(left, l, mid, queryL, mid), query(right, mid + 1, r, mid + 1, queryR));
}
}
Leecode303

这道题目其实就可以用刚刚的线段树解决,使用上面的线段树就可以直接解决。但其实这并不是最好的解决方法,因为这个题目在前面是要求有一个构造函数的,联想到在ACM这些题目中有一种方法就是打表法,打表时间是不计入时间的,使用这个时候就可以在构造函数的时候计算迭代元素的和即可,比如存到了第4个元素,那么第四个元素这个空就不存第四个元素,而是存第四个元素前面的和,包括了第四个元素,也就是[0,4]的和,这样计算的时候只需要一次减法即可。但是这里学到了SegmentTree就直接用了
public class NumArray {
private SegementTree segementTree;
public NumArray(int[] nums) {
segementTree = new SegementTree(nums);
}
public int sumRange(int i, int j) {
if (segementTree == null){
return 0;
}
return segementTree.query(i, j);
}
public static void main(String[] args) {
int[] nums = {-2, 0, 3, -5, 2, -1};
NumArray numArray = new NumArray(nums);
// System.out.println(numArray.sumRange(0, 2));
}
}
Update
再来看一道题目:

这个题目和上一个题目是有相似之处的,但是不同的是它是要求可变的,也就是涉及到了线段树的可变操作。
线段树的更新其实最简单的。首先参数肯定是更新的索引和变量,递归寻找索引所存在的树,找到之后不论左右子树有没有改变,全部重新相加即可。更新还是查找复杂度都会是
public void set(int index, E e) {
if (index < 0 || index >= data.length) {
throw new IllegalArgumentException("index is illgel!!!");
}
data[index] = e;
set(0, 0, data.length - 1, index, e);
}
private void set(int treeIndex, int l, int r, int index, E e) {
if (l == r){
tree[treeIndex] = e;
return;
}
int mid = l + (r - l)/2;
int left = leftChild(index);
int right = rightChild(index);
if (index <= mid){
set(left, l, mid, index, e);
}else if (index > mid){
set(right, mid+1, right, index, e);
}
tree[treeIndex] = merger.merger(tree[left], tree[right]);
}
上面那个题目也是一样的,只需要在update里面添加set函数即可。
二维线段树
这里介绍其实是一维的线段树,还存在有二维的线段树。一维的意思就是我们处理的就是一个一维的数据,也就是一条线上。同样把这个思想扩充到二维空间: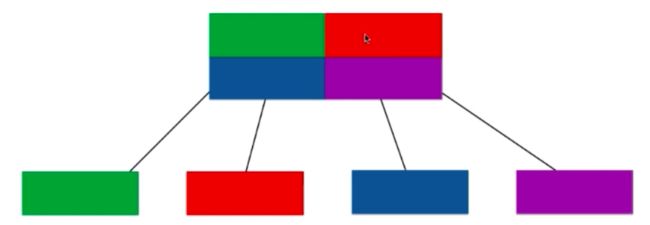
线段树只是一种设计思想,三维就分成八个,也是一样的。另外,这里的线段树区分是使用平均操作,但是有时候在某一个区间访问很少,再某一个区间很多,这样就可以不均分,也叫动态线段树。
字典树Trie
之前所讨论的树都是二叉树,无论是搜索时还是线段树,或者是后面要讲的红黑树都是二叉树,而字典树是多叉树。通常字典树是用来处理字符串。比如有20万个字符,要进行查询,如果是用树结构基本就是,但是如果用字典树,这复杂度和数量没有关系了,只和你查询的这个字符串的长度有关。
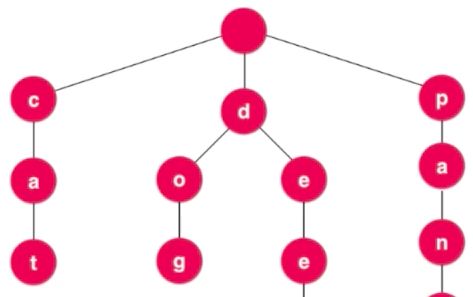
当遍历到叶子,那么就遍历出了一个单词。在设计节点的时候,按照常规操作,还是要存储节点内容,和指向下一个节点的指针。但是要注意,在查询的时候,我们是直接知道了下一个字符,也就是在查找之前就已经知道下一个字母了,和查字典一样,所以是并不需要当前节点的内容。如果一个单词是另一个单词的结尾,那么有可能就不是叶子节点了,所以还需要一个标识来标识这个是不是单词结尾。
Create
创建字典树就比较简单了,之前提到,需要标识和指向下一个节点,由于这个节点数量是不知道的,所以用映射来替代。
public class Trie {
private class Node {
public boolean isWord;
public TreeMap next;
public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
}
public Node() {
this(false);
}
}
private Node root;
private int size;
public Trie() {
root = new Node();
this.size = 0;
}
add
添加元素也很简单,添加的时候遍历字符串下一个字符,通过这个字符找到下一个节点,如果到了最后一个,那么就要设置标识,表示这个是一个单词。但是这里有一个小陷阱,有可能有插入重复单词,这个时候就需要判断标识来维护size了。
public void add(String word) {
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
cur.next.put(c, new Node());
}
cur = cur.next.get(c);
}
if (!cur.isWord) {
cur.isWord = true;
size++;
}
}
Selection
查找方法其实也很简单,首先看看当前next的映射里面有没有当前要查找的字符,如果没有,直接就返回false,如果有就留下。当遍历到最后一个的时候不能直接返回true,因为如果标识不是true,那么只能说明是恰好有这个单词在,而不是有这个单词,这个单词可能是刚刚好是某一个单词的前缀而已。
public boolean contains(String word) {
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) != null){
cur = cur.next.get(c);
}else {
return false;
}
}
return cur.isWord;
}
前缀搜索
电话本的搜索如果你打入一个字母,就可以出现前面单词是这个字母的所有人,这个就是前缀搜索,数据库也有这样的搜索。
其实和之前的搜索没有什么差别:
public boolean isPrefix(String word){
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null){
return false;
}
cur = cur.next.get(c);
}
return true;
}
Leecode208
Leecode里面有一道这样的题目,就是实现字典树:
和之前所实现的完全一样,直接替换一下即可。
Leecode211

