目标:抓取客路旅行热门活动基本信息
范围:适用有Python及爬虫基础的人群
声明:技术交流,非法用途,后果自负
分析网站:https://www.klook.com/zh-CN/
图1
提取网址:https://www.klook.com + /zh-CN/activity/1659-taipei-101-taipei/?krt=r20&krid=7da3cd84-98c0-40aa-41d0-1e195ab614e4 (如图)
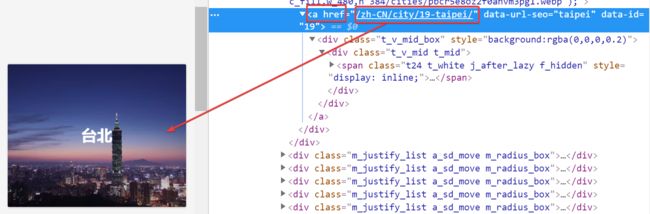
图2
热门活动: https://www.klook.com + /zh-CN/activity/1659-taipei-101-taipei/?krt=r20&krid=7da3cd84-98c0-40aa-41d0-1e195ab614e4(如图)
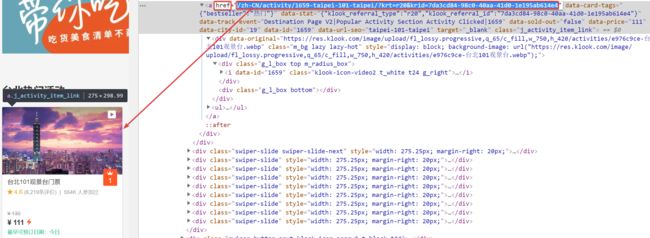
图3
提取:活动主题、活动原价、活动现价

图4
图5
分析JS动态页面:
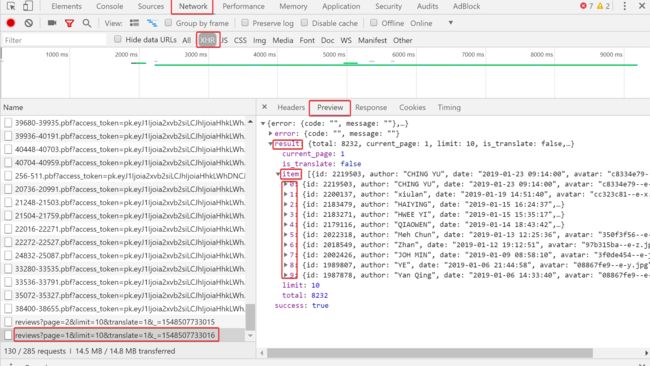
图6
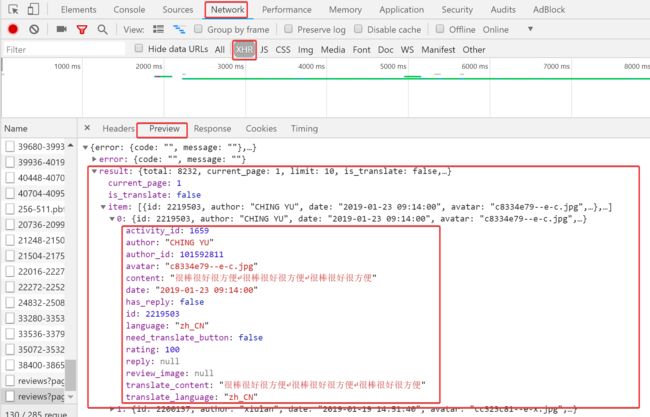
图7
提取:参与用户、活动评分、活动评价、活动时间(无法直接从html语言中提取,通过如图方式分析URL提取JSON)
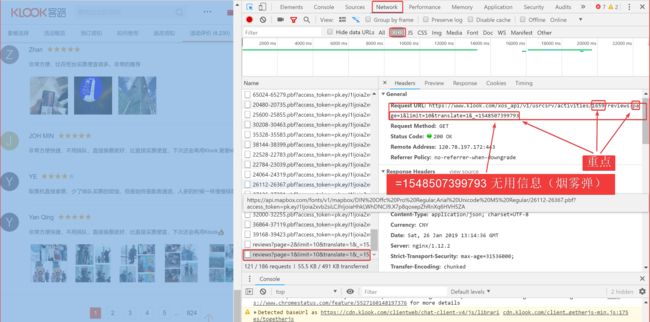
图8
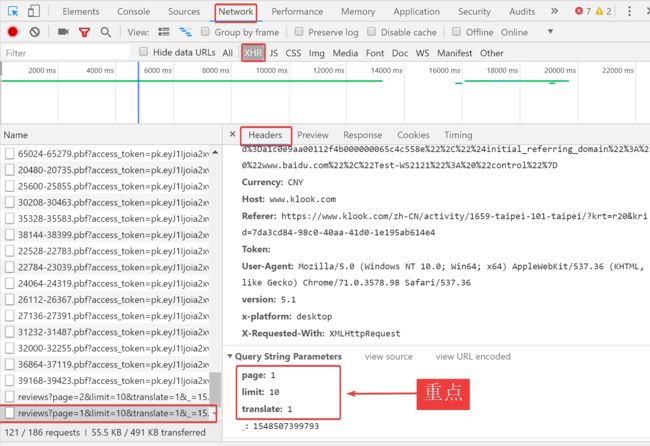
图9
#! -*-coding:utf-8 -*-
from lxml import etree
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import requests
import re
import json
import pymysql
import time
url = r'https://www.klook.com'
headers={
'Accept-Language': 'zh_CN',
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
proxies={"http":"http:183.129.244.16:11723"}
def get_hot_page(url):
page = requests.get(url, headers=headers).text
html = etree.HTML(page)
page_html = html.xpath("//section//div[@class=' m_bg hot_lazy']/a/@href")
hot_html = {}
for i ,page_html in enumerate(page_html):
if i == 0:
hot_html = [url+page_html]
else:
hot_html.append(url+page_html)
return hot_html
def get_hot_activity(hot_page):
for i,page in enumerate(hot_page):
page = requests.get(page,headers=headers).text
html = etree.HTML(page)
hot_activity = html.xpath("//div//div[@class='m_justify_list m_radius_box act_card act_card_sm a_sd_move j_activity_item js-item ']/a/@href")
for j,info in enumerate(hot_activity):
# print(info)
if i==0 and j == 0 :
activity_html = [url+info]
else :
activity_html.append(url+info)
return activity_html
def get_base_infos(activity_html):
db = pymysql.connect(host = 'localhost', user = 'root',password ='密码',port = 3306 )
cursor = db.cursor()
cursor.execute('use luke ;')
cursor.execute('drop table if exists infos ')
cursor.execute('create table infos(title VARCHAR(100),num INT ,before_price INT,after_price INT,author VARCHAR(100),rating INT,time VARCHAR (100),evaluate VARCHAR (5000))')
cursor.execute('alter table infos convert to character set utf8mb4 collate utf8mb4_bin') #设置mysql能存储表情
for i,html in enumerate(activity_html):
print(html)
