看到有读者质疑,说明一下:
本文首发于CDA数据分析师,后转载至CSDN。此处放的是投稿前的初稿。
文章从提笔到整理发布时间有点长了,网上现在也能见到类似的文章,但本文所有代码思路都是原创。
《我不是药神》是由文牧野执导,宁浩、徐峥共同监制的剧情片,徐峥、周一围、王传君、谭卓、章宇、杨新鸣等主演 。影片讲述了神油店老板程勇从一个交不起房租的男性保健品商贩程勇,一跃成为印度仿制药“格列宁”独家代理商的故事。该片于2018年7月5日在中国上映。上映之后获得一片好评,不少观众甚至直呼“中国电影希望”,“《熔炉》、《辩护人》之类写实影片同水准”,诚然相较于市面上一众的抠图贴脸影视作品,《药神》在影片质量上确实好的多,不过我个人觉得《药神》的火爆还有以下几个原因:
- 影片题材稀少带来的新鲜感,像这类"针砭时弊" 类影视作品,国内太少
- 顺应潮流,目前《手机》事件及其带来的影响和国家层面文化自信的号召以及影视作品水平亟待提高的大环境下,《药神》的过审与上映本身也是对该类题材一定程度的鼓励
- 演员靠谱、演技扎实,这个没的说,特别是王传君的表现,让人眼前一亮
本文通过爬取《我不是药神》和《邪不压正》豆瓣电影评论,对影片进行可视化分析(ps:千古代码一大抄,网上的各种参考代码,各种不靠谱,最后还是自己一个个坑去解决)
截止7月13日:《我不是药神》豆瓣评分:8.9 分,猫眼:9.7 分,时光网:8.8 分 。
截止7月13日: 《邪不压正》 豆瓣评分:7.2 分,猫眼:7.4 分,时光网:7.3 分 。
豆瓣的评分质量相对而言要靠谱点,所以本文数据来源也是豆瓣。
【声明】
未经授权杜绝转载!
0需求分析
- 获取影评数据
- 清洗分析存储数据
- 分析展示影评城市来源、情感
- 分时展示电影评分趋势
- 当然主要是用来熟练pandas和爬虫及可视化技能
1前期准备
1.1网页分析
豆瓣从2017.10月开始全面禁止爬取数据,仅仅开放500条数据,白天1分钟最多可以爬取40次,晚上一分钟可爬取60次数,超过此次数则会封禁IP地址
tips发现
实际操作发现,点击影片评论页面的后页时,url中的一个参数start会加20,但是如果直接赋予'start'每次增加10,网页也是可以存在的!
- 登录状态下,按网页按钮点击
后页,start最多为480,也就是20*25=500条 - 非登录状态下,最多为200条
- 登录状态下,直接修改url的方法可以比官方放出的评论数量多出了一倍!!!
1.2页面布局分析
本次使用xpath解析,因为之前的博客案例用过正则,也用过beautifulsoup,这次尝试不一样的方法
如下图所示,本此数据爬取主要获取的内容有
- 评论用户ID
- 评论内容
- 评分
- 评论日期
-
用户所在城市
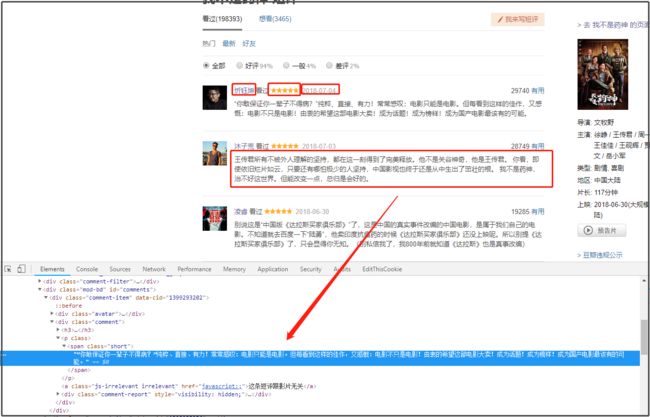 页面布局.png
页面布局.png
城市信息获取
评论页面没有城市信息,因此需要通过进入评论用户主页去获取城市信息元素

通过分析页面发下,用户ID名称里隐藏着主页链接!
