基础知识
Trie树
Trie是一种搜索树,又称字典树(digital tree)和前缀树(prefix tree)。不同与二叉搜索树,键值并不是由树中的节点存储,而是取决于其在树中的位置,或者说是从根到达节点的路径。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。

图中,键不需要被显式地保存在节点中,只是为了演示。
Patricia树
Patricia树又称压缩前缀树(compact prefix tree),是一种更节省空间的Trie。对于Patricia树的每个节点,如果该节点是唯一的儿子的话,就和父节点合并。那么一棵Patricia树的任何内部节点有2个或以上的孩子节点。下图存储的内容和第一幅图一致,可以看出节点数目减少了很多。

哈希列表
哈希列表(Hash List)是存储hash值的列表。通常除了哈希列表自身以外,会有一个额外的根哈希(Root Hash or top hash)用来存储哈希列表的哈希。

在点对点网络中作数据传输的时候,会把大的文件分割成小的数据块,然后同时从多个机器上下载数据块。这样的好处是,如果小块数据在传输过程中损坏了,那么只要重新下载这一块数据就行了,不用重新下载整个文件。但是在网络中很多机器是不稳定或者不可信的,需要对数据库的真实性和完整性进行校验。这个时候就需要用到哈希列表。在开始的时候需要为每个数据块做Hash,并运算得到数据的根哈希。下载数据的时候,首先从可信的数据源得到正确的根Hash,就可以用它来校验Hash列表了,然后通过校验后的Hash列表校验数据块。
Merkle树
Merkle Tree,通常也被称作Hash Tree,是存储hash值的一棵树。Merkle Tree可以看做Hash List的泛化(Hash List可以看作一种特殊的Merkle Tree,即树高为2的多叉Merkle Tree。)
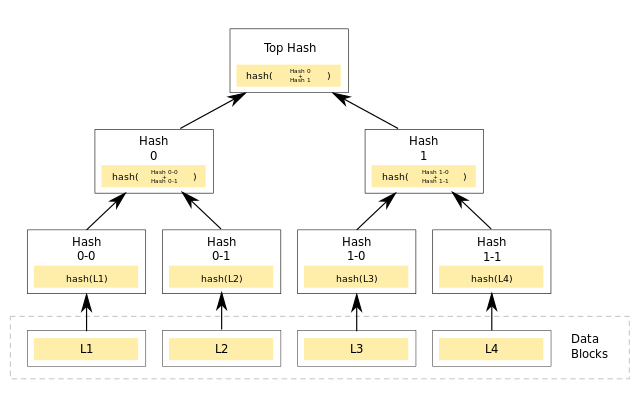
在最底层,和哈希列表一样,数据被分成小的数据块,有相应地哈希和它对应。上一层,并不是直接去运算根哈希,而是把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,这样逐层进行哈希合并运算,到最后就可以生成一个根hash。
Merkle Tree和HashList的主要区别是,可以直接下载并立即验证Merkle Tree的一个分支。
Merkle Tree的主要作用是当拿到Top Hash的时候,这个hash值代表了整颗树的信息摘要,当树里面任何一个数据发生了变动,都会使得从当前节点到根节点的Hash的值都会发生变化,而其他子树不会有变化。而Top Hash的值是会存储到区块链的区块头里面去的,区块头是必须经过工作量证明。

