1.const定义的值可以改吗?
部分能改,部分不能改,congst定义的基本类型是不可以改变的,但是定义的对象是可以通过修改对象属性等方法来改变。
>>> const a = 1
>>> a
<<< 1
>>> a = 2
<<< VM1750:1 Uncaught TypeError: Assignment to constant variable.
at :1:3
(anonymous) @ VM1750:1
>>> const b = {}
>>> b
<<< {}
>>> b.name = 1
>>> b
<<< {name: 1}
>>> b = {}
<<< VM1785:1 Uncaught TypeError: Assignment to constant variable.
at :1:4
定义一个const对象的时候,我们说的常量其实是指针,就是const对象对应的堆内存指向是不变的,但是堆内存中的数据本身的大小或者属性是可变的。而对于const定义的基础变量而言,这个值就相当于const对象的指针,是不可变。
2.js基本数据类型和对象数据类型的赋值区别?
基本数据类型,如boolean, number, string, undefined, null, 以及对象变量的指针(对象的引用和指针),然后对象数据类型,如obj,array。基本数据类型是基于值的,对象类型是基于引用的。如果我们赋值一个a = 'abcd',那么在栈里就是:(可以理解为值的复制)
+------------------+
| a | ’abcd‘ |
+------------------+
| b | ’abcd‘ |
+------------------+
如果是对象的赋值,就是引用,对象引用就是指针,b = a,a是object,则是b指向堆里a的地址:
+------+ +------------------+
| a | --------> | object |
+------+ +-> +------------------+
|
+------+ |
| a | ------+
+------+
所以const、let定义的变量不能二次定义的流程也就比较容易猜出来了,每次使用const或者let去初始化一个变量的时候,会首先遍历当前的内存栈,看看有没有重名变量,有的话就返回错误。
但是,使用new关键字初始化的之后是不存储在栈内存中的。new根据构造函数生成新实例,这时候生成的是对象,不是基本类型。比如,我们new一个String,出来的是对象,而直接字面量赋值和工厂模式出来的都是字符串:
var a = new String('123')
var b = String('123')
var c = '123'
console.log(a==b, a===b, b==c, b===c, a==c, a===c)
>>> true false true true true false
console.log(typeof a)
>>> 'object'
如果a,b是存储在栈内存中的话,两者应该是明显相等的,就像null === null是true一样,但结果两者并不相等,说明两者都是存储在堆内存中的,指针指向不一致。对象的比较是比较hash值,也就是比较在堆内存中的指针指向的地址。
3.js中深拷贝和浅拷贝区别?
深拷贝和浅拷贝是只针对Object和Array这样的引用数据类型的,就是在堆里有内容的,栈里有地址指针信息的
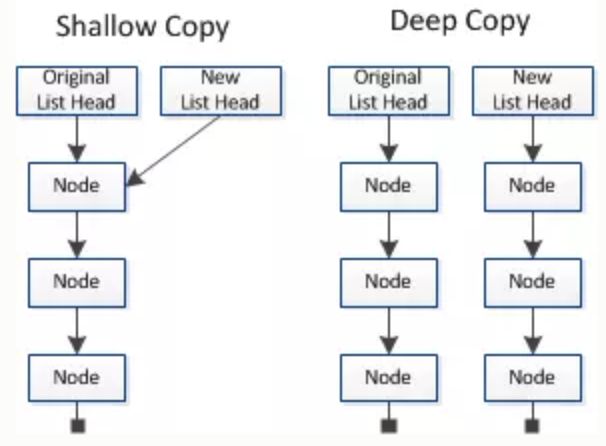
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。但深拷贝会另外创造一个一模一样的对象,新对象跟原来对象不共享内存,所以修改新对象不会改到原对象。
赋值,当我们吧一个对象赋值给另一个新的变量时候,赋的其实是该对象在栈中的地址,不是堆中的数据。也就是两个对象指向的是同一个存储空间,无论哪个对象发生改变,其实都是改变的存储空间的内容,因此是联动的。
浅拷贝,是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。即默认拷贝构造函数只是对对象进行浅拷贝复制(逐个成员依次拷贝),即只复制对象空间而不复制资源。
ps:赋值是一个引用的过程,但是拷贝是一个复制的过程,所以赋值是全部引用,所有变量和对象属性都是联动的,但是浅拷贝是复制了部分的,复制了基本数据类型,所以基本数据类型不是联动的,但是对象属性是引用的,对象属性是联动的。深拷贝则互不干涉,都不联动。
4.js中深拷贝浅拷贝的实现方法?
