扩展阅读:
- Apache Kylin 查询流程源码剖析 -
- 可能是全网最深度的 Apache Kylin 查询剖析 -
一、什么是 Kylin
Apche Kylin 是 Hadoop 大数据平台上的一个开源 OLAP 引擎。它采用多维立方体(Cube)预计算技术,可以将某些场景下的大数据 SQL 查询速度提升到亚秒级别。相对于之前的分钟乃至小时级别的查询速度。
Apache Kylin 也是中国人主导的,第一个 Apche 顶级开源项目,在开源社区有较大影响力。
Kylin 对于解决的问题有以下假设:
- 大数据查询要的一般是统计结果,是多条记录经过聚合函数计算后的统计值
- 原始的记录则不是必需的,或者访问频率和概率都极低
- 聚合是按维度进行的,有意义的维度聚合组合也是相对有限的,一般不会随着数据的膨胀而膨胀
基于以上两点,可以得到一个新的思路—预计算,应尽量多地预先计算聚合结果,在查询时应该尽量利用预计算的结果得出查询结果,从而避免直接扫描可能无限增大的原始记录
二、定义 Cube
2.1、什么是 Cube
Cube 即多维立方体,也叫数据立方体。如下图所示,这是由三个维度(维度数可以超过3个,下图仅为了方便画图表达)构成的一个OLAP立方体,立方体中包含了满足条件的cell(子立方块)值,这些cell里面包含了要分析的数据,称之为度量值。
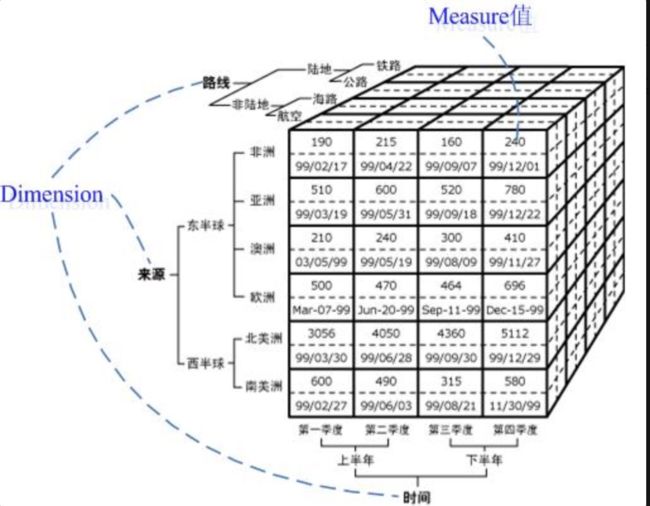
- 立方体:由维度构建出来的多维空间,包含了所有要分析的基础数据,所有的聚合数据操作都在立方体上进行
- 维度:观察数据的角度。一般是一组离散的值,比如:
- 时间维度上的每一个独立的日期
- 商品维度上的每一件独立的商品
- 度量:即聚合计算的结果,一般是连续的值,比如:
- 销售额,销售均价
- 销售商品的总件数
- 事实表:是指存储有事实记录(明细数据)的表,如系统日志、销售记录等;事实表的记录在不断地动态增长,数据量大
- 维度表(维表):保存了维度值,可以跟事实表做关联。常见的维度表如:
- 日期表
- 地点表
- 分类表
- Cuboid:对于每一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为 Cuboid
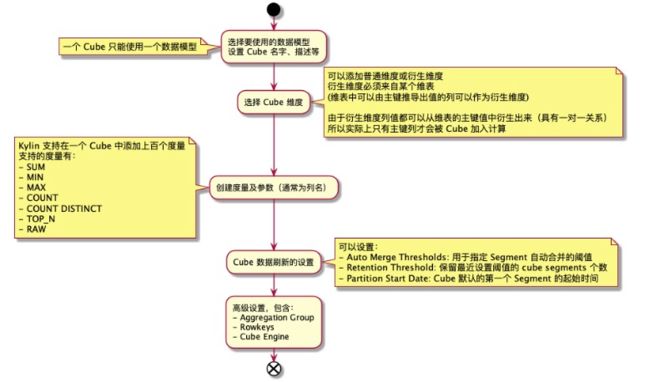
2.2、创建数据模型
2.2.1、数据模型
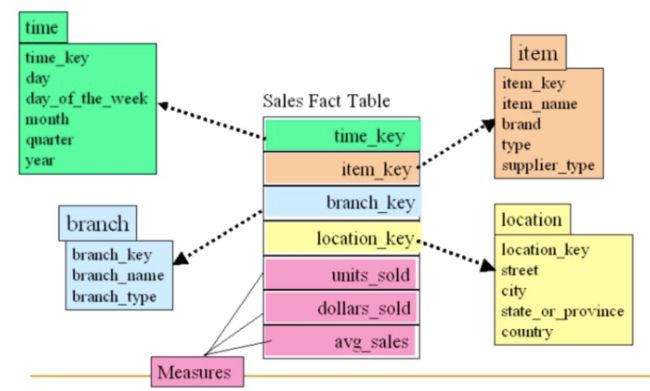
常见的多维数据模型,如星型模型、雪花模型等。星型模型:有一张事实表、以及零个或多个维度表;事实表与维度表通过 主键/外键 相关联,维度表之间没有关联,就像很多星星围绕在一个恒星周围,顾命名为星型模型。
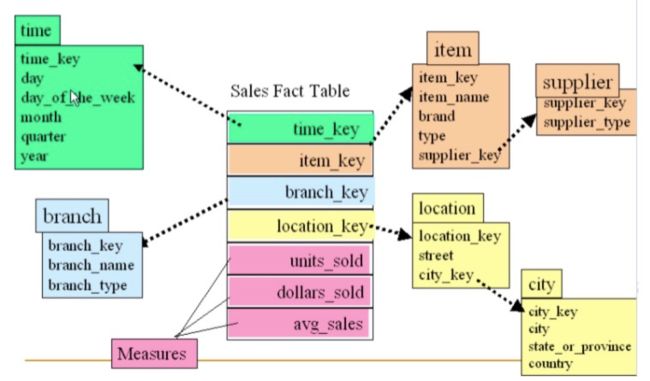
雪花模型:如果将星型模型中某些维度的表再做规范,抽取成更细的维度表,然后让维度表之间也进行关联,那么这种模型成为雪花模型(雪花模型可以通过一定的转换,变为星型模型)
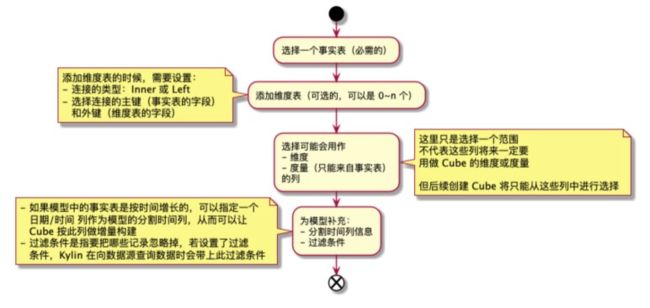
2.2.2、创建模型
- Model 是 Cube 的基础,用于描述一个数据模型
- 有了数据模型,定义 Cube 可以直接从此模型定义的表和列中进行选择
- 基于一个数据模型可以创建多个 Cube
数据模型可用一个 json 表示,如下是一个例子:
{
"name": "test_model", // 名为 test_model 的数据模型
"fact_table": "DEFAULT.KYLIN_SALES", // 事实表为 DEFAULT.KYLIN_SALES
"lookups": [ // 维表(又叫查找表,即lookup表)为 DEFAULT.KYLIN_CAL_DT;维表可以是 0~n 个
{
"table": "DEFAULT.KYLIN_CAL_DT",
"kind": "LOOKUP",
"alias": "KYLIN_CAL_DT",
"join": {
"type": "inner", // KYLIN_SALES 与 KYLIN_CAL_DT 连接方式为 inner join
// join condition 为 KYLIN_CAL_DT.CAL_DT = KYLIN_SALES.PART_DT
"primary_key": [
"KYLIN_CAL_DT.CAL_DT"
],
"foreign_key": [
"KYLIN_SALES.PART_DT"
]
}
}
],
"dimensions": [ // 定义维度,维度可以来自于事实表和维表;后续基于该模型的 Cube 的维度只能从这里定义的 dimensions 中选
{
"table": "KYLIN_SALES",
"columns": [
"PART_DT",
"LEAF_CATEG_ID",
"LSTG_SITE_ID",
"SLR_SEGMENT_CD",
"OPS_USER_ID"