和以往的不同,这个题目添加了类似于正则表达式的匹配,点代表任何字符。其他都差不多,就是搜索不一样。遇到点自然就是要遍历所有的可能了。使用递归实现比较简单,首先是判断边界条件,如果要比较的索引已经是最后一个字符了,那就直接返回标识。标识有的才能算有。如果不是,那就要递归访问了,是具体字符,就和之前的查找一样,如果是".",遍历所有下一个节点的字符,只要有一个符合那就可以继续,如果都没有或者是空,那么久可以返回false了。
private boolean match(Node node, String word, int index) {
if (index == word.length()) {
return node.isWord;
}
char c = word.charAt(index);
if (c != '.') {
if (node.next.get(c) == null) {
return false;
} else {
return match(node.next.get(c), word, index + 1);
}
} else {
for (char key : node.next.keySet()) {
if (match(node.next.get(key), word, index + 1)) {
return true;
}
}
return false;
}
}
Trie作为map使用
这个题目要求计算包含前缀的单词的权值相加是多少。用递归很容易可以解答。首先要确认前缀在这个字典树里面有的,然后再前缀的基础上把后面的单词全部加起来即可。因为我们关注的是value值而不是单词,所以不需要Word,也就是标识,有没有都无所谓,value为0就没有单词,也可以替代的。
public int sum(String prefix) {
Node cur = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (cur.next.get(c) == null){
return 0;
}
cur = cur.next.get(c);
}
return sum(cur);
}
private int sum(Node cur){
int res = cur.value;
for (char key : cur.next.keySet()){
res += sum(cur.next.get(key));
}
return res;
}
}
最后的递归看起来好像没有判断递归到底的条件,但是实际上已经包含了,当节点的下一个是空的时候,就不经过for循环了,就可以直接返回。
AVL树
对于二叉树,有时候会存在一些比较极端的情况,如果按照顺序插入,就会变成类似链表那种情况,这个时候就复杂度就会回到n了,没有体现出树的优势。所以在插入的时候,我们需要维持树的结构。比较经典的平衡二叉树之一就是AVL树了。
平衡二叉树
首先声明是平衡二叉树,首先满的二叉树肯定是一棵平衡二叉树,平衡二叉树可以使得树的高度可以达到一个最低的高度。线段树也是一个平衡二叉树。在AVL里面,任意一个节点左右节点高度差不不能超过1。所以需要标注每一个节点的高度,高度可以从底层开始计算,有了高度,那么就可以计算平衡因子,平衡因子其实就是两棵左右子树的高度差,如果高度差没有超过1那么就算是平衡了。
添加操作
出现不平横的时候只有两种情况,一个就是添加的时候,另一个就是删除的时候。插入的时候,需要向上维护平衡性。
1.插入的元素是在不平衡节点的左侧的左侧。也就是一直向左侧插入元素。
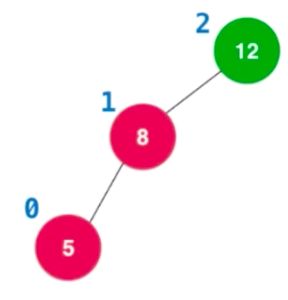