所以我的思路就是request该链接,然后提取城市信息
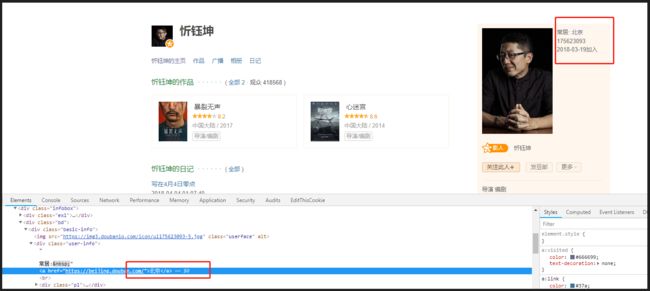
2数据获取-爬虫
2.1获取cookies
因为豆瓣的爬虫限制,所以需要使用cookies作身份验证,通过chrome获取cooikes位置如下图
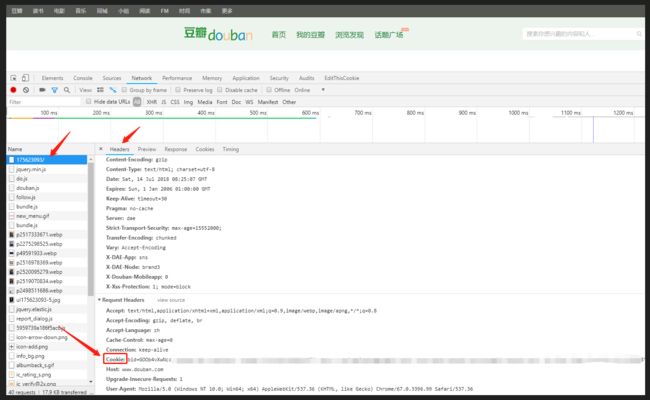
2.2加载cookies与headers
下面的cookie被修改了,诸君需要登录后自己获取专属cookieo(∩_∩)o
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
cookies = {'cookie': 'bid=GOOb4vXwNcc; douban-fav-remind=1; viewed="27611266_26886337"; ps=y; ue="citpys原创分享@163.com"; " \
"push_noty_num=0; push_doumail_num=0; ap=1; loc-last-index-location-id="108288"; ll="108288"; dbcl2="187285881:N/y1wyPpmA8"; ck=4wlL'}
url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit=20&sort=new_score&status=P"
res = requests.get(url, headers=headers, cookies=cookies)
res.encoding = "utf-8"
if (res.status_code == 200):
print("\n第{}页短评爬取成功!".format(page + 1))
print(url)
else:
print("\n第{}页爬取失败!".format(page + 1))
一般刷新页面后,第一个请求里包含了cookies
2.3延时反爬虫
设置延时发出请求,并且延时的值还保留了2位小数(自我感觉模拟正常访问请求会更加逼真...待证实)
time.sleep(round(random.uniform(1, 2), 2))
2.4解析需求数据
这里有个大bug,找了好久!
