代码编辑工具:jupyter notebook
01 理论讲解

KNN算法
1. KNN算法特点:

KNN算法
2. 算法原理

KNN算法
为了简化问题,这里只关心样本的两个特征,肿瘤大小和发现肿瘤的时间。对应红色(样本数据)点表示良性肿瘤,蓝色(样本数据)表示恶性肿瘤,绿色(预测数据)的点表示我们要预测的数据,k=3表示在所有的点里,找到离这个绿色最近的三个点,然后判断是红色点多还是蓝色点多,绿色点和多的一边同类。
例如:这里的绿色点,它周围的3个点都是蓝色点,所以这个绿色点应该属于恶性肿瘤。
3. 欧拉距离
计算距离我们这里采用欧拉距离,就是两个点对应维度上的坐标值相减、平方、求和、开根号的过程
欧拉距离-2维,平面两个点的距离:
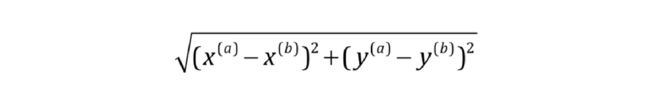
欧拉距离-2维
欧拉距离-3维,三维立体空间两个点的距离:

欧拉距离-3维
欧拉距离-n维,推导到n空间依然有效

欧拉距离-n维
欧拉距离-n维符-简洁版:
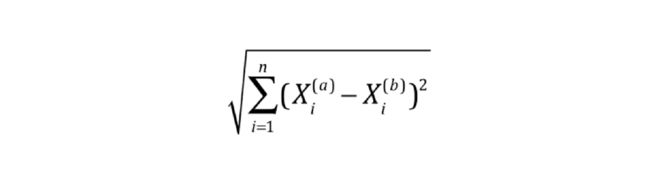
欧拉距离-n维符-简洁版
02 代码实战
import numpy as np #导入numpy,用于科学计算,如,矩阵运算
import matplotlib.pyplot as plt #导入图像显示库pyplot,如折线图
import random #导入随机函数库,生成随机数
##### 10个样本数据
data_X = [
[-0.32236679, -1.38462662],#标签值:0
[-0.60582652, -1.93436036],#标签值:0
[-2.37209117, -0.34753905],#标签值:0
[-0.13360596, 0.96327911],#标签值:0
[-1.43553756, -0.84890974],#标签值:0
[ 3.70753694, 0.98062288],#标签值:1
[ 2.029152 , -0.1819102 ],#标签值:1
[ 5.45626862, -1.20479895],#标签值:1
[ 4.07688348, -0.29181106],#标签值:1
[ 4.22392082, -2.92426277] #标签值:1
]
data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] #标签数据,0代表良性肿瘤,1代表恶性肿瘤,是个二分类问题
data_y_name = ['良性肿瘤','恶性肿瘤']#分类名称,0:良性肿瘤,1:恶性肿瘤
X_train = np.array(data_X) #转为numpy ndarray格式
y_train = np.array(data_y) #转为numpy ndarray格式
x1 = X_train[y_train == 0,0] #在下标为0的列上,标签值为0的所有值,作为x1
y1 = X_train[y_train == 0,1] #在下标为0的列上,标签值为0的所有值,作为y1
plt.scatter(x1,y1,label="良性肿瘤") #把样本数据x1,y1显示在图像上
x2 = X_train[y_train == 1,0] #在下标为0的列上,标签值为1的所有值,作为x2
y2 = X_train[y_train == 1,1] #在下标为1的列上,标签值为1的所有值,作为y2
plt.scatter(x2,y2,label="恶性肿瘤") #把样本数据x2,y2显示在图像上
x = np.array([2.093607318, -0.565731514]) #把需要预测的x显示在图像上
plt.scatter(x[0],x[1],label="预测点")
plt.show() #显示图像,效果如下

image.png
#通过欧拉距离计算预测点到每一个样本点之前的距离
distances = []
for x_train in data_X:
d = np.sqrt(np.sum((x_train - x) ** 2))
distances.append(d)
distances
[2.5509841405146267,
3.02656372208528,
4.471025714203831,
2.7015463116527125,
3.540487745720093,
2.235169062199137,
0.38919569511900787,
3.422849429893747,
2.0021030817310623,
3.178192143708816]
#对计算出来的结果进行排序,返回排序后的下标顺序
sort_distances = np.argsort(distances)
sort_distances
array([6, 8, 5, 0, 3, 1, 9, 7, 4, 2], dtype=int64)
k = 4 #设置KNN的k值为3
X_top = X_train[sort_distances[0:k]] #计算举例最近的三个点
X_top
array([[ 2.029152 , -0.1819102 ],
[ 4.07688348, -0.29181106],
[ 3.70753694, 0.98062288],
[-0.32236679, -1.38462662]])
#离的最近的k个点和预测点之前画虚线
for top in X_top:
line_x = [top[0],x[0]]
linx_y = [top[1],x[1]]
plt.plot(line_x,linx_y,':')
#画样本点
plt.scatter(x1,y1) #良性肿瘤
plt.scatter(x2,y2) #恶性肿瘤
#画预测点
plt.scatter(x[0],x[1])
#图像显示
plt.show()
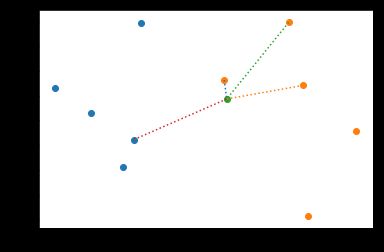
image.png
#通过距离最近的k个值,获取指定样本的标签
y_top_k = y_train[sort_distances[0:k]]
y_top_k
array([1, 1, 1, 0])
from collections import Counter
#统计不同分类标签的个数
votes = Counter(y_top6)
votes
Counter({1: 3, 0: 1})
#获取最多分类的那个标签值
lvalue = votes.most_common(1)[0][0]
lvalue
1
#通过标签值显示对于的分类名称
data_y_name[lvalue]
'恶性肿瘤'