文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
转自 | 法纳斯特(公众号ID:walker398)
作者 | 小F
决策树呈树形结构,是一种基本的回归和分类方法。
决策树模型的优点在于可读性强、分类速度快。
下面通过从「译学馆」搬运的两个视频,来简单了解下决策树。
最后来实战一波,建立一个简单的决策树模型。
01
决策树算法
本次主要涉及两类决策树,Quinlan系列决策树和CART决策树。
前者涉及的算法包括ID3算法、C4.5算法及C5.0算法,后者则是CART算法。
前者一系列算法的步骤总体可以概括为建树和剪树。
在建树步骤中,首先选择最有解释力度的变量,接着对每个变量选择最优的分割点进行剪树。
剪树,去掉决策树中噪音或异常数据,在损失一定预测精度的情况下,能够控制决策树的复杂度,提高其泛化能力。
在剪树步骤中,分为前剪枝和后剪枝。
前剪枝用于控制树的生成规模,常用方法有控制决策树最大深度、控制树中父结点和子结点的最少样本量或比例。
后剪枝用于删除没有意义的分组,常用方法有计算结点中目标变量预测精度或误差、综合考虑误差与复杂度进行剪树。
此外在ID3算法中,使用信息增益挑选最有解释力度的变量。
其中信息增益为信息熵减去条件熵得到,增益越大,则变量的影响越大。
C4.5算法则是使用信息增益率作为变量筛选的指标。
CART算法可用于分类或数值预测,使用基尼系数(gini)作为选择最优分割变量的指标。
02
Python实现
对一份汽车违约贷款数据集进行读取数据、数据清洗。(数据来源于《python数据科学:技术详解与商业实践》一书)
importos
importpydotplus
importnumpyasnp
importpandasaspd
importsklearn.treeastree
importmatplotlib.pyplotasplt
fromIPython.displayimportImage
importsklearn.metricsasmetrics
fromsklearn.treeimportDecisionTreeClassifier
fromsklearn.model_selectionimporttrain_test_split, ParameterGrid, GridSearchCV
# 消除pandas输出省略号情况
pd.set_option('display.max_columns',None)
# 设置显示宽度为1000,这样就不会在IDE中换行了
pd.set_option('display.width',1000)
# 读取数据,skipinitialspace:忽略分隔符后的空白
accepts = pd.read_csv('accepts.csv', skipinitialspace=True)
# dropna:对缺失的数据进行删除
accepts = accepts.dropna(axis=0, how='any')
# 因变量,是否违约
target = accepts['bad_ind']
# 自变量
data = accepts.ix[:,'bankruptcy_ind':'used_ind']
# 业务处理,loan_amt:贷款金额,tot_income:月均收入
data['lti_temp'] = data['loan_amt'] / data['tot_income']
data['lti_temp'] = data['lti_temp'].map(lambdax:10ifx >=10elsex)
# 删除贷款金额列
deldata['loan_amt']
# 替换曾经破产标识列
data['bankruptcy_ind'] = data['bankruptcy_ind'].replace({'N':0,'Y':1})
接下来使用scikit-learn将数据集划分为训练集和测试集。
# 使用scikit-learn将数据集划分为训练集和测试集
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size=0.2, train_size=0.8, random_state=1234)
初始化一个决策树模型,使用训练集进行训练。
采用基尼系数作为树的生长依据,树的最大深度为3,每一类标签的权重一样。
# 初始化一个决策树模型
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, class_weight=None, random_state=1234)
# 输出决策树模型信息
print(clf.fit(train_data, train_target))
输出的模型信息如下。