]
},
{
"table": "KYLIN_CAL_DT",
"columns": [
"AGE_FOR_YEAR_ID",
"AGE_FOR_QTR_ID",
"AGE_FOR_MONTH_ID",
"AGE_FOR_WEEK_ID",
"CAL_DT"
]
}
],
"metrics": [ // 定义度量,度量智能来自事实表;后续基于该模型的 Cube 的度量只能从这里定义的 metrics 中选
"KYLIN_SALES.PRICE",
"KYLIN_SALES.ITEM_COUNT",
"KYLIN_SALES.SELLER_ID"
],
"filter_condition": "price > 0", // 定义向数据源查询数据时会带上的过滤条件
"partition_desc": { // 指定 KYLIN_SALES.PART_DT 列作为模型的分割时间列,以支持基于该模型的 Cube 按此列做增量构建
"partition_date_column": "KYLIN_SALES.PART_DT",
"partition_time_column": null,
"partition_date_start": 0,
"partition_date_format": "yyyy-MM-dd",
"partition_time_format": "HH:mm:ss",
"partition_type": "APPEND",
"partition_condition_builder": "org.apache.kylin.metadata.model.PartitionDesc$DefaultPartitionConditionBuilder"
},
}
2.3、创建 Cube

高级设置的一些说明:
- Aggregation Groups:Kylin 默认会把所有维度放在一个聚合组中;如果维度数较多(例如>10),那么建议用户根据查询的习惯和模式,将维度分为多个聚合组。通过使用多个聚合组,可以大大降低 Cube 中 Cuboid 数量。如,一个 Cube 有(M+N)个维度,那么会有
2的(M+N)次方个 Cuboid;如果把这些维度分为两个不相交的聚合组,那么 Cuboid 的数量将减少为2的M次方+2的N次方。在单个聚合组中,可以对维度设置高级属性:- Mandatory Dimensions:必要维度。所有不含此维度的 cuboid 就可以被跳过计算
- Hierarchy Dimensions:层级维度,例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算
- Joint Dimensions:联合维度,有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系)。例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算
- Rowkeys:HBase rowkey上的维度的位置对性能至关重要,可以拖拽维度列去调整其在 rowkey 中位置,位于rowkey前面的列,将可以用来大幅缩小查询的范围。通常建议:
- 将必要维度放在开头
- 然后是在过滤 ( where 条件)中起到很大作用的维度
- 如果多个列都会被用于过滤,将高基数的维度(如 user_id)放在低基数的维度(如 age)的前面,这也是基于过滤作用的考虑
- Cube Engine:Spark 或 Hive
2.3.1、一个 Cube 例子
Cube 可用一个 json 表示,如下是一个例子:
{
"name": "test_cube",
"model_name": "test_model", // 使用名为 model_test 的数据模型
"description": "",
"null_string": null,
"dimensions": [ // 维度,可以来自事实表或维度表
{
"name": "PART_DT",
"table": "KYLIN_SALES",
"column": "PART_DT",
"derived": null
},
{
"name": "LEAF_CATEG_ID",
"table": "KYLIN_SALES",
"column": "LEAF_CATEG_ID",
"derived": null
},
{
"name": "LSTG_SITE_ID",
"table": "KYLIN_SALES",
"column": "LSTG_SITE_ID",
"derived": null
},
{
"name": "SLR_SEGMENT_CD",
"table": "KYLIN_SALES",
"column": "SLR_SEGMENT_CD",
"derived": null
},
{
"name": "OPS_USER_ID",
"table": "KYLIN_SALES",
