Subword Models
一、Morphology: Parts of words
在传统上,我们通常将语素作为最小的语义单位。
在深度学习中:形态学方面研究很少;下面的图片展示了RNN在形态学方面的应用:

处理大词汇表的可能的方法是使用最不可见的单词的新的形态形式来构造词汇表。
在这方面最简单的想法就是使用字符级别的n-gram或则使用字符级别的CNN。下面我们来介绍一下Character-Level Models。
1、Character-Level Models
通常,word embeddings可以由character embeddings来组成。除此之外它还可以,为未知单词生成embedding、不同的词可以类似的拼写一样共享类似的embeddings、解决OOV问题。
这样,一句连续的话,就可以一字符集别的方式进行处理。
1.Purely character-level models
这类模型有很多,包括
1.服务于句子分类的字符集别的模型--VDCNN,它通过非常深的网络结构产生了一个比较好的结果。
2.Fully Character-Level Neural Machine Translation without Explicit Segmentation
模型结构及其结果:

3.Stronger character results with depth in LSTM seq2seq model
论文出处:Revisiting Character-Based Neural Machine Translation with Capacity and Compression. 2018.Cherry, Foster, Bapna, Firat, Macherey, Google AI
二、子词模型的趋势
1、主要趋势
1.与单词级别的模型架构相同,但使用的是字符级别的输入
2.采用混合架构,输入主要是字符,但是会混入其他信息
2、Byte Pair Encoding
Byte Pair Encoding最初是一种压缩算法,其主要是使用一些出现频率高的byte pair来组成新的byte。
但它也可别作为一种分词算法(尽管其本质是自下而上的聚类方法),它以数据中所有(Unicode)字符的单字组词汇开头并且使用最常见的n-gram对来组成一个新的n-gram。
例如使用常见的n-gram来组成一个词汇表,然后用词汇表中的n-gram来
组成新的n-gram,这样就避免了以往使用词级别的词汇表带来的词汇表过大的问题。
这个算法有一些需要注意的地方:
1.有一个目标词汇量大小并在到达时停止训练
2.需要确定单词的最长分割片段
3.分词过程仅在由某些先前的标记器(通常为MT的Moses标记器)标识的单词内进行。
4.自动决定系统的词汇,不再以常规方式过度使用“单词”
3、Wordpiece/Sentencepiece model
Google NMT使用了借鉴了上面的方法,其V1使用的是wordpiece mode,V2使用的是sentecepiece model。它并没有采取字符集别的n-gram计数方法,而是使用贪心近似来最大化语言模型日志可能性来选择片段,添加n-gram信息,是为了最大限度地减少perplexity。Wordpiece模型标记化内部的单词,Sentencepiece模型则对原始文本进行处理。
BERT模型使用的是wordpiece的变体,对于一些常见词如1910s、at、fairfax等词直接使用;对于其他词则根据wordpieces来构建。需要注意方在其他任务中使用bert时,必须处理这个问题。
4、Character-level to build word-level
Learning Character-level Representations for Part-of�Speech Tagging (Dos Santos and Zadrozny 2014)

该网络结构主要是对字符进行卷积以生成单词嵌入,同时使用
固定窗口对PoS标记的字嵌入进行操作。
后续还有人使用双向LSTM来将charater embedding构建成word embedding

5、Character-Aware Neural Language Models
Yoon Kim, Yacine Jernite, David Sontag, Alexander M. Rush. 2015
这是一个更加复杂的方法,其主要动机在于:
提供一种功能强大,功能强大的语言模型,可以在各种语言中有效。
•编码子词相关性:eventful, eventfully, uneventful…
•解决先前模型的罕见字问题。
•使用更少的参数获得可比较的表现力。
模型结构图如下:

其卷积层的结构如下:

Highway Network结构图及涉及公式如下:
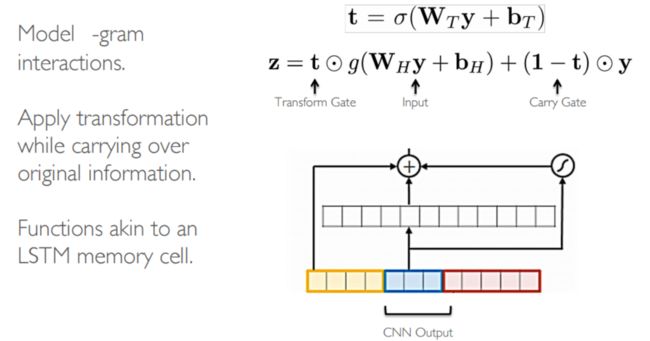
LSTM单元结构图如下:

首先,论文质疑使用文字嵌入作为神经语言建模的输入的必要性。其次,CNNs +高速公路网络可以提取丰富的语义和结构信息。
6、Hybrid NMT
这是一个非常出色的框架,主要是在单词级别进行翻译,但是在有需要的时候可以很方便的使用字符级别的输入。
其网络结构图如下:

该模型还同时对word-level和char-level进行了beam search操作,并且对隐藏层进行了初始化操作。

7、chars for word embeddings
A Joint Model for Word Embedding and Word Morphology(Cao and Rei 2016
该模型的目标与word2vec相同,但是使用的时字符集别的输入。它使用了双向的LSTM结构尝试捕获形态并且能够推断出词根。

8、fasttext
Enriching Word Vectors with Subword InformationBojanowski, Grave, Joulin and Mikolov. FAIR. 2016.
论文地址:https://arxiv.org/pdf/1607.04606.pdf or https://fasttext.cc
它是word2vec的升级版,对于具有大量形态学的稀有词和语言有更好的表征,它也可以说是带有字符n-gram的w2v skip-gram模型的扩展。其核心思想在于:将单词的向量表示为字符n-gram用边界符号和整个单词表示的向量的叠加:where =

该论文还使用了散列表来存储所有的n-gram的表示,这样可以减少内存的占用。