因为有的用户虽然给了评论,但是没有给评分,所以score和date这两个的xpath位置是会变动的。。。
所以需要加判断,如果发现score里面解析的是日期,证明该条评论没有给出评分
name = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i))
# 下面是个大bug,如果有的人没有评分,但是评论了,那么score解析出来是日期,而日期所在位置spen[3]为空
score = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title'.format(i))
date = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[3]/@title'.format(i))
m = '\d{4}-\d{2}-\d{2}'
match = re.compile(m).match(score[0])
if match is not None:
date = score
score = ["null"]
else:
pass
content = x.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(i))
id = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/@href'.format(i))
try:
city = get_city(id[0], i) # 调用评论用户的ID城市信息获取
except IndexError:
city = " "
name_list.append(str(name[0]))
score_list.append(str(score[0]).strip('[]\'')) # bug 有些人评论了文字,但是没有给出评分
date_list.append(str(date[0]).strip('[\'').split(' ')[0])
content_list.append(str(content[0]).strip())
city_list.append(city)
2.5获取电影名称
从url上只能获取电影的subject的8位ID数值,引起需要自行解析网页获取ID号对应的电影名称,该功能是后期改进添加的,因此为避免现有代码改动多(偷个懒),采用了全局变量赋值给movie_name,需要注意全局变量调用时,要加global声明一下。
pattern = re.compile('.*?.*?(.*?) 短评
', re.S)
global movie_name
movie_name = re.findall(pattern, res.text)[0] # list类型
3数据存储
因为数据量不是很大,因为普通csv存储足够,把获取的数据转换为pandas的DF格式,然后存储到csv文件中
infos = {'name': name_list, 'city': city_list, 'content': content_list, 'score': score_list, 'date': date_list}
data = pd.DataFrame(infos, columns=['name', 'city', 'content', 'score', 'date'])
data.to_csv(str(ID) + "_comments.csv")
因为考虑到代码的复用性,所以main函数中传入了两个参数,
- 一个是待分析影片在豆瓣电影中的ID号(这个可以在链接中获取到,是一个8位数
-
一个是需要爬取的页码数,一般设置为49,因为网站只开放500条评论
另外有些电影评论有可能不足500条,所以需要调整,之前尝试通过正则匹配分析页面结构
 末尾页.png
末尾页.png
来判断是否是评论的末尾页,如果到达评论末页,则停止爬取数据,但是没成功...有兴趣的读者可以尝试
4数据清洗
爬取出来的结果如下
 爬取结果.png
爬取结果.png
分别为:评论序列号,用户名,用户所在城市,评论内容, 评分, 评论日期
但是通过人工观察分析注意到,爬取结果中有很多不规则的数据,例如,有的用户写影评了,但是没有给出评分,那么后续pandas处理的时候就需要