以太坊中的MPT
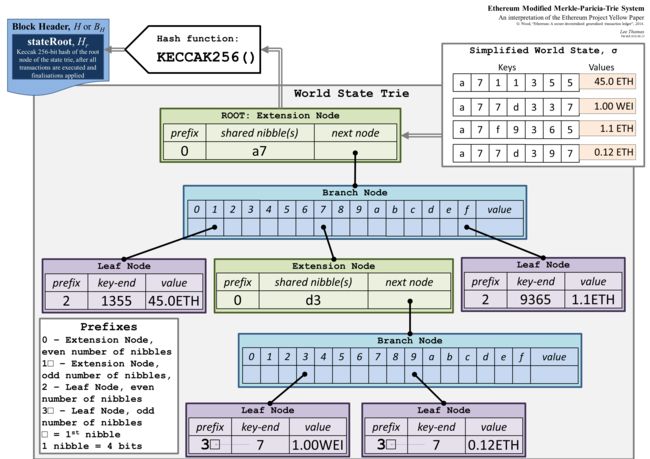
以太坊中的MPT(Merkle Patricia Tree)与第一部分中的数据结构相比,MPT树从结构上看是一棵Patricia树,每个节点保存一个hash值,因此也可以起到Merkle Tree的作用。
对于MPT来说,其主要作用是用来存储一系列的kv对,如公式188定义。此处key是任意长度的二进制数组,value也是任意长度的二进制数组。为了方便用数字下标来对kv对中的每个元素进行索引,将每一个(key,value)定义为公式189的形式。
以太坊的MPT树中需要将key值转化为十六进制的表示形式,这样在存储的时候key作为一棵树,其范围为[0..f],即分叉的节点最多有16种分叉的可能。将key值转化为十六进制的方法如公式191所示,将原先的一个字节拆成两个半字节,而每个半字节的值都不会超过16,即在[0..f]范围内。对key进行处理过后的key,value对,可以表示成公式190的形式。
以太坊中的MPT中有4种节点:
- NULL节点,用一个空的字符串表示。
- 分之(branch)节点,17元组[v0...v15,vt]。其前16个项对应于这些点在其遍历中的键的十六个可能的半字节值中的每一个。第17个字段是存储那些在当前结点结束了的节点(例如, 有三个key,分别是 (abc ,abd, ab) 第17个字段储存了ab节点的值)
- 叶子(leaf)节点,2元组[encodedPath,value]。第一个字段是剩下的Key的半字节编码, 第二个字段是Value。
- 扩展(extension)节点,2元组[encodePath,key]。第一个字段是剩下的Key的半字节编码, 第二个字段指向另一个节点。
构造过程大致为:
- 如果当前只有一个kv对,则直接将其构造成一个叶子节点。
- 如果当前需要编码的kv集合,有公共前缀,那么提取公共前缀,将公共前缀构造成一个扩展节点,并将其第二个字段指向下一个节点(一般为分支节点)。
- 如果不是上面的两种情况,则构造分支节点按照当前key所在索引的16进制对kv集合进行划分,[0..f]分别指向下一个节点。如果有kv对在此节点终结,则将其存储在value中。
以太坊中MPT的结构示例如下图:(实际的实现上有些地方是不一样的)
十六进制前缀编码
十六进制前缀编码是将任意数量的半字节(nibble,半个字节也就是4个bit,16进制的一位数字)编码为字节数组的有效方法。通过添加前缀,其可以存储附加标识,在Trie中使用时,会在节点类型间消除歧义。
当半字节长度为偶数时,第一个高半字节为前缀,低半字节置0,后面的每个字节都是将两个半字节组合在一起。
当半字节长度为奇数时,第一个高半字节为前缀,低半字节为半字节的第一个半字节,后面的每个字节都是将两个半字节组合在一起。
-
第一个字节的高半字节包含两个标志,最低位表示奇偶(0为偶,1为奇),第二低位编码flag。实际中就是编码以太坊中的不同类型的节点。
hex char bits node type partial path length 0 0000 extension even 1 0001 extension odd 2 0010 terminating (leaf) even 3 0011 terminating (leaf) odd
MPT的序列化
MPT在数据库中的实际存储是存储的hash值与即节点的序列化形式的对。
序列化主要是指把内存表示的数据存放到数据库里面, 反序列化是指把数据库里面的Trie数据加载成内存表示的数据。 序列化的目的主要是方便存储,减少存储大小等。 反序列化的目的是把存储的数据加载到内存,方便Trie树的插入,查询,修改等需求。
Trie的序列化主要使用了前面介绍的十六进制前缀编码和RLP编码格式。
定义TRIE函数,用来表示树根的HASH值(其中c函数的第二个参数,意为key值的起始index,所以root对应的值为0)
对于每个节点,如公式193所示。如果该节点的序列化长度小于32,则直接存储其序列化,否则存储器序列化后的hash值。这里,主要是在公式194中使用,是一个节点指向另一个节点时,是把该子节点直接存储在父节点中还是将其hash值存储在父节点中(真正的值会单独存的)。
对于每一个节点存储时首先对节点进行RLP编码处理,如公式194所示
- 如果当前需要编码的KV集合只剩下一条数据,那么该节点是一个叶子节点,按照第一条规则编码,将nibble形式的key,与表示叶子节点的true值一起进行十六进制前缀编码,并将结果和value一起进行RLP编码。
- 如果当前需要编码的KV集合有公共前缀,那么提取最大公共前缀。第二个字段递归存储下一个节点。
- 如果不是上面两种情况,那么使用分支节点进行集合切分。可以看到u的值由n进行递归定义,而如果有节点刚好在这里完结了,那么第17个元素v就是为这种情况准备的。
以太坊中的MPT
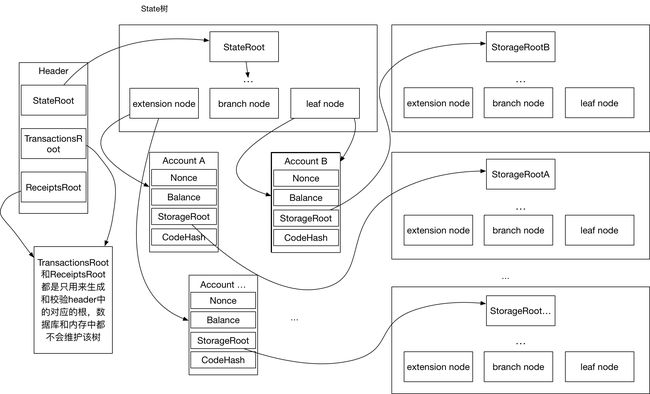
以太坊中的所有的merkle树都是指Merkle Patricia Tree。
从区块头中可以看到有3棵MPT的根。
- stateRoot
- transcationsRoot
- receiptsRoot
State树
State树是一棵全局的树,它的key是sha3(ethereumAddress),即账户地址的hash值。其存储的值value为rlp(ethereumAccount),即账户信息的rlp编码。其中账户信息是一个[nonce,balance,storageRoot,codeHash]的四元组,其中storageRoot指向账户的Storage树。
Storage树
一般的外部账户Storage为空,而合约账户通常会储存一定的数据,这些数据就是存储在合约账户的Storage树中,storage树中的key与账户地址和其中实际存储的key有关,其value值为合约定义的value值。
Transactions树
每一个区块都会有一棵Transactions树,其key为rlp(transactionIndex)(交易在区块中的编号,0,1...),其value值为经过rlp编码的交易。在实际情况中该树并不会真的存储到数据库中,只是在生成block以及校验block的时候用于得到当前区块的TransactionsRoot。实际中一条交易连同同一区块的其他交易以及区块的uncles是被存储在一个条目中的。
Receipts树
每一个区块都会有一棵Receipts树树,其key为rlp(transactionIndex)(交易在区块中的编号,0,1...),其value值为经过rlp编码的交易收据。在实际情况中该树并不会真的存储到数据库中,只是在生成block以及校验block的时候用于得到当前区块的ReceiptsRoot。实际中同一个区块的交易收据会一起编码然后存储在一个条目中的。