e_html = requests.get(html,headers = headers ).text
e_html = etree.HTML(e_html)
try:
e_html.xpath("//div//div[@class='pagination j_pagination']/a[@class='p_num']")[0].text
except:
try:
int(e_html.xpath("//div//div[@class='pagination j_pagination']/a[@class='p_num ']")[-1].text.replace(',', ''))
except:
num = 1;
else:
num = int(e_html.xpath("//div//div[@class='pagination j_pagination']/a[@class='p_num ']")[-1].text.replace(',',''))
else:
num = int(e_html.xpath("//div//div[@class='pagination j_pagination']/a[@class='p_num']")[0].text.replace(',',''))
after_price = int(e_html.xpath("//div//p[@class='price']/strong/span")[0].text.replace(',',''))
try:
e_html.xpath("//div//p[@class='price']/del")[0].text
except:
before_price = after_price
else:
before_price = int(e_html.xpath("//div//p[@class='price']/del")[0].text.replace(',','')) #热门活动html内标签内容不完全相同,当代码报错时,自动调整提取的标签内容。
title_page = e_html.xpath("//div//h1[@class='t32']")[0].text
pattern = re.compile(r'.*/(\d{4,5})-.*', re.I) #提取活动码(图8的1659)
num_page = pattern.match(html).group(1)
print(num_page)
for j in range(1,num):
data = {
'page': j,
'limit':'10',
'translate': '1',
'_': '1548144348424' #该行无用信息(烟雾弹)
}
html = "https://www.klook.com/xos_api/v1/usrcsrv/activities/%s/reviews?page=%d&limit=10&translate=1&_=1548143908771"%(num_page,j)
print(html)
page = requests.get(html, headers=headers, params=data, proxies=proxies).text
for k in range(0,10):
try : #试用try是防止热门活动无任何信息报错
json.loads(page)['result']['item'][k].get('author') #提取Json中的基本信息,详见图6与图7
except :
break
else:
author_page = str(json.loads(page)['result']['item'][k]['author']).replace('\'','') #存储到mysql中'符号会报错,删除'符号解决该问题
rating_page = int(json.loads(page)['result']['item'][k]['rating'])
evaluate_page = str(json.loads(page)['result']['item'][k]['translate_content']).replace('\'','')
time_page = json.loads(page)['result']['item'][k]['date']
data =[]
data.extend([title_page,num_page,before_price,after_price,author_page,rating_page,time_page,evaluate_page])
data = tuple(data)
print(data)
cursor = db.cursor()
sql = "insert into infos values('%s','%s',%d,%d,'%s',%d,'%s','%s')"
cursor.execute(sql %data)
db.commit()
time.sleep(0.1)
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
hot_page = get_hot_page(url)
activity_html = get_hot_activity(hot_page)
base_infos = get_base_infos(activity_html)