dropna()一下
4.1城市信息清洗
从爬取的结果分析可以发现,城市信息数据有以下问题
- 有城市空缺
- 海外城市
- 乱写
- pyecharts尚不支持的城市,目前支持的城市列表点这里链接
step1: 过滤筛选中文字
通过正则表达式筛选中文,通过split函数提取清理中文,通过sub函数替换掉各类标点符号
line = str.strip()
p2 = re.compile('[^\u4e00-\u9fa5]') # 中文的编码范围是:\u4e00到\u9fa5
zh = " ".join(p2.split(line)).strip()
zh = ",".join(zh.split())
str = re.sub("[A-Za-z0-9!!,%\[\],。]", "", zh)
step2: 匹配pyecharts支持的城市列表
一开始我不知道该库有城市列表资料(只找了官网,没看github)所以使用的方法如下,自己上网找中国城市字典,然后用excel 筛选和列表分割功能快速获得一个不包含省份和'市'的城市字典,然后匹配。后来去github上issue了下,发现有现成的字典文件,一个json文本,得到的回复如下(__)
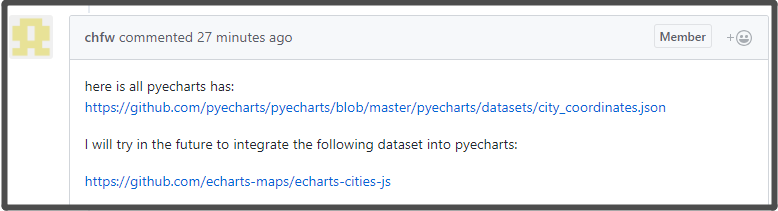 城市列表.png
城市列表.png
这样就方便了,直接和这个列表匹配就完了,不在里面的话,直接list.pop就可以了 但是这样还有个问题,就是爬取下来的城市信息中还包含着省份,而pyecharts中是不能带省份的,所以还需要通过分割,来提取城市,可能存在的情况有
- 两个字:北京
- 三个字:攀枝花
- 四个字:山东烟台
- 五个字:四川攀枝花
- 六个字:黑龙江哈尔滨
- 。。。
因此我做了简化处理:
- 名称为2~4的,如果没匹配到,则提取后2个字,作为城市名
- 名称为>4的,如果没匹配到,则依次尝试提取后面5、4、3个字的
- 其余情况,经过观察原始数据发现数量极其稀少,可以忽略不作处理
d = pd.read_csv(csv_file, engine='python', encoding='utf-8')
for i in d['city'].dropna(): # 过滤掉空的城市
i = translate(i) # 只保留中文
if len(i)>1 and len(i)<5: # 如果名称个数2~4,先判断是否在字典里
if i in fth:
citys.append(i)
else:
i = i[-2:] # 取城市名称后两个,去掉省份
if i in fth:
citys.append(i)
else:
continue
if len(i) > 4:
if i in fth: # 如果名称个数>2,先判断是否在字典里
citys.append(i)
if i[-5:] in fth:
citys.append(i[-5:])
continue
if i[-4:] in fth:
citys.append(i[-4:])
continue
if i[-3:] in fth:
citys.append(i[-3:])
else:
continue
result = {}
while '' in citys:
citys.remove('') # 去掉字符串中的空值
print("城市总数量为:",len(citys))
for i in set(citys):
result[i] = citys.count(i)
return result
但是这样可能还有漏洞,所以为保证程序一定不出错,又设计了如下校验模块:
思路就是,循环尝试,根据xx.add()函数的报错,确定城市名不匹配,然后从list中把错误城市pop掉,另外注意到豆瓣个人主页上的城市信息一般都是是到市,那么县一级的区域就不考虑了,这也算是一种简化处理
while True: # 二次筛选,和pyecharts支持的城市库进行匹配,如果报错则删除该城市对应的统计
try:
attr, val = geo.cast(info)
geo.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False,
is_piecewise=True, visual_split_number=6, symbol_size=15, is_visualmap=True)
