1. 目的:通过分析和挖掘推特上的推文,来尽可能准确的判断其对苹果公司的态度(积极、消极、或者为其他)。
2. 数据来源: Twitter API;构建因变量方法:Amazon Mechanical Turk;自变量为推文内容。
Amazon Mechanical Turk: 亚马逊Mechanical Turk是一个众包市场,使个人或企业能够使用人工智能来执行计算机当前无法执行的任务。作为全球最大的众包市场之一,Mechanical Turk提供按需、可扩展的员工队伍,将创业公司、企业、研究人员、艺术家、知名科技公司和政府机构与个人联系起来,以解决计算机视觉、机器学习、自然语言处理等方面的问题。
tweets <- read.csv("tweets.csv", stringsAsFactors=FALSE)
View(tweets)

str(tweets) # 查看数据结构

创建因变量
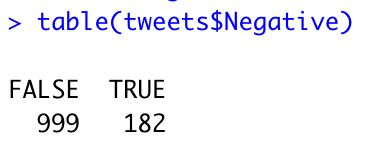
tweets$Negative = as.factor(tweets$Avg <= -1) table(tweets$Negative)
3. 数据预处理:词袋模型(bag of words)
创建语料库
corpus <- VCorpus(VectorSource(tweets$Tweet)) # VCorpus() creates volatile corpora. # VectorSource(): A vector source interprets each element of the vector x as a document. # Look at corpus corpus corpus[[1]]$content
# output: [1] "i have to say, apple has by far the best customer care service i have ever received! @apple @appstore"
3.1 将字母全部转为小写(irregularities)
# Convert to lower-case corpus <- tm_map(corpus, content_transformer(tolower)) corpus[[1]]$content
# output: [1] "i have to say, apple has by far the best customer care service i have ever received! @apple @appstore"
3.2 去除所有标点符号(punctuation)
# Remove punctuation corpus <- tm_map(corpus, removePunctuation) corpus[[1]]$content
# output: [1] "i have to say apple has by far the best customer care service i have ever received apple appstore"
然而,有时候标点符号是有意义的。比如,在Twitter中,@Apple代表向Apple发消息;#Apple代表这是关于Apple的信息;此外,标点符号对于网址来说有重要意义。
3.3 去除停用词表(stop words)
停用词表指的是不太可能帮助提升机器学习准确率的词汇的集合,例如:the, is, at, and which。因此,我们可以去除这些词来减少数据量。
# Look at stop words
stopwords("english")[1:10]
# output: [1] "i" "me" "my" "myself" "we" "our" "ours" "ourselves" "you" "your"
# Remove stopwords and apple
corpus <- tm_map(corpus, removeWords, c("apple", stopwords("english")))
corpus[[1]]$content
# output: [1] " say far best customer care service ever received appstore"
然而,去除停用词也有一些潜在问题。有时候,两个停用词连在一起可能有很重要的含义。例如,'The Who' 这两个停用词连在一起,是一个乐队的名称。
3.4 只保留词根(stemming)
当同一个单词结尾不同,但是却代表相同的含义的时候,我们可以通过只保留这些单词词根的方法来去掉冗余。例如argue, argued, argues, 以及 arguing代表的是相同的含义,但是被按照不同的单词来计数,因此可以通过只保留词根的方法,让他们用一个共同的词根argu代替。
# Stem document corpus = tm_map(corpus, stemDocument) corpus[[1]]$content
# output: [1] "say far best custom care servic ever receiv appstor"
同样的,这个方法的不足之处在于,有些词具有相同的词根,但是不同的词尾具有不同的含义,如果删掉了,则会影响预测的准确性
3.5 创建单词频率矩阵
其中,每一行代表每一个观测值(tweets), 每一列对应推文中出现的一个单词,矩阵中的数值为每个单词在每个观测值中出现的频率(次数)。
# Create frequency matrix frequencies <- DocumentTermMatrix(corpus) frequencies
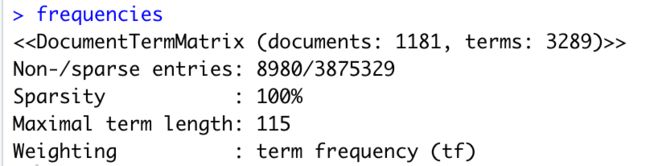
由此可见,frequencies中包含了1181个观测值和3289个单词。
查看矩阵
# Look at matrix inspect(frequencies[1000:1005,505:515])

查看高频词汇
# Check for sparsity findFreqTerms(frequencies, lowfreq=20) # lowfre = 20 means the terms that appear at least 20 times

