前言:
终于开始老老实实地开始写博客啦,这是我整理的第一篇博客,在此之前要不就是忘记的内容临时需要用到的时候急急忙忙地在网上查阅,费时费力,而且就因为如此很多重复的错误都还要在后续时间继续查,越来越令我有种自己整理文章的欲望,要不就是在学习新东西的时候直接抄在一个小抄本上面,想当初学习javase,servlet,jsp,html,css,js,ajax,jquery的时候所有笔记都是抄在一个笔记本上面,而且上面的笔记很乱也没有整理过,所有干脆以后写博客把,可是为什么我要在第一篇选择写关于mysql的文章呢,因为我是一个java后台,才入门java一年多的时间,数据库的操作对于后台的工作来说,我觉得是一个非常频繁而且是一个基本的操作,老实说后台就是要和数据库打交道的啦,接下来会有好几个关于mysql基本操作的文章整理发表,方便自己平时工作的查阅还有复习,好啦,废话不多说,开始.
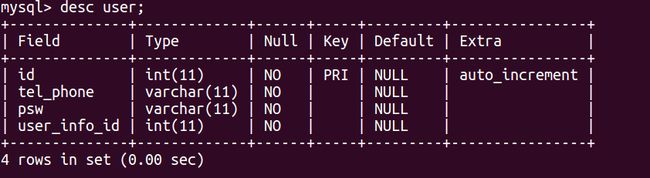
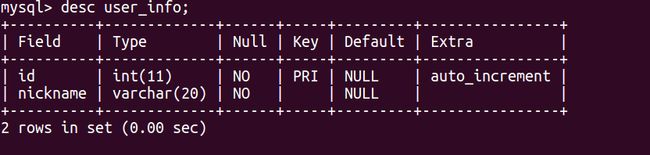
假如现在我们有一个user表,还有一个user_info表,在user表当中有一个user_info_id的字段作为查询user_info表的外键,数据库名,表名都建议用小写,如果有两个单词的话就用下划线分割(字段名也如此),我们现在来进行查询,以下两个图是这两个表的结构图:
先来看看select的全部语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr, ...
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name']
[FROM table_references
[WHERE where_definition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_definition]
[ORDER BY {col_name | expr | position}
[ASC | DESC] , ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[FOR UPDATE | LOCK IN SHARE MODE]]
1 . select *查询
select * from user,user_info where user.user_info_id = user_info.id
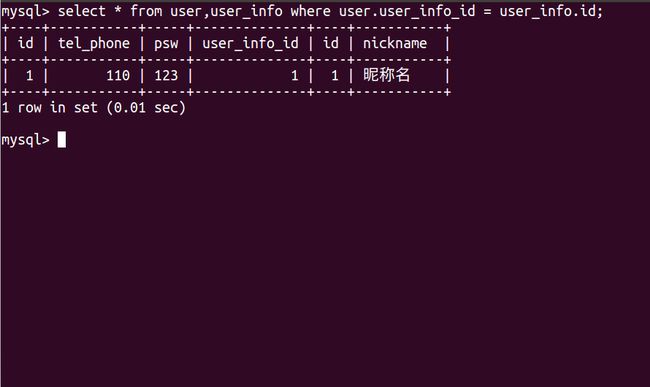
大家应该可以注意到select后面跟着一个通配符*,它的意思是查询跟着from后面的表当中符合where后面条件的所有的列,然后就会查询到如上图的结果
2 . select查询部分列
select user.id,nickname from user,user_info where user.user_info_id = user_info.id

大家可以注意到查询列的时候写的是user.id,因为对于user和user_info表,,都有一个共同的字段id,那么如果直接写id的话,mysql不知道你到底要查询哪一个表的id,所以需要显式表示
3 . locate函数
locate(subStr,str)
返回subStr在str当中的第一个出现的位置,如果不存在则值为0
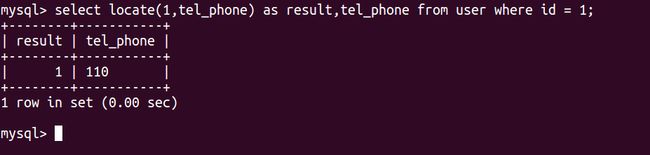
要查询的字段后面as加上别名,就会为这个结果赋上别名,如上图result字段
4 . count(*),count(1) 和count(字段)
count(1)这里面的1很容易让人以为它的意思是统计第一个字段的数量,其实不然,这里面的1是一个常量可以想象成表中有一个名叫做1的字段,对于每一行它的值都是相同的(可以这样想象),count()是根据全部列去计算行数,无论这个行当中的值无论是不是为NULL都会计算进去,就是不会去考虑NULL的情况,它与count()的不同是count(*)还会去全表扫描的过程,统计出来的结果是一样的;count(字段)的话,当某行中此字段值为NULL时,也不会计算进去,当中的效率问题在此文不做研究.