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1] # 获取不支持的城市名称
info.pop(e)
else:
break
5基于snownlp的情感分析
snownlp主要可以进行中文分词(算法是Character-Based Generative Model)、词性标注(原理是TnT、3-gram 隐马)、情感分析(官网木有介绍原理,但是指明购物类的评论的准确率较高,其实是因为它的语料库主要是购物方面的,可以自己构建相关领域语料库,替换原来的,准确率也挺不错的)、文本分类(原理是朴素贝叶斯)、转换拼音、繁体转简体、提取文本关键词(原理是TextRank)、提取摘要(原理是TextRank)、分割句子、文本相似(原理是BM25)。
官网还有更多关于该库的介绍,在看本节之前,建议先看一下官网,里面有最基础的一些命令的介绍。官网链接
由于snownlp全部是unicode编码,所以要注意数据是否为unicode编码。因为是unicode编码,所以不需要去除中文文本里面含有的英文,因为都会被转码成统一的编码上面只是调用snownlp原生语料库对文本进行分析,snownlp重点针对购物评价领域,所以为了提高情感分析的准确度可以采取训练语料库的方法。
attr, val = [], []
info = count_sentiment(csv_file)
info = sorted(info.items(), key=lambda x: x[0], reverse=False) # dict的排序方法
for each in info[:-1]:
attr.append(each[0])
val.append(each[1])
line = Line(csv_file+":影评情感分析")
line.add("", attr, val, is_smooth=True, is_more_utils=True)
line.render(csv_file+"_情感分析曲线图.html")
6数据可视化与解读
6.0文本读取
在后面的commit版本中,我最终只传入了电影的中文名字作为参数,因此相较于之前的版本,在路径这一块儿需要做写调整。由于python不支持相对路径下存在中文,因此需要做如下处理:
- step1 获取文件绝对路径
- step2 转换路径中的
\为\\
- step3 如果还报错,在
read_csv中加参数read_csv(csv_file, engine='python', encoding='utf-8')
- 注意: python路径中,如果最后一个字符为
\会报错,因此可以采取多段拼接的方法解决
完整代码如下
path = os.path.abspath(os.curdir)
csv_file = path+ "\\" + csv_file +".csv"
csv_file = csv_file.replace('\\', '\\\\')
6.1评论来源城市分析
调用pyecharts的page函数,可以在一个图像对象中创建多个chart,只需要对应的add即可。
城市评论分析的思路如下:
经过步骤4的的清洗处理之后,获得形如[("青岛", 9),("武汉", 12)]结构的数据
-
通过循环试错,把不符合条件的城市信息pop掉
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1] # 获取不支持的城市名称
info.pop(e)
- 遍历dict,抽取信息赋值给
attr和val为画图做准备
for key in info:
attr.append(key)
val.append(info[key])
函数代码如下
geo1 = Geo("", "评论城市分布", title_pos="center", width=1200, height=600,
background_color='#404a59', title_color="#fff")
geo1.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False,
