程序的栈空间有什么特点呢?首先会想到的就是,栈空间是往低地址增长的,当调用一个函数时,先开辟栈空间,用来存放当前函数的参数和局部变量;执行函数之前还需要先保护现场,当函数执行完之后会恢复现场。那么函数调用的过程中内存和CPU的寄存器到底发生了什么变化呢?这是本篇要探讨的问题。
先看一段C代码,定义了三个函数,调用关系为:funcA调用funcB, funcB调用funcC。
int funcA(int a, int b) {
int ret = funcB(a, b);
return ret;
}
int funcB(int a, int b) {
return funcC(a, b);
}
int funcC(int a, int b) {
int c = a + b;
return c;
}
从函数是否还调用了其他函数的角度看,函数可分为叶子函数、非叶子函数:
叶子函数:函数内部没有调用其他函数了,例如上面的funcC
非叶子函数:函数内部还调用了其他的函数,例如上面的funcA、funcB
为什么要这么划分呢?因为叶子函数与非叶子函数生成的汇编代码有所不同,这也是本篇要分析的一个点。
获取汇编代码
得到对应的汇编代码有两种方式
方式一:
用clang编译器把C代码编译为汇编代码,编译函数所在的.c文件即可
xcrun -sdk iphoneos clang -S -arch arm64 Ctest.c
指定架构为arm64,执行命令后会得到Ctest.s文件,就是对应的汇编代码了。
方式二:
新建一个iOS项目,并且运行在真机设备上,在真机上才是arm64架构的汇编哦。在三个函数分别打断点,把Xcode的debug模式设置为显示汇编模式,在Debug -> Debug Workflow -> Aways Show Disassembly设置。当函数断住时,会显示当前函数的汇编代码。
这里采用方式二,得到的汇编代码如下:
funcA
Assembly`funcA:
0x100086ab8 <+0>: sub sp, sp, #0x20 ; =0x20
0x100086abc <+4>: stp x29, x30, [sp, #0x10]
0x100086ac0 <+8>: add x29, sp, #0x10 ; =0x10
0x100086ac4 <+12>: stur w0, [x29, #-0x4]
0x100086ac8 <+16>: str w1, [sp, #0x8]
0x100086acc <+20>: ldur w0, [x29, #-0x4]
0x100086ad0 <+24>: ldr w1, [sp, #0x8]
0x100086ad4 <+28>: bl 0x100086aec ; funcB at Ctest.c:57
0x100086ad8 <+32>: str w0, [sp, #0x4]
0x100086adc <+36>: ldr w0, [sp, #0x4]
0x100086ae0 <+40>: ldp x29, x30, [sp, #0x10]
0x100086ae4 <+44>: add sp, sp, #0x20 ; =0x20
0x100086ae8 <+48>: ret
funcB
Assembly`funcB:
0x100086aec <+0>: sub sp, sp, #0x20 ; =0x20
0x100086af0 <+4>: stp x29, x30, [sp, #0x10]
0x100086af4 <+8>: add x29, sp, #0x10 ; =0x10
0x100086af8 <+12>: stur w0, [x29, #-0x4]
0x100086afc <+16>: str w1, [sp, #0x8]
0x100086b00 <+20>: ldur w0, [x29, #-0x4]
0x100086b04 <+24>: ldr w1, [sp, #0x8]
0x100086b08 <+28>: bl 0x100086b18 ; funcC at Ctest.c:75
0x100086b0c <+32>: ldp x29, x30, [sp, #0x10]
0x100086b10 <+36>: add sp, sp, #0x20 ; =0x20
0x100086b14 <+40>: ret
funcC
Assembly`funcC:
0x100086b18 <+0>: sub sp, sp, #0x10 ; =0x10
0x100086b1c <+4>: str w0, [sp, #0xc]
0x100086b20 <+8>: str w1, [sp, #0x8]
0x100086b24 <+12>: ldr w0, [sp, #0xc]
0x100086b28 <+16>: ldr w1, [sp, #0x8]
0x100086b2c <+20>: add w0, w0, w1
0x100086b30 <+24>: str w0, [sp, #0x4]
0x100086b34 <+28>: ldr w0, [sp, #0x4]
0x100086b38 <+32>: add sp, sp, #0x10 ; =0x10
0x100086b3c <+36>: ret
汇编分析
先回忆一下几个关键寄存器和指令,
sp (Stack Point) :寄存器r31,指向函数调用栈的栈顶
fp (Frame Point):寄存器r29,指向当前正在执行函数栈帧的栈底
lr (Link Register) :寄存器r30,存储的是函数返回地址,用于当函数结束时,返回函数调用方继续往下执行。
