这两个算法都是集成学习了分类回归树模型,先讨论是怎么集成的。
集成的方法是 Gradient Boosting
比如我要拟合一个数据如下: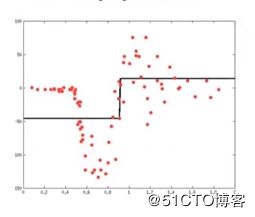
第一次建了一个模型如上图中的折线,效果不是很理想,然后要新建一个模型来综合一下结果,那么第二个模型如何建,我们将实际目标值和我们第一个模型的预测的差值 作为第二次模型的目标值如下图再建一个模型:
然后不断地新建新的模型,过程如下:
最后就能集成这些模型不断提升预测的精度。
步骤如下:
损失函数:![]()
最小化目标:
对每一个基学习器求偏导:
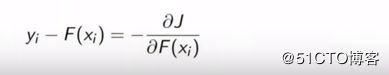
这两个算法的基学习器都是分类回归树,也就是先分类然后回归的树,这里采用决策树来做特征分类。
建立决策树要考虑主要的问题是,我们如何找到合适的特征和合适的切分点来做数据集划分。判断标准是什么。
可以采用遍历的方式,遍历每一个特征的每一个数据,注意为了能够快速划分数据集,在分某一个特征的时候,就根据这个特征进行排序,这样切割数据集的时候就不要每一个数据重新进行和切分点的阈值进行比较。
划分依据是分类之后的数据集的目标值的方差和要下降的最多(对于目标值是连续值)。
假设下面代码中最后一列为目标值:
def err_cnt(dataSet):
'''回归树的划分指标
input: dataSet(list):训练数据
output: m*s^2(float):总方差
'''
data = np.mat(dataSet)
return np.var(data[:, -1]) * np.shape(data)[0]这样就可以建立每一颗树。
但是考虑到遍历每一个特征,还要遍历每一个特征的每一个值会效率很低,所以lightgbm相对xgboost有个改进,就是对于某一个特征的值得分布建立一个直方图,然后根据直方图的切分点来对数据集进行分割。
对于这个地方有个重要的参数:
max_bin,也就是我这里每一个特征画直方图最大的柱子的个数有多少个,如果画的越多说明分得越细,所以在调整这个参数的时候要自己先对特征的分布有个把握,我的特征是否需要这么多个bin来绘制直方图。直方图有个好处,子节点的兄弟节点的直方图只要用父节点减去子节点就可以获得该兄弟节点的直方图。
建立了每一个树之后要考虑过拟合的问题,例如假如每一个叶子节点上面只有一个数据,当然就能完美拟合训练数据集,但是可能泛化能力就很差,也就是我的树建的很深,这里有两个参数:
min_data_in_leaf
表示一个叶子节点上面最少有多少个数据,要根据训练数据集的目标值的分布来看,有可能有的目标值就真的有一个偏离非常远(例如平安数据大赛中有的目标赔率非常高,可能是发生了重大事故),你实在要拟合这个数据,只能把这个参数调成1
min_sum_hessian_in_leaf
这个参数表示一个叶子上的数据的权重的和,如果调的很小,也就是这个叶子上面的数据越少,也有过拟合的风险,调的越大说明叶子上面数据越多,要根据数据集的目标值的分布来确定
n_estimators 表示有多少颗树
num_leaves表示有多少叶子,请注意,lightgbm和xgboost建立一棵树的时候有不同(他们并不是完整的二叉树,也就是num_leaves可以小于2^max_depth)
xgboost建树的过程如下(level-wise tree):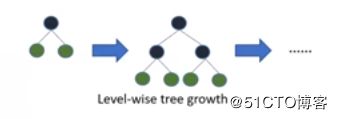
lightgbm建树的过程如下(leaf-wise tree):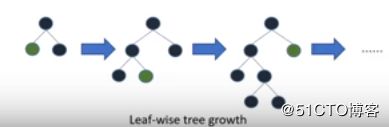
优先生长残差比较大的节点。上图中在第二步后会选择生长残差较大的下一层而不是补齐右子树的子节点。
lightgbm建立新的模型的时候对于每一个数据并不是一视同仁的,他会做一个采样,选择梯度(残差)较大的数据作为新的模型的输入。
对于调参有个博客介绍的很好:https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
最后本文放一段代码 演示如何建立一颗分类回归树:
import numpy as np
import pickle
class node:
'''树的节点的类
'''
def __init__(self, fea=-1, value=None, results=None, right=None, left=None):
self.fea = fea # 用于切分数据集的属性的列索引值
self.value = value # 设置划分的值
self.results = results # 存储叶节点的值
self.right = right # 右子树
self.left = left # 左子树
def load_data(data_file):
'''导入训练数据
input: data_file(string):保存训练数据的文件
output: data(list):训练数据
'''
data = []
f = open(data_file)
for line in f.readlines():
sample = []
lines = line.strip().split("\t")
for x in lines:
sample.append(float(x)) # 转换成float格式
data.append(sample)
f.close()
return data
def split_tree(data, fea, value):
'''根据特征fea中的值value将数据集data划分成左右子树
input: data(list):训练样本
fea(float):需要划分的特征index
value(float):指定的划分的值
output: (set_1, set_2)(tuple):左右子树的聚合
'''
set_1 = [] # 右子树的集合
set_2 = [] # 左子树的集合
for x in data:
if x[fea] >= value:
set_1.append(x)
else:
set_2.append(x)
return (set_1, set_2)
def leaf(dataSet):
'''计算叶节点的值
input: dataSet(list):训练样本
output: np.mean(data[:, -1])(float):均值