"column": "OPS_USER_ID",
"derived": null
},
{
"name": "CAL_DT",
"table": "KYLIN_CAL_DT",
"column": "CAL_DT",
"derived": null
},
{
"name": "AGE_FOR_YEAR_ID",
"table": "KYLIN_CAL_DT",
"column": null,
"derived": [
"AGE_FOR_YEAR_ID"
]
},
{
"name": "AGE_FOR_QTR_ID",
"table": "KYLIN_CAL_DT",
"column": null,
"derived": [
"AGE_FOR_QTR_ID"
]
},
{
"name": "AGE_FOR_MONTH_ID",
"table": "KYLIN_CAL_DT",
"column": null,
"derived": [
"AGE_FOR_MONTH_ID"
]
},
{
"name": "AGE_FOR_WEEK_ID",
"table": "KYLIN_CAL_DT",
"column": null,
"derived": [
"AGE_FOR_WEEK_ID"
]
}
],
"measures": [ // 度量,即哪个列做什么聚合计算
{
"name": "_COUNT_",
"function": {
"expression": "COUNT",
"parameter": {
"type": "constant",
"value": "1"
},
"returntype": "bigint"
}
},
{
"name": "_SUM_",
"function": {
"expression": "SUM",
"parameter": {
"type": "column",
"value": "KYLIN_SALES.ITEM_COUNT"
},
"returntype": "bigint"
}
},
{
"name": "_MAX_",
"function": {
"expression": "MAX",
"parameter": {
"type": "column",
"value": "KYLIN_SALES.PRICE"
},
"returntype": "decimal(19,4)"
}
}
],
"dictionaries": [],
"rowkey": { // rowkey 配置,主要关注维度列在 rowkey 中的位置(谁先谁后)
"rowkey_columns": [
{
"column": "KYLIN_SALES.PART_DT",
"encoding": "date",
"encoding_version": 1,
"isShardBy": false
},
{
"column": "KYLIN_SALES.LEAF_CATEG_ID",
"encoding": "dict",
"encoding_version": 1,
"isShardBy": false
},
{
"column": "KYLIN_SALES.LSTG_SITE_ID",
"encoding": "dict",
"encoding_version": 1,
"isShardBy": false
},
{
"column": "KYLIN_SALES.SLR_SEGMENT_CD",
"encoding": "dict",
"encoding_version": 1,
"isShardBy": false
},
{
"column": "KYLIN_SALES.OPS_USER_ID",
"encoding": "dict",
"encoding_version": 1,
"isShardBy": false
},
{
"column": "KYLIN_CAL_DT.CAL_DT",
"encoding": "date",
"encoding_version": 1,
"isShardBy": false
}
]
},
"hbase_mapping": {
"column_family": [
{
"name": "F1",
"columns": [
{
"qualifier": "M",
"measure_refs": [
"_COUNT_",
"_SUM_",
"_MAX_"
]
}
]
}
]
},
"aggregation_groups": [ // aggregation groups 配置,共两个 aggregation groups
{
"includes": [
"KYLIN_SALES.PART_DT",
"KYLIN_SALES.LEAF_CATEG_ID",
"KYLIN_SALES.LSTG_SITE_ID",
"KYLIN_SALES.SLR_SEGMENT_CD",
"KYLIN_SALES.OPS_USER_ID",
"KYLIN_CAL_DT.CAL_DT"
],