bl:跳转指令,它做了两件事情,
1. 把下一条指令的地址存储到lr寄存器中
2. 跳转到标记处执行指令
ret:函数返回,返回到lr保存的地址继续执行指令。
更多的寄存器和指令学习可参考iOS逆向-arm64汇编学习。
由于funcA与funcB都是非叶子函数,生成的主要汇编代码大致相同,所以下面只分析funcB和funcC对应的汇编代码。
Assembly funcB:
Assembly`funcB:
// 第一部分:开辟栈空间,保护现场
0x100086aec <+0>: sub sp, sp, #0x20 ;// sp指针往下移动0x20个字节,开辟栈空间。
0x100086af0 <+4>: stp x29, x30, [sp, #0x10] ;// x29(fp)、x30(lr)寄存器中的内容存放内存中
0x100086af4 <+8>: add x29, sp, #0x10 ;// x29(fp) 栈底指针往下移动0x10个字节。
// 第二部分:函数逻辑
0x100086af8 <+12>: stur w0, [x29, #-0x4] ;// 把第一个参数存入内存中
0x100086afc <+16>: str w1, [sp, #0x8] ;// 把第二个参数存入内存中
0x100086b00 <+20>: ldur w0, [x29, #-0x4] ;// 从内存中读取到w0中,也就是第一个参数
0x100086b04 <+24>: ldr w1, [sp, #0x8] ;// 从内存中读取到w1中,也就是第二个参数
0x100086b08 <+28>: bl 0x100086b18 ;// 调用 funC 函数
// 第三部分:恢复现场,回收栈空间
0x100086b0c <+32>: ldp x29, x30, [sp, #0x10] ;// 从内存中读取数据到x29、x30,恢复 x29、x30的值。
0x100086b10 <+36>: add sp, sp, #0x20 ;// 函数执行完毕,回收栈空间
0x100086b14 <+40>: ret ;// 返回,跳转回上一个函数(funcA)执行
Assembly funcC
Assembly`funcC:
// 第一部分:开辟栈空间
0x100086b18 <+0>: sub sp, sp, #0x10 ;// sp指针往下移动0x20个字节,开辟栈空间。
// 第二部分:函数逻辑
0x100086b1c <+4>: str w0, [sp, #0xc]
0x100086b20 <+8>: str w1, [sp, #0x8]
0x100086b24 <+12>: ldr w0, [sp, #0xc]
0x100086b28 <+16>: ldr w1, [sp, #0x8]
0x100086b2c <+20>: add w0, w0, w1
0x100086b30 <+24>: str w0, [sp, #0x4]
0x100086b34 <+28>: ldr w0, [sp, #0x4]
// 第三部分:回收栈空间
0x100086b38 <+32>: add sp, sp, #0x10 ;// 函数执行完毕,回收栈空间
0x100086b3c <+36>: ret ;// 返回,跳转回上一个函数(funcB)执行
经过上面的分析,Assembly funcB:与Assembly funcC:最大的却别是在Assembly funcB:中有对x29 (fp)、x30 (lr)的内容存储到内存,进行保护,并在结束时恢复其原来的值;而在Assembly funcC:中没有这样的操作。
原因分析:
- 在Assembly funcC:有
bl指令,bl指令会修改x30( lr )寄存器的值,所以需要在真正执行函数之前保存。 - 那为什么要保存
x29的值呢?从汇编代码看,x29是被修改了,但是不修改也可以的,其他指令并没有修改x29的值;单独通过sp也可以完成所有的寻址(访问具体的内存空间)工作。说说我个人的理解
2.1)通过x29 (fp)和x30(sp)可以确定当前函数的栈帧的地址范围,寻址时不可以超出这个范围。访问超出这个范围地址的数据可能是脏数据,至少对当前函数来说是脏数据。
2.2)有了x29寄存器,寻址的时候可以用x29的值做一个偏移定位到要访问的地址,也可以用sp的值做一个偏移找到要访问的地址。靠近栈底的用x29做偏移,靠近栈顶的用sp做偏移,这样可以提高寻址的速度。那CPU怎么知道要访问的地址是靠近x29还是靠近sp呢?CPU是不知道的,但编译器知道,要访问什么地址,在程序编译的时候就确定了。
2.3)那Assembly funcC:为什么没有栈底指针x29,有的话也可以提高寻址速度啊。那为什么没有自己的栈底指针呢?目前还没找到答案,也是自己的一个疑惑。
好了,上面啰嗦了那么多,下面通过图来看函数调用时栈空间和寄存器的变化情况,
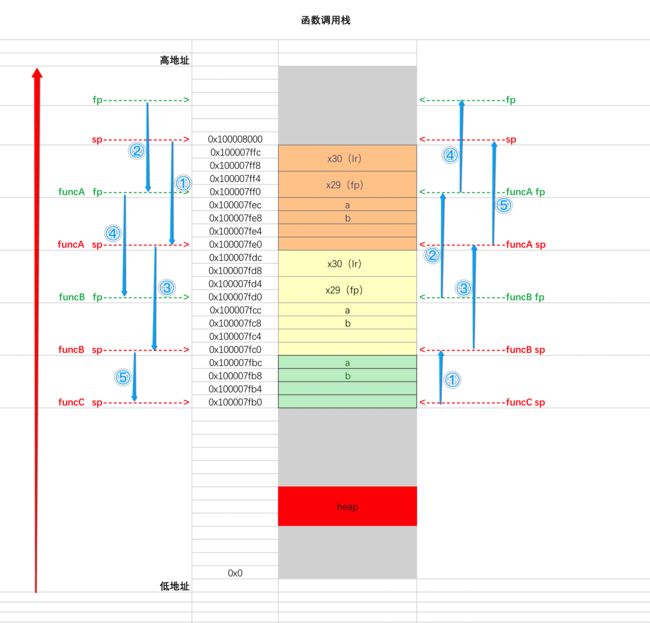
对图稍微说明一下,栈是高地址往低地址增长的,图中每一行表示4个字节。左边是函数调用时
sp和
fp的变化过程,右边是函数调用结束后
sp和
fp的变化过程。通过观察,开辟栈空间时,不是需要多大的内存就开闭多少的内存空间,而是16的倍数的字节数。这要做有助于提高
CPU访问内存的速度。
总结
通过上面的分析,理解了函数调用时栈空间和寄存器的变化情况,以及为什么需要那样变化。但还留下了一个疑问,叶子函数为什么没有自己fp,知道的大神麻烦告知。