is_piecewise=True, visual_split_number=10, symbol_size=15, is_visualmap=True, is_more_utils=True)
#geo1.render(csv_file + "_城市dotmap.html")
page.add_chart(geo1)
geo2 = Geo("", "评论来源热力图",title_pos="center", width=1200,height=600, background_color='#404a59', title_color="#fff",)
geo2.add("", attr, val, type="heatmap", is_visualmap=True, visual_range=[0, 50],visual_text_color='#fff', is_more_utils=True)
#geo2.render(csv_file+"_城市heatmap.html") # 取CSV文件名的前8位数
page.add_chart(geo2)
bar = Bar("", "评论来源排行", title_pos="center", width=1200, height=600 )
bar.add("", attr, val, is_visualmap=True, visual_range=[0, 100], visual_text_color='#fff',mark_point=["average"],mark_line=["average"],
is_more_utils=True, is_label_show=True, is_datazoom_show=True, xaxis_rotate=45)
#bar.render(csv_file+"_城市评论bar.html") # 取CSV文件名的前8位数
page.add_chart(bar)
pie = Pie("", "评论来源饼图", title_pos="right", width=1200, height=600)
pie.add("", attr, val, radius=[20, 50], label_text_color=None, is_label_show=True, legend_orient='vertical', is_more_utils=True, legend_pos='left')
#pie.render(csv_file + "_城市评论Pie.html") # 取CSV文件名的前8位数
page.add_chart(pie)
page.render(csv_file + "_城市评论分析汇总.html")
 1.png
1.png
评论分布点图
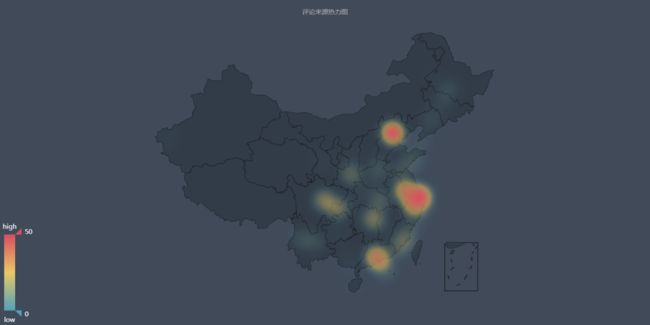 2.png
2.png
评论分布热力图
 3.png
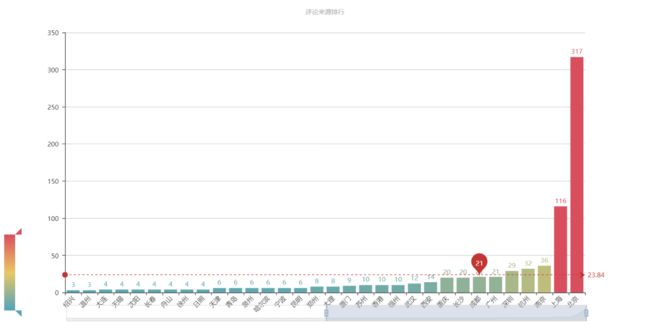
3.png
评论柱状图图
 4.png
4.png
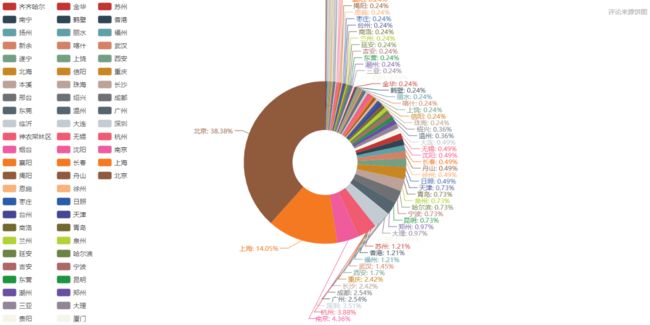
评论分布饼图
从上图可以看出,《我不是药神》的观影人群中,排名前十的城市依次为 北京、上海、南京、杭州、深圳、广州、成都、长沙、重庆、西安
而相对的《邪不压正》观影人群,排名前十依次为 北京、上海、广州、成都、杭州、南京、西安、深圳、长沙、哈尔滨
电影消费是城市消费的一部分,某种程度上可以作为观察一个城市活力的指标。上述城市大都在近年的GDP排行中居上游,消费力强劲。但是我们不能忽略城市人口基数和荧幕数量的因素。一线大城市的荧幕数量总额是超过其他二三线城市的,大城市人口基数庞大,极多的荧幕数量和座位、极高密度的排片场次,让诸多人便捷观影,这样一来票房自然就比其他城市高出不少,活跃的观众评论也多。
6.2评论情感分析
0.5以下为负面情绪,0.5以上为正面情绪,因为电影好评太多,为了图形的合理性(让低数值的统计量也能在图中较明显的展示),把评论接近1的去掉了。当然按理说情绪正面性到1的应该很少,出现这种结果的原因我觉得是预料库的锅。
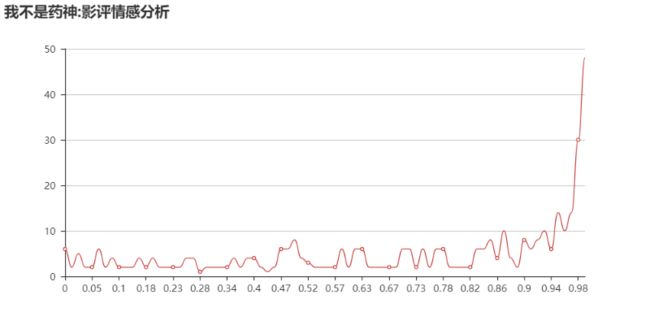 sentiment.png
sentiment.png
评论情感分析图