"select_rule": {
"hierarchy_dims": [],
"mandatory_dims": [],
"joint_dims": []
}
}
],
"partition_date_start": 0, // Cube 日期/时间 分区起始值
"partition_date_end": 3153600000000, // Cube 日期/时间 分区结束值
"auto_merge_time_ranges": [ // 自动合并小的 segments 到中等甚至更大的 segment
604800000,
2419200000
],
"retention_range": 0, // 不删除旧的 Cube Segment
"engine_type": 4, // 构建 Cube 的引擎为 Spark
"storage_type": 2, // 使用 Hbase 存储 Cube
"override_kylin_properties": {},
"cuboid_black_list": []
}
三、构建 Cube
以使用 Spark 构建 Cube 为例
新创建的 Cube 只有定义,而没有计算的数据,它的状态是 “DISABLED” 的,要想让 Cube 有数据,还需要对它进行构建,Cube 的构建方式通常有两种:
- 全量构建:构建时读取的数据源是全集
- 增量构建:构建时读取的数据源是子集
3.1、构建流程
以全量构建为例,Cube 的构建主要包含以下步骤,由构建引擎来调度执行:
Step1: 创建 Hive 大平表
将创建 Cube 涉及到的维度从原有的事实表和维度表中查询出来组成一条完整的数据插入到一个新的 hive 表中
我们对 2.3.1 小节中举例的 Cube 进行构建,构建在 Kylin 页面上进行,构建是需要选择一个起始时间范围,我们选择开始日期为 2012-01-01,结束日期为 2012-08-01,那么构建时就会执行以下命令:
hive -e "USE default;
DROP TABLE IF EXISTS kylin_intermediate_test_cube_44e5fcfe_e62f_375c_1e91_1d75d2fc6de3;
CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_test_cube_44e5fcfe_e62f_375c_1e91_1d75d2fc6de3
(
KYLIN_SALES_PART_DT date
,KYLIN_SALES_LEAF_CATEG_ID bigint
,KYLIN_SALES_LSTG_SITE_ID int
,KYLIN_SALES_SLR_SEGMENT_CD smallint
,KYLIN_SALES_OPS_USER_ID string
,KYLIN_CAL_DT_CAL_DT date
,KYLIN_SALES_ITEM_COUNT bigint
,KYLIN_SALES_PRICE decimal(19,4)
)
STORED AS SEQUENCEFILE
LOCATION 'hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393
-d8ca-9dfd1b6a9bb9/kylin_intermediate_test_cube_44e5fcfe_e62f_375c_1e91_1d75d2fc6de3';
ALTER TABLE kylin_intermediate_test_cube_44e5fcfe_e62f_375c
_1e91_1d75d2fc6de3 SET TBLPROPERTIES('auto.purge'='true');
-- 根据数据模型定义的 join type 和 join condition 查询各个维度列并 insert 到 hive 表中
INSERT OVERWRITE TABLE kylin_intermediate_test_cube_44e5fcfe_e62f_375c_1e91_1d75d2fc6de3
SELECT
KYLIN_SALES.PART_DT as KYLIN_SALES_PART_DT
,KYLIN_SALES.LEAF_CATEG_ID as KYLIN_SALES_LEAF_CATEG_ID
,KYLIN_SALES.LSTG_SITE_ID as KYLIN_SALES_LSTG_SITE_ID
,KYLIN_SALES.SLR_SEGMENT_CD as KYLIN_SALES_SLR_SEGMENT_CD
,KYLIN_SALES.OPS_USER_ID as KYLIN_SALES_OPS_USER_ID
,KYLIN_CAL_DT.CAL_DT as KYLIN_CAL_DT_CAL_DT
,KYLIN_SALES.ITEM_COUNT as KYLIN_SALES_ITEM_COUNT
,KYLIN_SALES.PRICE as KYLIN_SALES_PRICE
