今天突然在网上看到了这本电子pdf,看见还有视频课程,不过课程貌似收费,心想着Python一直没怎么学,也没怎么用它来编程,今天趁着有空学一下吧。
首先浏览了一下目录,有几章还是挺感兴趣的,像 **chapter8 reading and writing files, chapter 10 debugging , chapter 11 web scraping. **
抱着想要看看这本书质量怎么样的心态,看了这本书看我能学到多少东西,查漏补缺,因为现在自己的python水平完全是菜鸟级别。。。等看完了,最后再评价这本书。
都说兴趣是最好的老师,只有抱着一种想要探索,想要把这个搞懂的心态,才能真正的学进去。**PS:只有当你对一个东西不感兴趣时,你才会使劲逼迫着自己去做这件事。如果你很喜欢,根本不需要所谓的自我约束,兴趣会驱动着你前行。**
If you can’t nd the answer by searching online, try asking people in aweb forum such as Stack Overlow (http://stackover ow.com/) or the “learnprogramming” subreddit at http://reddit.com/r/learnprogramming/.
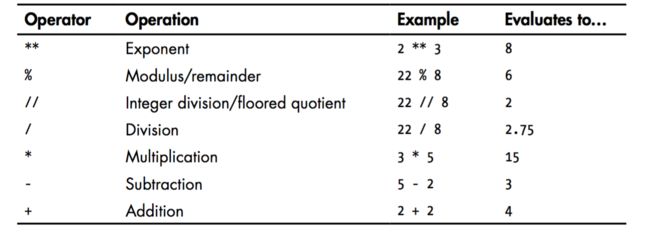
一些操作符,'//' 原来不知道是什么意思,现在知道了
\d 数字,\w 单词,字符串,\s 空格
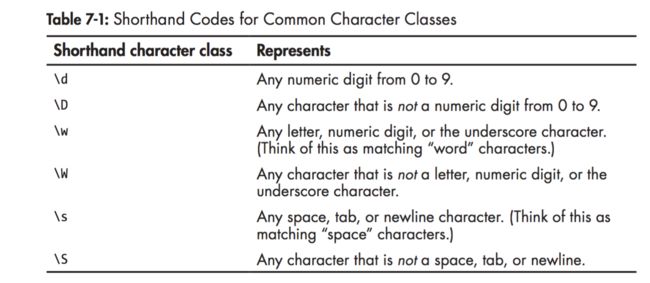
原来查linux的时候看到过这些正则表达式分别是什么,现在终于记住了。。。
PS:由此可见,自己的记性是有多差。。。

`
#manipulate strings
print('Hello there!\nHow are you?\nI\'m doing fine.')
#raw string
print(r'That is Carol\'s cat.')
#
spam='appLe'
spam.lower()
'hello'.isalpha()
'hello123'.isalnum()
'123'.isdecimal()
' '.isspace()
'Hello world!'.startswith('Hello')
' '.join(spam)
spam=' Hello World'
spam.strip()
spam.lstrip()
spam.rstrip()
import pyperclip
text = pyperclip.paste()
# Separate lines and add stars.
lines = text.split('\n')
for i in range(len(lines)):# loop through all indexes in the "lines" list
lines[i] = '* ' + lines[i] # add star to each string in "lines" list
pyperclip.copy(text)
pyperclip.copy()
pyperclip.paste()
#All the regex functions in Python are in the re module
import re
# re.compile() returns a Regex pattern object
phonenumber=re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo=phonenumber.search('my number is 150-021-18276')
print('phone number is found :'+mo.group())
mo.group(1)
mo.group(2)
mo.group(0)
mo.group()
mo.groups()
'''
1. Import the regex module with import re.
2. Create a Regex object with the re.compile() function.
(Remember to use a
raw string.)
3. Pass the string you want to search into the Regex object’s search() method.
This returns a Match object.
4. Call the Match object’s group() method to return a string of the actual
matched text.