从情感分析曲线上来看,影片评论整体偏向是正面积极的,这和各大网站的影片评分也相一致,卖好又卖座!
6.3电影评分走势分析
思路如下:
- 读取csv文件,以dataframe(df)形式保存
- 遍历df行,保存到list
- 统计相同日期相同评分的个数,刑如
dict类型 ('很差', '2018-04-28'): 55
- 转换为df格式,设置列名
info_new.columns = ['score', 'date', 'votes']
- 按日期排序,
info_new.sort_values('date', inplace=True)
- 遍历新的df,每个日期的评分分为5种,因此需要插入补充缺失数值
补充缺失数值
创建新df,遍历匹配各种评分类型,然后插入行
creat_df = pd.DataFrame(columns = ['score', 'date', 'votes']) # 创建空的dataframe
for i in list(info_new['date']):
location = info_new[(info_new.date==i)&(info_new.score=="力荐")].index.tolist()
if location == []:
creat_df.loc[mark] = ["力荐", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="推荐")].index.tolist()
if location == []:
creat_df.loc[mark] = ["推荐", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="还行")].index.tolist()
if location == []:
creat_df.loc[mark] = ["还行", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="较差")].index.tolist()
if location == []:
creat_df.loc[mark] = ["较差", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="很差")].index.tolist()
if location == []:
creat_df.loc[mark] = ["很差", i, 0]
mark += 1
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
细节
由于遍历匹配时,抽取的评分等级和上文代码中的“力荐”、“推荐”、“还行”、“较差”、“很差”次序可能不一致,因此最后会有重复值出现,所以在拼接两个df时,需要duplicates()去重
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
之后就可以遍历df取数画图了(第二中遍历df的方法)
for index, row in info_new.iterrows(): # 第二种遍历df的方法
score_list.append([row['date'], row['votes'], row['score']])
前面还提到了一种遍历方法
for indexs in d.index: # 一种遍历df行的方法
d.loc[indexs].values[:])
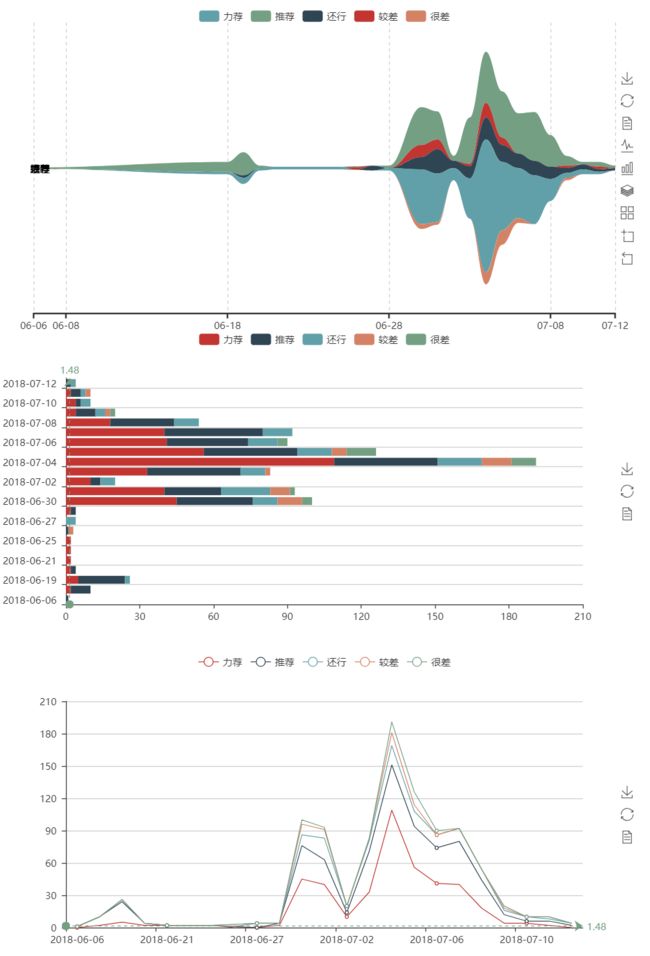 评分走势.png
评分走势.png
评分走势分析图
从上述日评分投票走势图可以发现,在影片上映开始的一周内,为评论高峰,尤其是上映3天内,这符合常识,但是也可能有偏差,因为爬虫获取的数据是经过豆瓣电影排序的,倘若数据量足够大得出的趋势可能更接近真实情况。另外发现,影片在上映前也有部分评论,分析可能是影院公映前的小规模试映,且这些提前批的用户的评分均值,差不多接近影评上映后的大规模评论的最终评分 ,从这些细节中,我们或许可以猜测,这些能提前观看影片的,可能是资深影迷或者影视从业人员,他们的评论有着十分不错的参考价值。那么日后在观看一部尚未搬上大荧幕的影片前,我们是否可以通过分析这些提前批用户的评价来决定是否掏腰包去影院避免邂逅烂片呢?