'''
data = np.mat(dataSet)
return np.mean(data[:, -1])
def err_cnt(dataSet):
'''回归树的划分指标
input: dataSet(list):训练数据
output: m*s^2(float):总方差
'''
data = np.mat(dataSet)
return np.var(data[:, -1]) * np.shape(data)[0]
def build_tree(data, min_sample, min_err):
'''构建树
input: data(list):训练样本
min_sample(int):叶子节点中最少的样本数
min_err(float):最小的error
output: node:树的根结点
'''
# 构建决策树,函数返回该决策树的根节点
if len(data) <= min_sample:
return node(results=leaf(data))
# 1、初始化
best_err = err_cnt(data)
bestCriteria = None # 存储最佳切分属性以及最佳切分点
bestSets = None # 存储切分后的两个数据集
# 2、开始构建CART回归树
feature_num = len(data[0]) - 1
for fea in range(0, feature_num):
feature_values = {}
for sample in data:
feature_values[sample[fea]] = 1
for value in feature_values.keys():
# 2.1、尝试划分
(set_1, set_2) = split_tree(data, fea, value)
if len(set_1) < 2 or len(set_2) < 2:
continue
# 2.2、计算划分后的error值
now_err = err_cnt(set_1) + err_cnt(set_2)
# 2.3、更新最优划分
if now_err < best_err and len(set_1) > 0 and len(set_2) > 0:
best_err = now_err
bestCriteria = (fea, value)
bestSets = (set_1, set_2)
# 3、判断划分是否结束
if best_err > min_err:
right = build_tree(bestSets[0], min_sample, min_err)
left = build_tree(bestSets[1], min_sample, min_err)
return node(fea=bestCriteria[0], value=bestCriteria[1], \
right=right, left=left)
else:
return node(results=leaf(data)) # 返回当前的类别标签作为最终的类别标签
def predict(sample, tree):
'''对每一个样本sample进行预测
input: sample(list):样本
tree:训练好的CART回归树模型
output: results(float):预测值
'''
# 1、只是树根
if tree.results != None:
return tree.results
else:
# 2、有左右子树
val_sample = sample[tree.fea] # fea处的值
branch = None
# 2.1、选择右子树
if val_sample >= tree.value:
branch = tree.right
# 2.2、选择左子树
else:
branch = tree.left
return predict(sample, branch)
def cal_error(data, tree):
''' 评估CART回归树模型
input: data(list):
tree:训练好的CART回归树模型
output: err/m(float):均方误差
'''
m = len(data) # 样本的个数
n = len(data[0]) - 1 # 样本中特征的个数
err = 0.0
for i in range(m):
tmp = []
for j in range(n):
tmp.append(data[i][j])
pre = predict(tmp, tree) # 对样本计算其预测值
# 计算残差
err += (data[i][-1] - pre) * (data[i][-1] - pre)
return err / m
def save_model(regression_tree, result_file):
'''将训练好的CART回归树模型保存到本地
input: regression_tree:回归树模型
result_file(string):文件名
'''
with open(result_file, 'wb') as f:
pickle.dump(regression_tree, f)
if __name__ == "__main__":
# 1、导入训练数据
print ("----------- 1、load data -------------")
data = load_data("sine.txt")
# 2、构建CART树
print ("----------- 2、build CART ------------")
regression_tree = build_tree(data, 30, 0.3)
# 3、评估CART树
print ("----------- 3、cal err -------------")
err = cal_error(data, regression_tree)
print ("\t--------- err : ", err)
# 4、保存最终的CART模型
print ("----------- 4、save result -----------")
save_model(regression_tree, "regression_tree")数据格式如下:
数据中间用tab键隔开 前面的列为特征,最后一列为目标值。