FROM DEFAULT.KYLIN_SALES as KYLIN_SALES
INNER JOIN DEFAULT.KYLIN_CAL_DT as KYLIN_CAL_DT
ON KYLIN_SALES.PART_DT = KYLIN_CAL_DT.CAL_DT
WHERE (price > 0) AND (KYLIN_SALES.PART_DT >= '2012-01-01'
AND KYLIN_SALES.PART_DT < '2012-08-01')
;"
Step2: 构建字典
Kylin 使用字典编码(Dictionary-coder)对 Cube 中的维度值进行压缩:
- 纬度值 -> ID 及 ID -> 维度值。 通过存储 ID 而不是实际值,Cube 的大小会显著减小
- ID 保留值的排序,加速了区间(range)查询
- 减少了内存和存储的占用
对于每一个维度列,都会写入两个文件:
- 维度列 distinct 值
- 字典文件
维度列 distinct 值文件:写出路径为 ${baseDir}/${colName}/${colName}.dci-r-${colIndex},如
hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.OPS_USER_ID/OPS_USER_ID.dci-r-00004
hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.SLR_SEGMENT_CD/SLR_SEGMENT_CD.dci-r-00003
hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.LEAF_CATEG_ID/LEAF_CATEG_ID.dci-r-00001
其内容为该维度列的所有 distinct 值,如:
$ hdfs dfs -cat hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.OPS_USER_ID/OPS_USER_ID.dci-r-00004
ADMIN
MODELER
$ hdfs dfs -cat hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.SLR_SEGMENT_CD/SLR_SEGMENT_CD.dci-r-00003
-99
16
$ hdfs dfs -cat hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.LEAF_CATEG_ID/LEAF_CATEG_ID.dci-r-00001
65
175750
字典文件:写入路径为 ${baseDir}/${colName}/${colName}.rldict-r-${colIndex},如:
hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.OPS_USER_ID/OPS_USER_ID.rldict-r-00004
hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.SLR_SEGMENT_CD/SLR_SEGMENT_CD.rldict-r-00003
hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/fact_distinct_columns/KYLIN_SALES.LEAF_CATEG_ID/LEAF_CATEG_ID.rldict-r-00001
Step3: 构建 Cube
使用逐层算法(Layer Cubing)
一个N维的Cube,是由:
- 1个N维子立方体
- N个(N-1)维子立方体
- N*(N-1)/2个(N-2)维子立方体
- (N-2)*(N-3)/2个(N-3)维子立方体
- ……
- N个1维子立方体
- 1个0维子立方体
构成,总共有2^N个 Cuboid 组成
在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0 维度Cuboid计算出来的时候,整个Cube的计算也就完成了
在介绍如何用 Spark 计算 Cube 之前,让我们看看 Kylin 如何用 MR 做到这一点;图1说明了如何使用经典的“逐层”算法计算四维立方体:第一轮MR从源数据聚合基础(4-D)立方体;第二个MR聚集在基本立方体上以获得三维立方体;使用N + 1轮MR计算所有层的立方体。
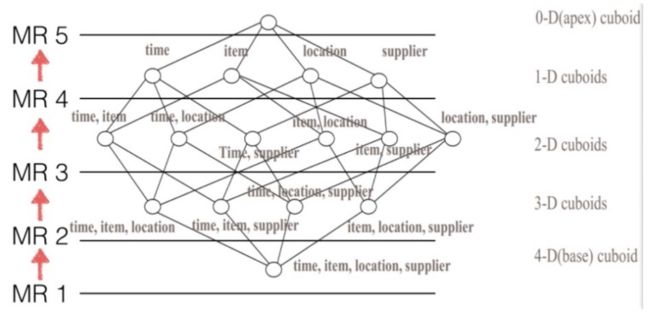
逐层构建将一项大任务划分为几个步骤,每个步骤都基于前一步骤的输出,因此它可以重复使用先前的计算,并且还可以避免在两者之间出现故障时从头开始计算。这使它成为一种可靠的算法。