可以看到,这种情况下首先当前节点的平衡因子一定大于0,其次左侧孩子的平衡因子是大于等于0。第一个条件很好理解,二叉树不平衡的条件,第二个条件是因为,既然是左侧多添加了一个节点,左边肯定比右边高,而平衡因子在这里计算的是左边减去右边,所以肯定是大于等于0的了。事实上应该只有大于0,因为等于0的话,那就意味着左边子树单独拿出来是平衡的,但是如果是平衡又要比右边子树多的话,那就意味着要比右边多数两个,但是多出一个的时候就已经需要改变的了,所以应该只是大于0,然而,这只是在添加的情况下有,删除就不一定了,比如上面情况,右边子树的有一个右子树,删除的时候刚刚高把那个右子树删了,而左边恰好等于0,那么还是需要换的。另外,还有一个更重要的原因,当左子树等于0的时候,或者是右子树等于0的时候,进行的旋转只能是左旋转,或者右旋转,当然对应的前提条件是当前节点是左边导致的不平衡或者是右边。**这个时候一个要进行右旋转。 **
右旋转

5对应的右节点接到7的左节点上,旋转完之后还需要更改高度,先更改子树的高度再更改节点高度。
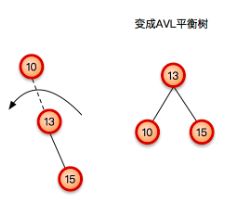
2.插入的元素是右子树的右子树,也就是一直向右侧插入元素。
这个时候就应该是右侧子树导致的,一直向右侧插入元素,那么右子树的右边肯定也多出来了。所以就需要左旋转。
左旋转
3.如果是往左子树的右子树插入了导致不平衡,那么一次旋转是不可以的了。这种情况下只能回到我们之前解决过的情况处理,可以通过先把当前节点的左节点进行左旋转变成情况一,再对当前节点进行右旋转即可。所以就是先对左子树进行左旋转,再对当前节点进行右旋转。
4.如果是往右子树的左节点添加导致了不平衡,那么就需要先右旋转再进行左旋转即可。和上面的情况其实是两两对应的。
public Node add(Node node, K key, V value) {
if (node == null) {
size++;
return new Node(key, value);
}
if (key.compareTo(node.key) > 0) {
node.right = add(node.right, key, value);
} else if (key.compareTo(node.key) < 0) {
node.left = add(node.left, key, value);
} else {
node.value = value;
}
node.height = 1 + Math.max(getHeight(node.left), getHeight(node.right));
int balanceFactor = getBalanceFactor(node);
if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0) {
return rightRotate(node);
}
if (balanceFactor < -1 && getBalanceFactor(node.right) <= 0) {
return leftRotate(node);
}
if (balanceFactor > 1 && getBalanceFactor(node.left) < 0) {
node.left = leftRotate(node.left);
return rightRotate(node);
}
if (balanceFactor < -1 && getBalanceFactor(node.right) > 0) {
node.right = rightRotate(node.right);
return leftRotate(node);
}
return node;
}
先添加元素,添加完之后再依照上面的情况进行调整。
删除操作
删除的时候,维护其实是一样的。 上面实际上已经列举了所有的不平衡的情况,所有这里只需要在删除的时候添加葛总不平衡的情况即可。
总结
在AVL树中还可以进行优化,每一次查询和删除都是达到了logn的时间复杂度。但是每一次更新都需要维护高度,如果当前节点是没有改变高度的话,其实是不需要维护上层节点的高度的了。因为从祖先节点来看,子树高度是没有变化的。AVL树还有一种优化结构,就是红黑树这种数据结构。
红黑树
树的平衡
树的平衡是指树的每一个节点的左右子节点的数目大致一样。两边都相等是最好的,当然这种情况很少见,一般都是两边大致相等。比如在二叉搜索树的时候,如果插入的数字是有顺序的,那么就容易退化成极其不平衡的链表,搜索复杂度就会变成了。所以对于插入顺序不是平衡的时候,之前所学过的二叉树就不再是一种好的数据结构了。这个时候就要使用红黑树了,红黑树其实也是一种二叉树,只不过是增加了某种特性的二叉树。如果在插入或删除的时候如果出现了不平衡的状态,那么就要进行调整,保持树的平衡。
红黑树的特征
首先每一个节点都有颜色,在删除和添加的过程中是需要保持这些颜色的排列规律。从2-3树来看。2-3树是满足二分搜索树的基本性质的。但是2-3树不是二叉树,节点可以存放一个元素或者是两个元素。

