字符串也是元组的一种,本章会介绍:字符串的格式化、分割、联接、搜索。
基本字符串操作
所有标准的序列操作对字符串同样适用,唯一要记得的是字符串是不可变的,如下的操作是不合法的:
website = 'http://python.org'
website[-3:] = 'com' //TypeError
字符串格式化:精简版
>>> format = "hello, %s"
>>> values =('world')
>>> format % values
'hello, world'
>>> format = "Pi with three decimals: %.3f"
>>>from math import pi
>>>print format % pi
Pi with three decimals: 3.142
字符串是很多编程语言中都会频繁被使用到的,该部分只是简单介绍字符串的格式化,在下一节会有详细的说明。
如上,%为字符串格式化操作符,操作符的左边是希望格式化的字符串,右边是格式化的值。上例中用于格式化的值是一个元组,用其他的会有什么样的结果属于下一章的讨论范畴。
%s是期望接受字符串,%.3f期望接受小数点后有三位的浮点数。
字符串格式化:完整版
格式化操作符%右边可以是任何东西,当右边是元组和字典(尚未介绍)的时候结果会有不同。本章只介绍右边是元组的情况。右操作数是元组的时候,每个元素都会被单独格式化,每个元组中的值都要对应一个做操作数中的字符转换说明符。
转换说明符包含以下部分:
(1)%:转换说明符的开始
(2)转换标识(可选): -/+/' '/0
(3)最小字段宽度
(4)(.):后跟精度值
(5)转换类型:......
简单转换
如下是几个练习,可以尝试下,在下方有答案:
练习1 'Price of eggs: $42'
练习2 'Hexidecimal price of eggs: 2a'
练习3 'Pi: 3.141593......'
练习4 'Very inexact estimate of Pi: 3'
练习5 'Using str:42'
练习5 'Using repr:42L'
答案1
>>> 'Price of eggs: $%d' % 42
答案2
>>> 'Price of eggs: %x' % 42
答案3
>>> from math import pi
>>> 'Pi: %f......' % pi
答案4
>>> from math import pi
>>> 'Very inexact estimate of Pi: %i' % pi
答案5
>>> 'Using str: %s' % 42L
答案6
>>> 'Using repr: %s' % repr(42L) 或 'Using repr: %r' % 42L
字段宽度和精度
>>> '%10.2f'%pi
' 3.14' #字段宽为10,精度为2
>>> '%10f'%pi
' 3.141593' #字段宽为10
>>> '%.*s' % (5,'Gui Vanchi')
'Gui V' #使用*会从右操作数中去读取参数
符号、对齐和0填充
>>> '%010.2f'%pi
'0000003.14' #在字符宽度前加0会将结果前面的空格用0填充
>>> '%-10.2f'%pi
'3.14 ' #加-号会使结果左对齐
>>> print('% 5d' % 10) + '\n' + ('% 5d' % -10)
10
-10 # 加‘ ’可以方便同样的缩进
>>> print('%+5d' % 10) + '\n' + ('%+5d' % -10)
+10
-10 #加+可以保证结果中包含正负有同样的缩进
围绕上述所提到的这些知识点,该书书写了一个例子,要求的输出结果如下所示。可以自己写代码试试看,参考答案在下面:
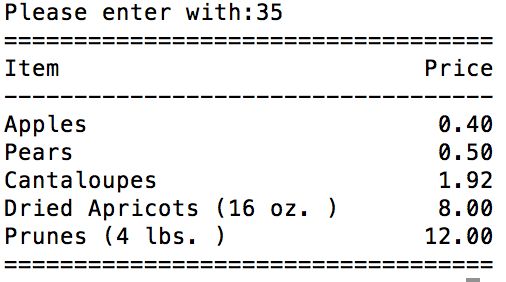
如下为个人的版本:
width = int(raw_input('Please enter with:'))
print '=' * width
print 'Item' + '% *s' % (width - len('Item'), 'Price')
print '-' * width
print 'Apples' + '% *s' % (width - len('Prices'), '0.40')
print 'Pears' + '% *s' % (width - len('Pears'), '0.50')
print 'Cantaloupes' + '% *s' % (width - len('Cantaloupes'), '1.92')
print 'Dried Apricots (16 oz. )' + '% *s' % (width - len('Dried Apricots (16 oz. )'), '8.00')
print 'Prunes (4 lbs. )' + '% *s' % (width - len('Prunes (4 lbs. )'), '12.00')
print '=' * width
如下为该书给出的示例版本(生在做了抽象和使用了“-”来左对齐):
width = int(raw_input('Please enter with:'))
price_width = 10
item_width = width - price_width
head_format = '%-*s%*s'
list_format = '%-*s%*.2f'
print '=' * width
print head_format % (item_width, 'Item', price_width, 'Price')
print '-' * width
print list_format % (item_width, 'Apples', price_width, 0.4)
print list_format % (item_width, 'Pears', price_width, 0.5)
print list_format % (item_width, 'Cantaloupes', price_width, 1.92)
print list_format % (item_width, 'Dried Apricots (16 oz. )', price_width, 8.00)
print list_format % (item_width, 'Prunes (4 lbs. )', price_width, 12)
print '=' * width
字符串方法
字符串方法有很多,在该书的附录B中又详细描述,如下只列举最常用的方法:
-
find()
find方法提供了在字符串中查找子字符串的功能,找到了返回子字符串左端索引,否则返回-1。还可以指定查找范围:通过指定开始索引位置和终止索引位置。>>> sentence = 'Klay Thompson is as smart of a defender as it gets.' >>> sentence.find('Thompson') 5 >>> sentence.find('Lebron') -1 >>> sentence.find('Thompson', 8) -1 join()
join方法是split方法的逆方法,join的列表中必须都是字符串。
>>> seq = [1,2,3,4,5]
>>> ','.join(seq) //TypeError
>>> seq = ['1','2','3','4', '5']
>>> ','.join(seq)
'1,2,3,4,5'
>>> dirs = '', 'usr', 'bin', 'env'
>>> '/'.join(dirs)
'/usr/bin/env'
>>> print 'C:' + '\\'.join(dirs)
C:\usr\bin\env
-
lower()
>>> 'The defensive philosophies of Klay Thompson'.lower() 'the defensive philosophies of klay thompson' replace()
>>> 'This is an egg'.replace('is', 'ezz')
'Thezz ezz an egg' #替换所有匹配项
-
split()
>>> '1,2,3,4,5'.split(',') ['1', '2', '3', '4', '5'] >>> '/usr/bin/env'.split('/') ['', 'usr', 'bin', 'env'] >>> 'Using the default'.split() ['Using', 'the', 'default'] -
strip()
>>> ' Thompson read it easily. '.strip() 'Thompson read it easily.' translate()
>>> from string import maketrans
>>> table = maketrans('cs', 'kz')
>>> 'This is an incredible test'.translate(table)
'Thiz iz an inkredible tezt'
>>> 'This is an incredible test'.translate(table,' ')
'Thizizaninkredibletezt'
maketrans指定了要替换的字符匹配关系,将得到的table作为参数传递给translate就可以进行“多”字符的替换了。其中第二个参数可以指定要删除的字符串。