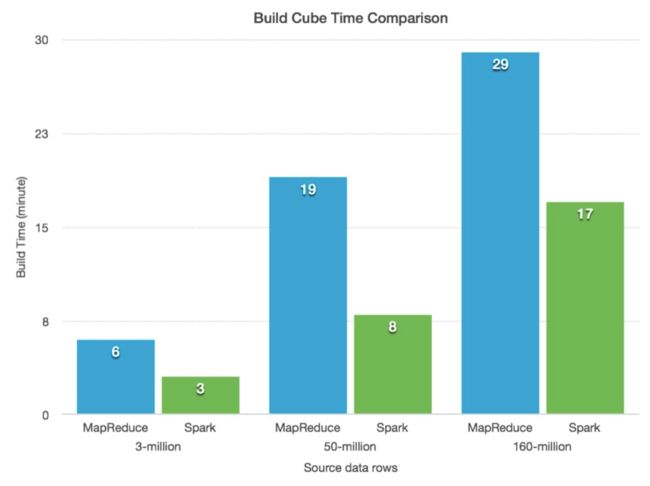
使用 Spark 逐层构建算法:
- 核心概念和逻辑与MR相同
- 区别在于将每层的立方体抽象为 RDD,然后使用父 RDD 生成子 RDD。 尽可能在内存中缓存父 RDD 以获得更好的性能


使用 Spark相比于 MR 的耗时比较如下:
构建 Cube 的 Spark 任务如下:
Running org.apache.kylin.engine.spark.SparkCubingByLayer
-hiveTable default.kylin_intermediate_test_cube_44e5fcfe_e62f_375c_1e91_1d75d2fc6de3
-output hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/
-input hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/kylin_intermediate_test_cube_44e5fcfe_e62f_375c_1e91_1d75d2fc6de3 -segmentId 44e5fcfe-e62f-375c-1e91-1d75d2fc6de3
-metaUrl kylin_metadata@hdfs,path=hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/metadata
-cubename test_cube
如下为生成的各级维度的 Cuboid 文件:
$ hdfs dfs -ls hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/
drwxr-xr-x - root supergroup 0 2019-04-17 08:26 hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/level_1_cuboid
drwxr-xr-x - root supergroup 0 2019-04-17 08:26 hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/level_2_cuboid
drwxr-xr-x - root supergroup 0 2019-04-17 08:26 hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/level_3_cuboid
drwxr-xr-x - root supergroup 0 2019-04-17 08:26 hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/level_4_cuboid
drwxr-xr-x - root supergroup 0 2019-04-17 08:26 hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/level_5_cuboid
drwxr-xr-x - root supergroup 0 2019-04-17 08:26 hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/level_base_cuboid
Step4:将 Cuboid 数据转化为 HFile 文件(By Spark)
一个转换任务的例子如下;
Running org.apache.kylin.storage.hbase.steps.SparkCubeHFile
-partitions hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/rowkey_stats/part-r-00000_hfile
-counterOutput hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/counter
-cubename test_cube -output hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/hfile
-input hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/cuboid/
-segmentId 44e5fcfe-e62f-375c-1e91-1d75d2fc6de3
-metaUrl kylin_metadata@hdfs,path=hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/metadata
-hbaseConfPath hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/hbase-conf.xml