6.4影评词云图
思路如下:
- 读取csv文件,以dataframe(df)形式保存
- 去除评论中非中文文本
- 选定词云背景
- 调整优化停用词表
pic_name = csv_file+"_词云图.png"
path = os.path.abspath(os.curdir)
csv_file = path+ "\\" + csv_file + ".csv"
csv_file = csv_file.replace('\\', '\\\\')
d = pd.read_csv(csv_file, engine='python', encoding='utf-8')
content = []
for i in d['content']:
try:
i = translate(i)
except AttributeError as e:
continue
else:
content.append(i)
comment_after_split = jieba.cut(str(content), cut_all=False)
wl_space_split = " ".join(comment_after_split)
backgroud_Image = plt.imread(pic_path)
stopwords = STOPWORDS.copy()
with open(stopwords_path, 'r', encoding='utf-8') as f:
for i in f.readlines():
stopwords.add(i.strip('\n'))
f.close()
wc = WordCloud(width=1024, height=768, background_color='white',
mask=backgroud_Image, font_path="C:\simhei.ttf",
stopwords=stopwords, max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
img_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')
plt.show()
wc.to_file(pic_name)
 jiangwen.jpg
jiangwen.jpg
姜文背景图
 邪不压正_词云图.png
邪不压正_词云图.png
邪不压正词云图
台词
从词云图中可以探究到,评论多次提到“台词”,《邪不压正》的台词确实依旧带着浓浓的姜文味,例如
一、治脚吗?不治。治治吧。不治。治治。《邪不压正》
二、怎么相信一个写日记的人。《邪不压正》
三、“我就是为了这醋,包了一顿饺子”。《邪不压正》
四、冰川期就要来了,海平面降低了,那几个岛越来越大,跟澳大利亚连一块儿了。《邪不压正》
五、你总是给自己设置障碍,因为你不敢。《邪不压正》
六、正经人谁写日记啊。《邪不压正》
七、都是同一个师傅教的,破不了招啊。《邪不压正》
八、你对我开枪,不怕杀了我,不怕。你不爱我,傻瓜,子弹是假的。《邪不压正》
九、外国男人只想乱搞,中国男人都想成大事。《邪不压正》
十、老蒋更不可靠,一个写日记的人能可靠吗,正经人谁写日记啊?《邪不压正》
十一、你每犯一次错,就会失去一个爸爸。《邪不压正》
十二、谁把心里话写日记里啊,日记这玩意本来就不是给外人看,要是给外人看了,就俩字下贱!《邪不压正》
十三 、咳咳…还等什么呢。——姜文《邪不压正》
十四、我当时问你在干嘛,你拿着肘子和我说:真香。《邪不压正》
十五、“我要报仇!”“那你去呀!你不敢?”“我等了十五年了,谁说我不敢?”“那你为什么不去,你不敢”“对,我不敢”《邪不压正》
喜欢
虽然这部影片评分和姜文之前的优秀作品相比显得寒酸,但是观众们依旧对姜导演抱有期望,支持和喜爱,期待他后续更多的精彩作品;程序刚跑完,词云里突然出现个爸爸,让我卡顿了(PS:难道程序bug了???),接着才想起来是影片中的姜文饰演的蓝爸爸,以此称呼姜导,可见铁杆粉丝的满满爱意~
一步之遥
同时可以发现评论中,姜文的另一部作品《一步之遥》也被提及较多。诚然,《邪不压正》确实像是《让子弹飞》和《一步之遥》的糅合,它有着前者的邪性与潇洒,又带有后者的戏谑和浪漫。因而喜欢《一步之遥》的观众会爱上本片,反之不待见的观众也会给出《一步之遥》的低分。
 xuzheng.jpg
xuzheng.jpg
徐峥背景图
 我不是药神_词云图.png
我不是药神_词云图.png
我不是药神词云图
高频重点词汇有:
- 中国
- 题材
- 现实
- 煽情
- 社会
- 故事
- 好看
- 希望
词云分析结果展现出的强烈观感有一部分原因是《我不是药神》的意外之喜,宁浩和徐峥两个喜剧界的领军人物合作,很自然的以为会是喜剧路数,谁能想到是一部严肃的现实题材呢?
倘若是尚未观看本片的读者,仅从情感分析的角度看,我相信也可以下对本片下结论:值得去影院体验的好电影。正如我在文章开篇所说,《药神》的诞生,给中国当前的影片大环境带来了一股清流,让人对国产电影的未来多了几分期许。
7总结
- 练习一下pandas操作和爬虫,
- 没有自己构建该领域的语料库,如果构建了相关语料库,替换默认语料库,情感分析准确率会高很多。所以语料库是非常关键的,如果要正式进行文本挖掘,建议要构建自己的语料库。
- pyecharts画图挺别致的
附录一下爬取分析的“邪不压正”的电影数据,因为图形和分析过程相似,所以就不单独放图了,(ps:姜文这次没有给人带来太大的惊喜==)
视频链接如下:https://www.useloom.com/embed/aeb66b3d47ce430daa572b649931d349
如果帮到了您,可否打赏一只小龙虾呢o(∩_∩)o 哈哈
 pay.jpg
pay.jpg