我们可以发现,在3289个单词当中,只有56个词出现的频率不少于20次,因此我们可以去除一些低频词汇,因为这些低频词汇对于模型预测没有较大的帮助,且其存在会导致大量的计算,进而延长模型运算的时间。
# Remove sparse terms sparse <- removeSparseTerms(frequencies, 0.995) # sparsity threshold = 0.995 means only keep terms that appear in 0.5% or more of the tweets, sparse
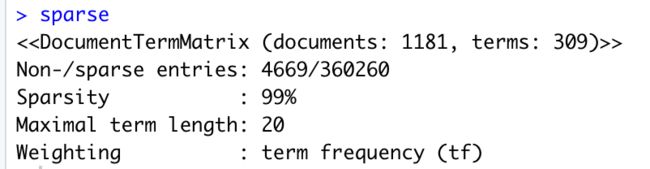
将低频词汇剔除后,sparse中只包含了309个观测值。
接下来,将matrix转化为data frame以便于构建预测模型;并确保data frame的列名是恰当的。
# Convert to a data frame that we'll be able to use for our predictive models. tweetsSparse <- as.data.frame(as.matrix(sparse))
# Make all variable names R-friendly # Since R struggles with variable names that start with a number, and we probably have some words here that start with a number. colnames(tweetsSparse) <- make.names(colnames(tweetsSparse))
添加因变量,并将数据分为测试集(70%)和训练集(30%)
# Add dependent variable tweetsSparse$Negative <- tweets$Negative # Split the data library(caTools) set.seed(123) split <- sample.split(tweetsSparse$Negative, SplitRatio = 0.7) trainSparse <- subset(tweetsSparse, split==TRUE) # 测试集 testSparse <- subset(tweetsSparse, split==FALSE) # 训练集
4. 构建预测模型
4.1 CART分类树模型
# Build a CART model library(rpart) library(rpart.plot) tweetCART <- rpart(Negative ~ ., data=trainSparse, method="class") prp(tweetCART)
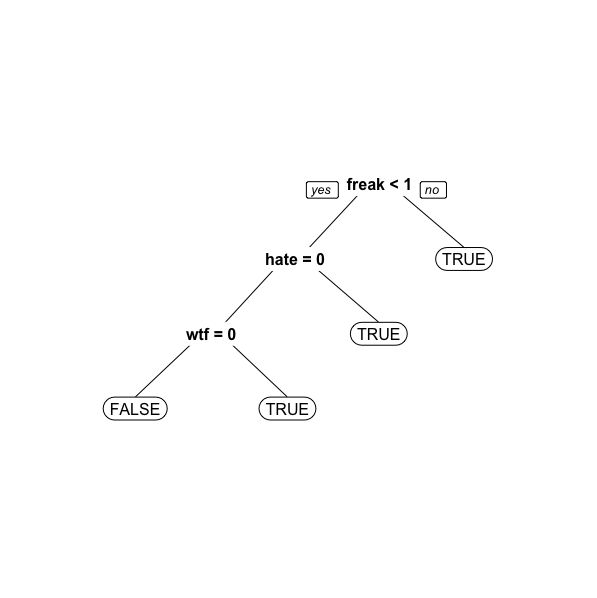
因此,当推文中出现freak、hate或者wtf任意一个词的时候,用户被划分为负面情绪;当推文中不包含这三个词的时候,推文不是负面情绪。
预测模型的准确性:
# Evaluate the performance of the model predictCART <- predict(tweetCART, newdata=testSparse, type="class") # Compute accuracy library(caret) confusionMatrix(predictCART, testSparse$Negative)

根据混淆矩阵的结果,将CART分类树模型应用到测试集,其准确性为87.89%。
# Baseline accuracy table(testSparse$Negative) # baseline accuracy is about 84.50704% = 300/(300+55)
因此,CART分类树模型在baseline的基础上,准确性有所提升(从94.5%提升至87.89%)。
接下来,考虑CART模型复杂性, 改进模型进而提升模型准确性
# consider cp value
tweetCART2 <- rpart(Negative ~ ., data=trainSparse, method="class", cp = 0.000001, minsplit = 5,
xval = 10)
printcp(tweetCART2)
prune.cart <- prune(tweetCART2, cp = 0.0236220)
prp(prune.cart)

根据改进的CART模型,当推文中出现freak、hate、wtf或者shame任意一个词的时候,用户被划分为负面情绪;当推文中不包含这三个词的时候,推文不是负面情绪。
# predict prune.cart.pred <- predict(prune.cart, newdata = testSparse, type = 'class') confusionMatrix(prune.cart.pred, testSparse$Negative)

根据混淆矩阵的结果,将改进的CART分类树模型应用到测试集,其准确性由87.89%提升至88.17%。
4.2 随机森林模型
# Random forest model library(randomForest) set.seed(123) tweetRF <- randomForest(Negative ~ ., data=trainSparse) # Make predictions: predictRF <- predict(tweetRF, newdata=testSparse) confusionMatrix(predictRF, testSparse$Negative)

将随机森林模型应用到测试集中,其准确性高达88.45%。然而,随机森林模型比改进后的CART模型解释性差很多,且改进后的模型准确性也高达88.17%。因此,更推荐改进后的CART模型。
4.3 逻辑回归模型
# logistic regression mode; tweetLog <- glm(Negative ~ ., data = trainSparse, family = 'binomial') predictions <- predict(tweetLog, newdata=testSparse, type="response") confusionMatrix(as.factor(predictions>0.5), as.factor(testSparse$Negative))

当cutoff为0.5时,模型准确性为80.28%,低于baseline准确性。
综上所述,在本案例中,推荐使用优化后的CART模型。