'''
phonenumber.findall('cell:415-555-9999 work: 212-555-0000')
######
import os
os.getcwd()
os.chdir("/Users/apple")
os.makedirs('/Users/apple/python')
os.path.abspath('.')
totalSize=0
for filename in os.listdir('/Users/apple'):
toralSize+=os.path.getsize('/Users/apple',filename)
print(totalSize)
os.path.exists('/Users/apple')
os.path.isdir('/Users/apple')
os.path.isfile('/Users/apple')
#the shutil module
#The shutil (or shell utilities) module has functions to let you copy,
#move, rename, and delete les in your Python programs.
import shutil,os
shutil.copy('apple.txt','test.txt')
shutil.copytree('C:\\bacon', 'C:\\bacon_backup')#shutil.copytree() will copy an entire folder and every folder and le contained in it.
shutil.move('C:\\bacon.txt', 'C:\\eggs')
os.unlink(path) #will delete the le at path.
os.rmdir(path)#will delete the folder at path. This folder must be
empty of any les or folders.
shutil.rmtree(path)#will remove the folder at path, and all les and folders it contains will also be deleted.
import os
for filename in os.listdir():
if filename.endswith('.rxt'):
os.unlink(filename)
import os
for filename in os.listdir():
if filename.endswith('.rxt'):
#os.unlink(filename)
print(filename)
#A much better way to delete les and folders is with the third-party send2trash module.
send2trash.send2trash('bacon.txt')
os.walk()
#Reading ZIP Files
import zipfile, os
exampleZip = zipfile.ZipFile('example.zip')
exampleZip.namelist()
spamInfo = exampleZip.getinfo('spam.txt')
spamInfo.compress_size
exampleZip.close()
#Extracting from ZIP Files
exampleZip.extractall()
exampleZip.close()
exampleZip.extract('spam.txt', 'C:\\some\\new\\folders')
backupZip = zipfile.ZipFile(zipFilename, 'w')
#raising exceptions
import traceback
try:
raise Exception('This is the error information.')
except:
errorFile=open('errorInfo.txt','w')
errorFile.write(traceback.format_exc())
errorFile.close()
print('The traceback info was written to errorInfo.txt')
#An assertion is a sanity check to make sure your code isn’t doing something obviously wrong.
import logging
logging.basicConfig(level=logging.DEBUG, format=' %(asctime)s - %(levelname)s - %(message)s')
logging.debug()
logging.info()
logging.warning()
logging.error()
logging.critical()
logging.basicConfig(filename='myProgramLog.txt', level=logging.DEBUG, format=' %(asctime)s - %(levelname)s - %(message)s')
import webbrowser
webbrowser.open('http://inventwithpython.com')
import requests
res=requests.get('http://www.gutenberg.org/cache/epub/1112/pg1112.txt')
try:
res.raise_for_status()
except Exception as exc:
print('There was a problem:%s' % (exc))
type(res)
res.status_code==resquests.codes.ok
len(res.text)
print(res.text(:250))
playFile = open('RomeoAndJuliet.txt', 'wb')
for chunk in res.iter_content(100000):
playFile.write(chunk)
playFile.close()
`
###############file() 函数
file()函数是2.2中新增的函数,它与open()函数一样,相当于open()的别名,不过比open()更直观一些。
for line in file(filename):
print line
[#######对于为什么要用__name__='__main__' 参见文章:](http://www.crifan.com/python_detailed_explain_about___name___and___main__/)
写的很详细。一下就看懂了。
对于sys.argv 的用法参见文章:[sys.argv](http://blog.csdn.net/vivilorne/article/details/3863545)
写的很详细,学习了。把程序看懂,自己写一遍。
#Debugging
为了防止程序crash,可以把traceback information 写到log file里。
**Web Scrapping"
*webbrowser* :Comes with Python and opens a browser to a specific page.
*Requests*: Downloads les and web pages from the Internet.
*Beautiful Soup*: Parses HTML, the format that web pages are written in.
*Selenium*: Launches and controls a web browser. Selenium is able to ll in forms and simulate mouse clicks in this browser.