Step5: 将 HFile 文件 load 到 HBase 表中
Version:1.0 StartHTML:0000000100 EndHTML:0000000444 StartFragment:0000000100 EndFragment:0000000444
-input hdfs://localhost:9000/kylin/kylin_metadata/kylin-f7a8f547-4312-2393-d8ca-9dfd1b6a9bb9/test_cube/hfile -htablename KYLIN_ABHS9OKHZA -cubename test_cube
如下是一个 Cuboid 在 HBase 表中的形式

3.2、增量构建 VS 全量构建
全量构建和增量构建对比如下

- 对于小数据量的Cube,或者经常需要全表更新的Cube,使用全量构建需要更少的运维精力,以少量的重复计算降低生产环境中的维护复杂度
- 对于大数据量的Cube,例如,对于一个包含两年历史数据的 Cube,如果需要每天更新,那么每天为了新数据而去重复计算过去两年的数据就会变得非常浪费,在这种情况下需要考虑使用增量构建
3.3、增量构建
Segment在增量构建中,将 Cube 划分为多个 Segment,每个 Segment 用起始时间和结束时间标志。Segment 代表一段时间内源数据的预计算结果。一个 Segment 的起始时间等于它之前那个 Segment 的结束时间(前闭后开),同理,它的结束时间等于它后面那个 Segment 的起始时间。同一个 Cube 下不同的 Segment 的结构定义、构建过程、优化方法、存储方式等完全相同。
前提并非所有的 Cube 都适用于增量构建,Cube 的定义必须包含一个时间维度,用来分割不同的 Segment,该维度称为分割时间列。同一个 Model 下不同 Cube 的分割时间列应该是相同的,因此在 Kylin 中将分割时间列的定义放到了 Model 中。
Cube 的配置Cube 每次增量构建都会生成一个 Segment,随着时间的推移,当前 Cube 会存在大量的 Segments,这时候会产生以下两个问题:
- 执行查询时查询引擎要聚合多个 Segments 的结果才能返回正确的查询结果,聚合的 Segments 越多,查询的性能越差
- 每个 Segments 都对应 Hbase 的一张表,过多的 Segments 会在底层的存储系统产生大量的文件,会给存储系统 HDFS NameNode 带来压力
我们要在 Cube 层面进行以下设置来让 Kylin 按照一定的规则自动合并 Segments:
-
Partition Start Date:指 Cube 默认的第一个 Segment 的起始时间。同一个 Model 下不同的 Cube 可以指定不同的起始时间 -
Auto Merge Thresholds:用于指定 Segment 自动合并的阈值,将在后文详述 -
Retention Threshold:保留最近设置阈值的 cube segments 个数,默认是0,它会保留所有历史构建的segments
触发增量构建在进行增量构建时,将增量部分的起始时间和结束时间作为增量构建的一部分提交给 Kylin 的任务引擎,任务引擎会根据起始时间和结束时间从 Hive 中抽取相应时间的数据,并对这部分数据做预计算处理,然后将预计算的结果封装为一个新的 Segment,并将相应的信息保存到元数据和存储引擎中。
当我们为一个已经有 Segment 的 Cube 触发增量构建的时候,起始时间的值已经被确定,不能被修改。如果 Cube 中不存在任何的 Segment,那么 Start Date 的值会被设置为 Partition Start Date (在 Model 中设定)。
仅当 Cube 中不存在任何 Segment,或者不存在任何未完成的构建任务时,Kylin 才接受 Cube 上新的构建任务。未完成的构建任务不仅包含正在运行中的构建任务,还包括已经出错并处于 ERROR 的任务。
Kylin 提供 Rest API 以帮助自动化地触发增量构建:Build cube
管理 Cube 碎片(Segments)Auto Merge Thresholds 允许用户设置几个层级的时间阈值,层级约靠后,时间阈值就越大。举例来说,[7days, 28days] 这个层级,每当 Cube 中有新的 Segment 生成时,就会触发一次自动合并的尝试:
- 首先查看是否能将连续的若干个 Segments 合并成为一个超过 28 天的大 Segment。在挑选连续 Segments 的过程中:
- 如果遇到已经有个别 Segment 的时间长度已经超过 28 天,那么系统会跳过该 Segment,从它之后的所有 Segment 中挑选连续的积累超过 28 天的 Segment
- 如果满足条件的连续 Segments 还不能够积累超过 28 天,则系统会使用下一个层级的时间阈值重复寻找过程
