这篇文章只做研究学习,如果拿这套代码做出的任何事情都与作者无关
这篇文章只做研究学习,如果拿这套代码做出的任何事情都与作者无关
这篇文章只做研究学习,如果拿这套代码做出的任何事情都与作者无关
首先我们打开页面查找,但是发现字体是经过加密的
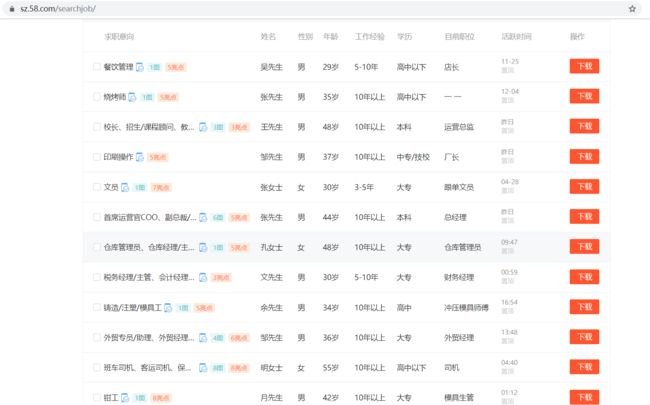
目标网站
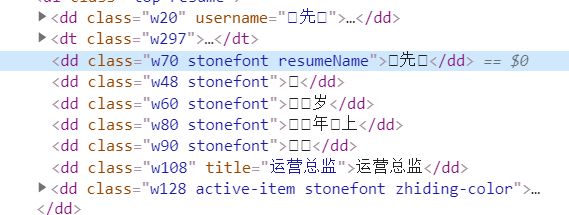
加密字体
然后我们进入网页源代码找woff,tff等文件下载路径
woff路径
但是我们在这里看到的是base64位的数据
我们通过代码把他们保存成woff文件,然后通过TTFont把woff文件格式化成xml文件
# 文件下载处理
url = "https://sz.58.com/searchjob/"
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36',
}
response = requests.get(url, headers=header)
html = response.text
result = re.search(r"base64,(.*?)\)", content, flags=re.S).group(1)
b = base64.b64decode(result)
# tf = TTFont(BytesIO(b))
with open("ztku01.woff", "wb")as f:
f.write(b)
fonts = TTFont("ztku01.woff")
fonts.saveXML("ztku01.xml")
这里我们得到获取两次,得到两个字库文件

字库文件1
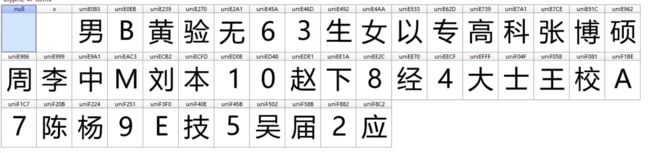
字库文件2
然后我们查看两个字库的xml文件这里我们直接说坐标的事情吧,不墨迹了,我们拿两个库里的相同的字来看看坐标问题
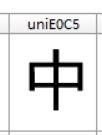
字库1文件中
就拿中来做测试,这是字库1里的中,编码是"unie0C5"
它的坐标在xml文件中是
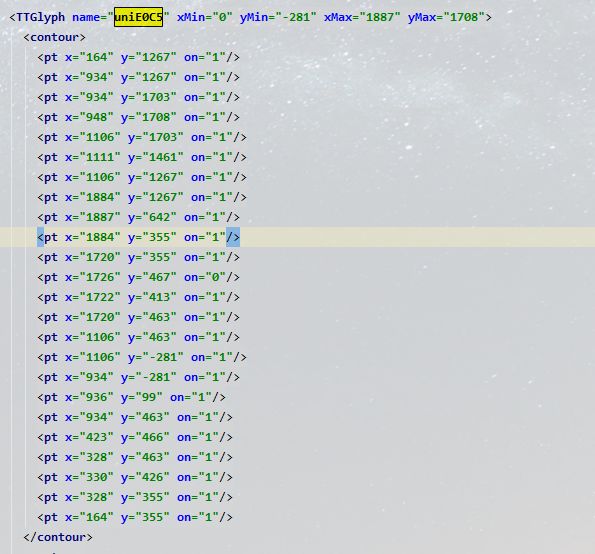
字库一xml中
这里我们可以通过用坐标二减去坐标一的值(934-164,1267-1267)=(770,0)那么,在字库1里,中的坐标是(770,0)
我们看看字库2里的中和它的坐标
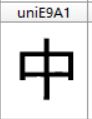
字库2中
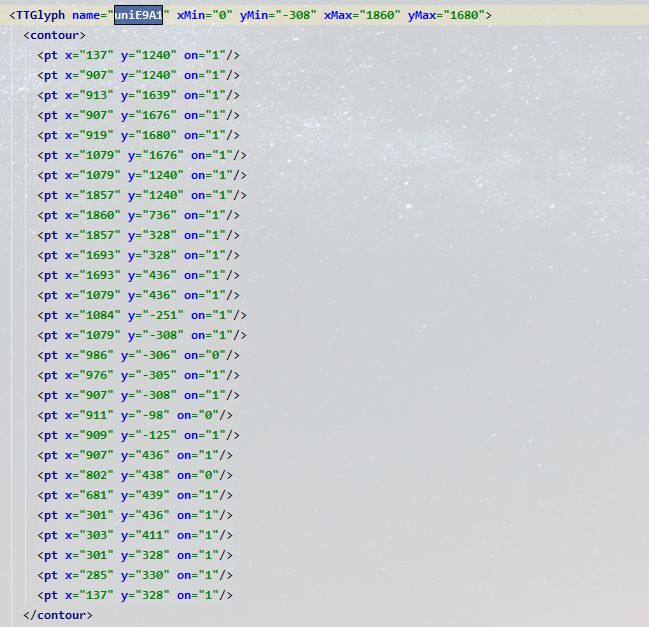
字库2xml
这里我们可以通过用坐标二减去坐标一的值(907-137,1240-1240)=(770,0)那么,在字库2里,中的坐标是(770,0)
那么,我们就可以认为这是他们的通用方法了,可以多拿几组数据来测试,我测试都是一样的,所以,我们定义了字库和坐标的对应关系
{(0, 1549): 'B', (1588, 0): '男', (868, 0): '王', (825, 367): '大', (265, -118): '专', (0, 1026): 'M',
(-110, -150): '女', (1460, 0): '吴', (230, 390): '硕', (156, 262): '赵', (660, 0): '黄', (924, 0): '李',
(0, 1325): '1', (0, 134): '8', (0, 144): '经', (0, 125): '2', (1944, 0): '下', (-52, -52): '本', (582, 0): '届',
(0, -227): '5', (146, 78): '应', (228, 306): '科',(-244, -426): '7', (770, 0): '中', (928, 0): '生',(-121, 62): '6',
(-833, 0): 'E', (299, 0): '陈', (159, -123): '3', (164, 0): '以', (-764, 0): '杨',(-221, 0): 'A', (238, 0): '张',
(0, -1023): '4', (784, 0): '无', (0, 410): '0', (128, -74): '9',(-46, -550): '验', (0, 110): '博', (0, 132): '技',
(746, 0): '士', (210, 358): '校', (1298, 0): '高',(-74, -366): '刘', (0, -508): '周'}
下面是整体结合起来的代码
import requests
import re
import base64
from lxml import etree
from fontTools.ttLib import TTFont
from io import BytesIO
data_map = {(0, 1549): 'B', (1588, 0): '男', (868, 0): '王', (825, 367): '大', (265, -118): '专', (0, 1026): 'M',