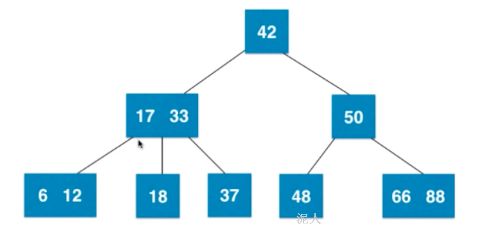
那么2-3树是如何维持绝对平衡的?
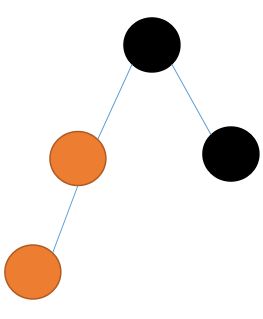
首先添加一个节点42,如果是空节点,那么就直接添加作为根节点,这个时候只有一个节点的树是一个平衡树。再添加一个37节点,按照二叉树的常规操作,应该和当前节点比较,看看添加到哪里合适,但是对于2-3树不是,它永远不会添加到一个空的节点,会添加到最后一个叶子节点上,现在只有一个根节点,所以就需要和42融合,形成了一个[37,42]的节点。再添加一个12,12比他们都要小,所以应该添加到左子树去,永远不会去空的位置,所以还得需要融合,虽然这个融合不符合规矩,但是先进行融合等等处理,这个时候就出现了4节点[12,37,42]。由于不符合规矩,所以可以很容易的就分裂成三个节点。中间节点是37,左右两边分别是12和42。再次添加一个18节点,应当添加在左边,所以自然就添加在了12这个叶子节点上面,满三个自然就分裂。当添加到第二层的时候再分裂就是这个样子:但是可以看到,其实不是绝对平衡的。如果一个叶子节点本来就是三节点,添加到一个新的节点变成四节点在进行拆解的时候,就需要和它的父亲节点融合。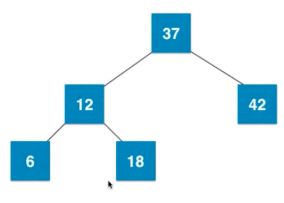 所以在整一个添加过程中,2-3树的结构是绝对平衡的。然而还有一种情况:
所以在整一个添加过程中,2-3树的结构是绝对平衡的。然而还有一种情况: 按照常规操作,上浮融合,自然根节点也要进行融合分裂:
按照常规操作,上浮融合,自然根节点也要进行融合分裂:

很明显还是一个平衡的,所以在整一个添加过程中是绝对平衡的。 在叶子节点达到四节点的时候就需要一步一步往上堆,一直到根节点。
红黑树的规则
1.每一个节点不是红色就是黑色。
2.根节点总是黑色。
3.如果节点是红色,那么子节点一定是黑色。但是黑色节点下面的子节点可以是红色也可以是黑色。
4.每一个叶子节点,这里的叶子节点不是指有数值的叶子节点,而是指最后的空节点叫做叶子节点,也就是null节点是黑色的。
5.从任意一个节点到叶子节点经过的黑色节点是一样的。

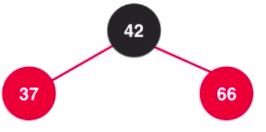
这些规则直接提出来不好理解,来看看对应于2-3树是怎么理解的。首先看看红黑树颜色在2-3树中是代表了什么意义,如果叶子节点是红色,那么就代表这个节点和根节点是融合在一起的,黑色就是分开,这个性质很重要。在红黑树中根节点一定是黑色,那么一开始添加的42就是黑色的,然后添加了一个37,这样这两个节点就对应了2-3树的三节点,来了12后红黑树的形状:


这是一种情况,第二种情况就是再添加的时候节点是合并在了叶子节点上:

再回到上面的几个规则,如果一个根节点是黑色,叶子节点一定是红色,这是因为只有红色才代表了融合,这个时候就是一个三节点了。最后一个经过同等数量的黑色节点,其实就是经过了2-3树的节点,因为二三树是绝对平衡的,所以红黑树也有这个性质。至于为什么每一次添加都是红色节点,是因为2-3树永远不会添加到空节点,会产生融合,所以添加红色节点代表融合。
添加操作
添加的时候,添加的节点将是红色的,从2-3树的角度来理解,因为加入的叶子节点是不能插入到空节点的,所以自然是红色代表融合了。从红黑树本身的增删功能来看,添加红色是最保险的方法,因为红黑树是看黑色节点的数量来保持平衡的,直接添加黑色一定会导致不平衡,因为会有一条路多了一个黑色,本来是平衡的,加了一个另外的势必不平衡。所以设置成红色是影响最小的。
红黑树的修正手段也就几种,首先就是改变颜色了,然后就是执行旋转操作。

添加修正的情况有三种,其实对应的就是上面提到的三个情况了:
①插入的是根节点,那么直接就可以把当前节点变成黑色了,对照规则一,根节点为黑色。同时在2-3树中黑色代表单个节点,这是自然的了。
②父节点是黑色,这种情况下是没有违反任何规则,完美度过。
③当父节点是红色,叔叔节点也是红色的时候,就需要处理了,添加的节点本身就是红色,父亲又是红色,这就违反了性质4。由于是连续的两个黑色,那么只需要把父节点设置成黑色就好了,但是设置黑色会违反性质5,所以是行不通的。


④当父节点是红色,叔叔节点为黑色,插入的节点是父节点的左孩子。
⑤当父节点是红色色,叔叔节点是黑色,插入为右孩子。

总的来说,就是对应着2-3树的分裂过程,只不过对应的结构不同可能有所差异。

删除操作
这个操作,有有点复杂了。
①删除的就是本身的根节点,而且根节点左右子树是空的。直接删就好了,没有上面好讲的。
②如果删除的节点是红色的,那么它的父亲节点就一定是黑色的。因为是红色的,直接拿孩子节点补充就好了,因为是没有影响的。
③如果删除节点是黑色的,而且兄弟节点是红色的,兄弟节点的孩子节点是黑色,删除节点的父亲节点也是黑色的。

④如果删除节点是黑色,父节点和兄弟节点以及兄弟节点的孩子都是黑色。

⑤删除的节点为黑色,父亲节点为红色,兄弟节点和兄弟节点的孩子为黑色

⑥删除的节点是黑色,兄弟节点也是黑色,兄弟孩子的左节点是红色,兄弟节点的右子树为黑色,父亲节点随便颜色。

⑦删除的节点是黑色,兄弟节点也是黑色,兄弟节点的右孩子为红色,父亲节点和兄弟节点左孩子随便颜色。
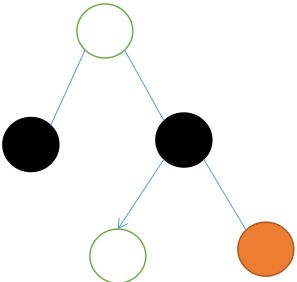

那么只是有一条路要跟新了,也就是经过兄弟节点的右子树那条,红色那条。之前是经过了父节点-》兄弟节点-》兄弟节点的右节点,现在只是经过了兄弟节点和右节点,明显是少了一个黑色节点,很显然,该黑色就OK了,所以上图是最终改完的结果,之所以说错了只是还没到说到那一步。
要注意的是,在很多的博客文章中,删除情况有所区别,有五种的也有四种的,这里是五种的,四种的是因为把第四和第五中情况和起来了。四种的话应该是这么写,兄弟节点和孩子全是黑色,把兄弟节点变成红色,当前节点切换到父节点重新向上判断。这里只是把父节点分开了。本质是完全一样的。