对生成的决策树模型进行评估。
# 输出决策树模型的决策类评估指标
print(metrics.classification_report(test_target, clf.predict(test_data)))
# 对不同的因变量进行权重设置
clf.set_params(**{'class_weight': {0:1,1:3}})
clf.fit(train_data, train_target)
# 输出决策树模型的决策类评估指标
print(metrics.classification_report(test_target, clf.predict(test_data)))
# 输出决策树模型的变量重要性排序
print(list(zip(data.columns, clf.feature_importances_)))
输出如下。
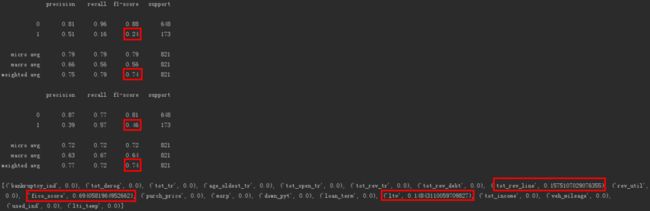
可以看出对因变量标签进行权重设置后,模型对违约用户的f1-score(精确率和召回率的调和平均数)提高了,为0.46。
违约用户被识别的灵敏度也从0.24提高到了0.46。
此外决策树模型的变量重要性排序为「FICO打分」、「信用卡授权额度」、「贷款金额/建议售价*100」。
通过安装graphviz和相应的插件,便能实现决策树的可视化输出,具体安装过程不细说。
# 设置graphviz路径
os.environ["PATH"] += os.pathsep +'C:/Program Files (x86)/Graphviz2.38/bin/'
# 决策树的可视化
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=data.columns, class_names=['0','1'], filled=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
# 将决策树模型输出为图片
graph.write_png(r'pang.png')
# 将决策树模型输出为PDF
graph.write_pdf('tree.pdf')
可视化结果如下。
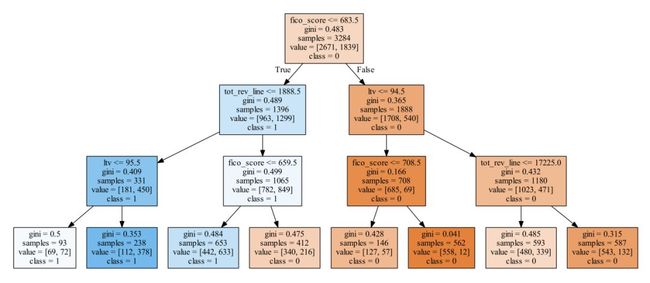
可以看见决策树根节点以fico_score <= 683.5为分割标准。
全体样本的基尼系数为0.483,在3284个样本中,被预测变量为0的有2671个,为1的有1839个。
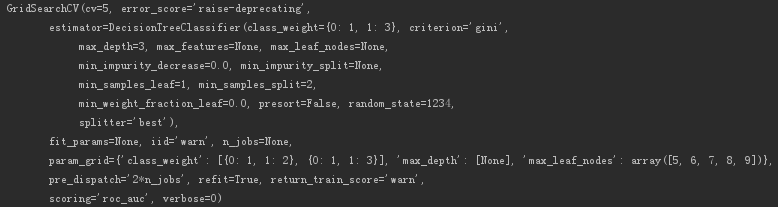
使用scikit-learn提供的参数搜索进行调优(GridSearchCV)。
# 设置树的最大深度
max_depth = [None, ]
# 设置树的最大叶节点数
max_leaf_nodes = np.arange(5,10,1)
# 设置树的类标签权重
class_weight = [{0:1,1:2}, {0:1,1:3}]
# 设置参数网格
param_grid = {'max_depth': max_depth,
'max_leaf_nodes': max_leaf_nodes,
'class_weight': class_weight}
# 对参数组合进行建模和效果验证
clf_cv = GridSearchCV(estimator=clf,
param_grid=param_grid,
cv=5,
scoring='roc_auc')
# 输出网格搜索的决策树模型信息
print(clf_cv.fit(train_data, train_target))
输出网格搜索的决策树模型信息。
使用得到的“最优”模型对测试集进行评估。
# 输出优化后的决策树模型的决策类评估指标
print(metrics.classification_report(test_target, clf_cv.predict(test_data)))
# 输出优化后的决策树模型的参数组合
print(clf_cv.best_params_)
输出结果。

计算模型在不同阈值下的灵敏度和特异度指标,绘制ROC曲线。
# 使用模型进行预测
train_est = clf_cv.predict(train_data)
train_est_p = clf_cv.predict_proba(train_data)[:,1]
test_est = clf_cv.predict(test_data)
test_est_p = clf_cv.predict_proba(test_data)[:,1]
# 绘制ROC曲线
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[3,3])
plt.plot(fpr_test, tpr_test,'b--')
plt.plot(fpr_train, tpr_train,'r-')
plt.title('ROC curve')
plt.show()
# 计算AUC值
print(metrics.roc_auc_score(test_target, test_est_p))
ROC曲线图如下,其中训练集的ROC曲线(实线)与测试集的ROC曲线(虚线)很接近,说明模型没有过拟合。
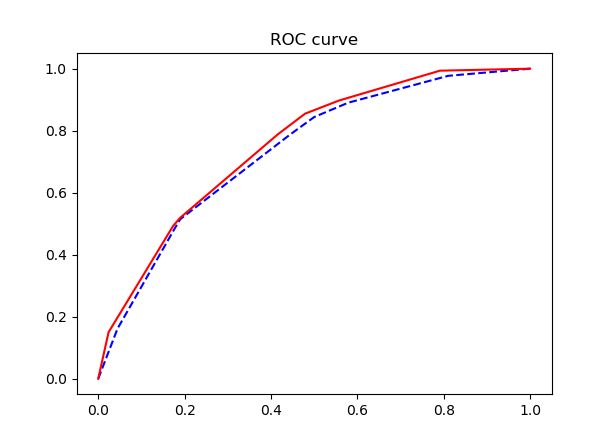
模型的ROC曲线下面积为0.7358,模型效果一般。
推荐阅读:





星标我,每天多一点智慧