1. Object.assign()浅拷贝
Object.assign() 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。但是 Object.assign()进行的是浅拷贝,拷贝的是对象的属性的引用,而不是对象本身。当object只有一层的时候,是深拷贝。
var obj = { a: {a: "kobe", b: 39} };
var initalObj = Object.assign({}, obj);
initalObj.a.a = "wade";
console.log(obj.a.a); //wade
let obj = {
username: 'kobe'
};
let obj2 = Object.assign({},obj);
obj2.username = 'wade';
console.log(obj);//{username: "kobe"}
2. Array.prototype.concat()浅拷贝
let arr = [1, 3, {
username: 'kobe'
}];
let arr2=arr.concat();
arr2[2].username = 'wade';
console.log(arr);
3. Array.prototype.slice()浅拷贝
let arr = [1, 3, {
username: ' kobe'
}];
let arr3 = arr.slice();
arr3[2].username = 'wade'
console.log(arr);
1. JSON.parse(JSON.stringify())深拷贝
原理: 用JSON.stringify将对象转成JSON字符串,再用JSON.parse()把字符串解析成对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝。
这种方法虽然可以实现数组或对象深拷贝,但不能处理函数
let arr = [1, 3, {
username: ' kobe'
}];
let arr4 = JSON.parse(JSON.stringify(arr));
arr4[2].username = 'duncan';
console.log(arr, arr4)
2. 手写递归方法 深拷贝
//定义检测数据类型的功能函数
function checkedType(target) {
return Object.prototype.toString.call(target).slice(8, -1)
}
//实现深度克隆---对象/数组
function clone(target) {
//判断拷贝的数据类型
//初始化变量result 成为最终克隆的数据
let result, targetType = checkedType(target)
if (targetType === 'Object') {
result = {}
} else if (targetType === 'Array') {
result = []
} else {
return target
}
//遍历目标数据
for (let i in target) {
//获取遍历数据结构的每一项值。
let value = target[i]
//判断目标结构里的每一值是否存在对象/数组
if (checkedType(value) === 'Object' ||
checkedType(value) === 'Array') { //对象/数组里嵌套了对象/数组
//继续遍历获取到value值
result[i] = clone(value)
} else { //获取到value值是基本的数据类型或者是函数。
result[i] = value;
}
}
return result
}
3. 函数库lodash 深拷贝
var _ = require('lodash');
var obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
var obj2 = _.cloneDeep(obj1);
console.log(obj1.b.f === obj2.b.f);
// false
5.js中的堆内存和栈内存?
js中对变量的存储只要有2中位置,堆内存和栈内存
栈内存主要用于存储各种基本类型的变量,包括Boolean、Number、String、Undefined、Null以及对象变量的指针,这时候栈内存给人的感觉就像一个线性排列的空间,每个小单元大小基本相等,栈内存中的变量一般都是已知大小或者有范围上限的,算作一种简单存储。null存在栈中虽然是object类型。
堆内存主要负责像对象Object这种变量类型的存储,堆内存存储的对象类型数据对于大小这方面,一般都是未知的。
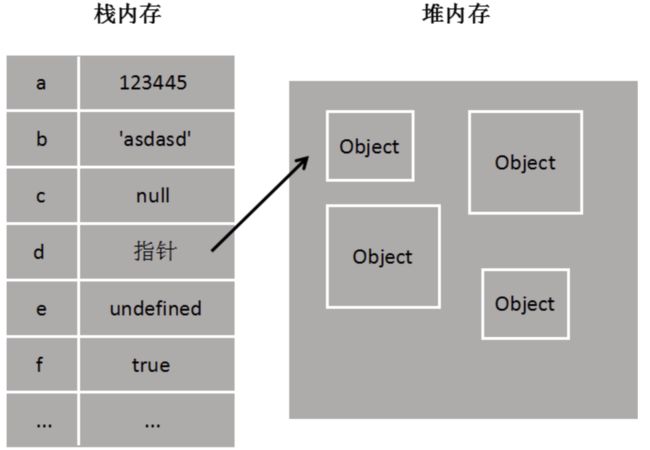
一般来说栈内存线性有序存储,容量小,系统分配效率高。而堆内存首先要在堆内存新分配存储区域,之后又要把指针存储到栈内存中,效率相对就要低一些了。
数据存取顺序:
栈是一种特殊的列表,栈内的元素只能通过列表的一端访问,这一端称为栈顶。栈被称为是一种后入先出(LIFO,last-in-first-out)的数据结构。由于栈具有后入先出的特点,所以任何不在栈顶的元素都无法访问。
为了得到栈底的元素,必须先拿掉上面的元素。
堆是一种经过排序的树形数据结构,每个结点都有一个值。
通常我们所说的堆的数据结构,是指二叉堆。
堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。由于堆的这个特性,常用来实现优先队列,堆的存取是随意,这就如同我们在图书馆的书架上取书,虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书,我们只需要关心书的名字,即引用。
垃圾回收方面,栈内存变量基本上用完就回收了,而推内存中的变量因为存在很多不确定的引用,只有当所有调用的变量全部销毁之后才能回收。
总结起来两个都是内存,栈小,堆大,栈是存放引用,堆存放实际内容。类似字典,引用的索引就是栈,可以快速找到哪一页,但是存放那一页的实际内容就是堆。一般了解堆和栈,需要注意他存储的时候到底是存在堆还是栈里,引用的时候引用的是哪个,回收机制怎样。