(-110, -150): '女', (1460, 0): '吴', (230, 390): '硕', (156, 262): '赵', (660, 0): '黄', (924, 0): '李',
(0, 1325): '1', (0, 134): '8', (0, 144): '经', (0, 125): '2', (1944, 0): '下', (-52, -52): '本', (582, 0): '届',
(0, -227): '5', (146, 78): '应', (228, 306): '科', (-244, -426): '7', (770, 0): '中', (928, 0): '生',
(-121, 62): '6', (-833, 0): 'E', (299, 0): '陈', (159, -123): '3', (164, 0): '以', (-764, 0): '杨',
(-221, 0): 'A', (238, 0): '张', (0, -1023): '4', (784, 0): '无', (0, 410): '0', (128, -74): '9',
(-46, -550): '验', (0, 110): '博', (0, 132): '技', (746, 0): '士', (210, 358): '校', (1298, 0): '高',
(-74, -366): '刘', (0, -508): '周'}
def get_font_map(content):
"""
根据相应内容 得到当前的字体映射关系
:param content:
:return:
"""
font_map = {}
result = re.search(r"base64,(.*?)\)", content, flags=re.S).group(1)
b = base64.b64decode(result)
tf = TTFont(BytesIO(b))
# with open("ztku01.woff", "wb")as f:
# f.write(b)
# fonts = TTFont("ztku01.woff")
# fonts.saveXML("ztku01.xml")
for index, i in enumerate(tf.getGlyphNames()[1:-1]):
temp = tf["glyf"][i].coordinates
x1, y1 = temp[0]
x2, y2 = temp[1]
new = (x2 - x1, y2 - y1)
key = i.replace("uni", "&#x").lower()
# key = key.encode('utf-8').decode('unicode_escape')
font_map[key] = data_map[new]
# print(font_map)
return font_map
def parse_zt():
"""
请求网页获取字体
:return:
"""
url = "https://sz.58.com/searchjob/"
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36',
}
response = requests.get(url, headers=header)
html = response.text
font_map = get_font_map(html)
for i in font_map:
print(i+";")
html = html.replace(i + ";", font_map[i])
data = etree.HTML(html)
personal_information = data.xpath('//div[@id="infolist"]/ul/li//dl[@class="infocardMessage clearfix"]')
for info in personal_information:
# 姓名
name = info.xpath('./dd//span[@class="infocardName fl stonefont resumeName"]/text()')[0]
# 性别
gender = info.xpath('./dd//div[@ class="infocardBasic fl"]/div/em[1]/text()')[0]
# 年龄
age = info.xpath('./dd//div[@ class="infocardBasic fl"]/div/em[2]/text()')[0]
# 工作经验
work_experience = info.xpath('./dd//div[@ class="infocardBasic fl"]/div/em[3]/text()')[0]
# 学历
education = info.xpath('./dd//div[@ class="infocardBasic fl"]/div/em[4]/text()')[0]
print(name, gender, age, work_experience, education)
if __name__ == "__main__":
parse_zt()