四、查询
4.1、使用标准 SQL 查询
Kylin 的查询语言的标准 SQL 的 SELECT 语句(仅支持 SELECT,其他 DDL、DML 均不支持),这是为了获得与大多数 BI 系统和工具无缝集成,比如下面是一个典型的查询 SQL:
SELECT DIM1, DIM2, ..., MEASURE1, MEASURE2 ... FROM FACT_TABLE
INNER JOIN LOOKUP_1 ON FACT_TABLE.FK1 = LOOKUP_1.PK
INNER JOIN LOOKUP_2 ON FACT_TABLE.FK2 = LOOKUP_2.PK
WHERE FACT_TABLE.DIMN = '' AND ...
GROUP BY DIM1, DIM2 ...
需要了解的是 ,只有当查询的模式跟 Cube 定义相匹配的时候,Kylin 才能够使用 Cube 的数据来完成查询,匹配的条件如下:
- Group By 的列和 Where 条件里的列,必须是在 Dimension 中定义的列
- SQL 中的度量,应该是 Cube 中定义的度量的或是其子集
在一个项目下,如果有多个基于同一模型的 Cube,而且它们都满足对表、维度和度量的要求;那么,Kylin 会挑选一个 “最优的” 的 Cube 进行查询;这是一种基于成本(cost)的选择,成本计算会考虑:
- Cube 的维度数
- 度量
- 数据模型的复杂度
4.2、查询接入方式
4.2.1、RESTful API
Kylin 提供的主要的 RESTful APIs 如下:
- Query
- Authentication
- Query
- List queryable tables
- CUBE
- List cubes
- Get cube
- Get cube descriptor (dimension, measure info, etc)
- Get data model (fact and lookup table info)
- Build cube
- Enable cube
- Disable cube
- Purge cube
- Delete segment
- JOB
- Resume job
- Pause job
- Drop job
- Discard job
- Get job status
- Get job step output
- Get job list
- Metadata
- Get Hive Table
- Get Hive Tables
- Load Hive Tables
- Cache
- Wipe cache
- Streaming
- Initiate cube start position
- Build stream cube
- Check segment holes
- Fill segment holes
4.2.2、JDBC及其他连接方式
JDBC 连接 url 格式:
jdbc:kylin://:/
- 如果“ssl”为true,“port”应该是Kylin server的HTTPS端口。
- 如果“port”未被指定,driver会使用默认的端口:HTTP 80,HTTPS 443。
- 必须指定“kylin_project_name”并且用户需要确保它在Kylin server上存在。
使用Statement查询:
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://localhost:7070/kylin_project_name", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from test_table");
while (resultSet.next()) {
assertEquals("foo", resultSet.getString(1));
assertEquals("bar", resultSet.getString(2));
assertEquals("tool", resultSet.getString(3));
}
另外,Kylin 也支持通过 ODBC 及其他 BI 工具(如Tableau、Superset等)进行连接查询,这最终都是基于 RESTful API 进行查询的。
五、参考
- 《Apache Kylin 权威指南》
- http://kylin.apache.org/cn/docs/
- https://blog.csdn.net/bbbeoy/article/details/79073725
- https://www.slidestalk.com/x/241/kyligence_open_class
- http://bigdata-star.com/archives/2023
- https://www.jianshu.com/p/befc0030afdc