红黑树的实现
代码不太好,实现起来有点复杂,哎!
private class Node> {
public boolean color;
public T key;
Node left;
Node right;
Node parent;
public Node(T key, boolean color, Node parent, Node left, Node right) {
this.key = key;
this.color = color;
this.parent = parent;
this.left = left;
this.right = right;
}
public T getKey() {
return key;
}
@Override
public String toString() {
String s = "" + key + (this.color == RED ? "R" : "B");
if (this.left != null) {
s += (" " + left.key);
}
if (this.right != null) {
s += (" " + right.key);
}
return s;
}
}
由于带上了父母节点,用递归实现带父母节点的维护,就有点难度了。
首先添加操作的更新,添加操作使用的是迭代实现,篇幅较大,不贴了。
private void insertFixUp(Node node) {
Node parent, grandParent;
while ((parent = parentOf(node)) != null && isRed(parent)) {
grandParent = parentOf(parent);
if (parent == grandParent.left) {
//third condition,the uncle is red
Node uncle = grandParent.right;
if (uncle != null && isRed(uncle)) {
setBlack(uncle);
setBlack(parent);
setRed(grandParent);
node = grandParent;
continue;
}
//fifth condition,the uncle is black and left child of the current node
if (parent.right == node) {
Node temp;
leftRotate(parent);
temp = parent;
parent = node;
node = temp;
}
//fourth condiction,same as above but the right child of the current node.
setBlack(parent);
setRed(grandParent);
rightRotate(grandParent);
} else {
//third condition,the uncle is red.
Node uncle = grandParent.left;
if (uncle != null && isRed(uncle)) {
setBlack(uncle);
setBlack(parent);
setRed(grandParent);
node = grandParent;
continue;
}
//fifth condition,the uncle is black,left child
if (parent.left == node) {
Node temp;
rightRotate(parent);
temp = parent;
parent = node;
node = temp;
}
//fourth condition,the uncle is black,right child
setBlack(parent);
setRed(grandParent);
leftRotate(grandParent);
}
}
setBlack(root);
}
每一次处理完一种情况之后要记得更新当前节点node的信息,因为处理完后不一定就结束了,可能是更新到了一种新的情况。
删除操作的更新,这个有点复杂。
private void removeFixUp(Node node, Node par) {
Node uncle;
Node parent;
parent = node == null ? par : node.parent;
while ((node == null || isBlack(node)) && node != root) {
if (parent.left == node) {
uncle = parent.right;
//the uncle is red, condition three
if (isRed(uncle)) {
setBlack(uncle);
setRed(parent);
leftRotate(parent);
uncle = parent.right;
}
//the uncle and his child are all black
if ((uncle.left == null || isBlack(uncle.left)) &&
(uncle.right == null || isBlack(uncle.right))) {
setRed(uncle);
node = parent;
parent = parentOf(node);
} else {
//the uncle is black and red of his child on the left
if (uncle.right == null || isBlack(uncle.right)) {
setBlack(uncle.left);
setRed(uncle);
rightRotate(uncle);
uncle = parent.right;
}
setColor(uncle, colorOf(parent));
setBlack(parent);
setBlack(uncle.right);
leftRotate(parent);
node = this.root;
break;
}
} else {
uncle = parent.left;
if (isRed(uncle)) {
setBlack(uncle);
setRed(parent);
rightRotate(parent);
uncle = parent.left;
}
if ((uncle.left == null || isBlack(uncle.left)) &&
(uncle.right == null || isBlack(uncle.right))) {
setRed(uncle);
node = parent;
parent = parentOf(node);
} else {
if (uncle.left == null || isBlack(uncle.left)) {
setBlack(uncle.right);
setRed(uncle);
leftRotate(uncle);
uncle = parent.left;
}
setColor(uncle, colorOf(parent));
setBlack(parent);
setBlack(uncle.left);
rightRotate(parent);
node = this.root;
break;
}
}
}
if (node != null) {
setBlack(node);
}
}
每次处理完后也要记得更新节点的信息,第一种情况更新完的时候,uncle节点不再是原来的了,所以要进行更新。第二种情况也是,由于处理节点已经切换到了父亲节点,于是要对父亲节点切换,第三种情况uncle节点也发生了改变,同样要切换。第四种情况直接结束。
最后附上GitHub及其代码:https://github.com/GreenArrow2017/DataStructure_Java/tree/master/out/production/DataStructure_Java/Tree