5 . distinct去除重复行
select distinct * from user
此语句的意思是查询user表,而且去除重复行
另外其他语句或者函数都可以和distinct配合使用,例如count(distinct 字段),去除重复行统计行数,这里非常值得注意的是 ** count(distinct *)是不被允许的 **
到了这里,可以更进一步清晰地讲解count(1)的含义了,其中的含义我在上面已经说了,那么现在可以用distinct进行验证一下,现在有一张null_test表,其中有两行,其值都为NULL,看截图如下:
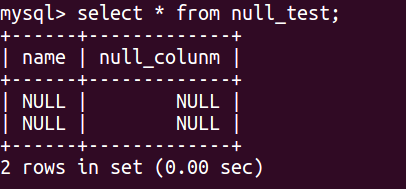
那么现在使用select count(1) from null_test,结果如下:
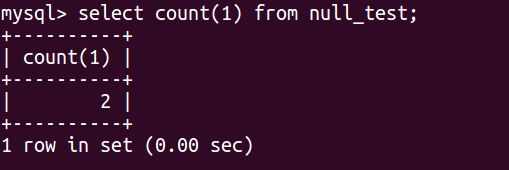
现在使用 select count(distinct 1) from null_test
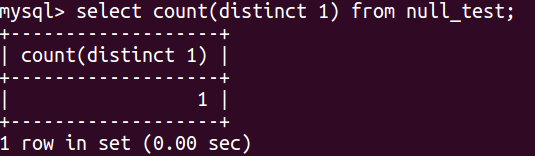
是不是很神奇,用我上面的解释是可以解得通的
6 . union把两个select语句的结果集组合成一个
(select * from user where id = 1) union (select * from user where id = 1 or id = 2)

(select * from user where id = 1) union all (select * from user where id = 1 or id = 2)

可以看到,使用union的时候,默认是去除了重复行,如同使用了distinct一般,如果要显示所有的结果,则要使用union all.
7 . 用between and,in,<= >=,< >条件查询
首先执行以下sql语句看看结果
select * from user where id between 1 and 2

再执行以下:
select * from user where id >= 1 and id <= 2
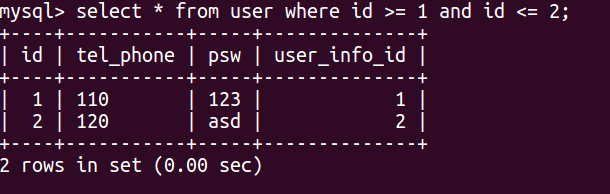
可以看到这俩个sql的结果是相同的,因为between and是等同于>= and <=
如果是要查询的条件不是一个连续的数值,可以用in
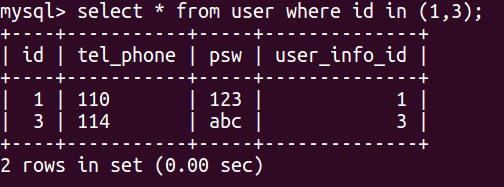
select * from user where id in (1,3)
8 .用group by
有的人在一开始接触mysql的时候,学到了group by语句的时候会有点不太明白,事实上这是一个分组语句,就是把结果相同的结果编为一组.
现在执行select nickname,count(1) from user_info

可以看到mysql报错了,因为这句sql当中的nickname字段会返回多行结果,而count(1)是一个统计聚合函数,只会返回一行结果,这样子mysql是无法知道把数据放哪里,但现在如果执行这个sql:
select nickname,count(1) from user_info group by nickname

后面加上了group by nickname,按照nickname字段去分组,若这个时候此字段的值,昵称2有两个的话,count(1)的值会显示2
group by会和聚合函数相结合使用(AVG(),MIN(),MAX(),SUM(),COUNT())
另外使用gruop by的时候还会经常和having,having和where的功能相似,但是where限制的是行,having限制的是组,例如现在执行以下sql:
select nickname,count(1) from user_info group by nickname having count(1) != 1
查询出来的结果集为空,因为根本没有符合条件的组,这句sql的意思是按照nickname分组,查询nickname和对应的数量,这时候应该会有多个组作为结果,然后再执行having语句限制组,要求各组的数量不等于1,就有了以上的结果
如果使用了group by和having的话,where , group by , having , order by语句的先后顺序为,where , group by ,having , order by
9 . limit分页显示
网页当中往往有现在是第几页,一共多少页,上一页,下一页,这样的分页功能就要用到mysql的limit了,它可以指定返回多少行数据,可以实现分页.
在整个sql语句的执行当中,limit是最后执行的,例如select * from user limit 99,1,这样的话,会先执行
select * from user,查出结果集,然后根据limit的第一个参数定位到位置,然后根据第二个参数取结果集的数量.
limit [offset,] rows,其中offset为偏移量,由0开始,rows表示返回多少行,现在执行这个sql:
select * from user limit 0,2:
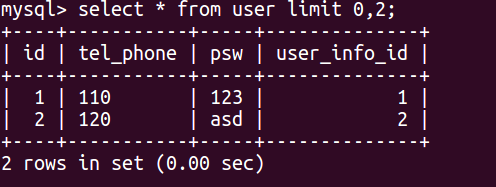
此sql 表示的是从第一行开始算起,一共返回两行数据.
上面的sql是相当于select * from user limit 2的
select * from user limit 1,2 //表示的为检索记录行2-3
10 . order by排序
首先执行select * from user order by id desc,按id降序排序

order by 字段名 asc/desc,其中asc是默认的排序,默认为升序,desc为降序,如何很好地记忆升序降序呢,升序就是第一行的值是最小的,然后越往下值越大就升序,降序反之.
order by后面可以跟多个字段,例如,select * from user order by tel_phone asc,id desc
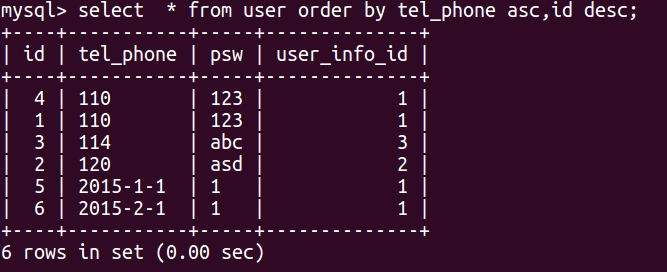
先按tel_phone字段升序,若tel_phone字段值相同的情况下,再按id降序.
另外非常值得注意的是,当tel_phone字段的值存在有NULL的时候,默认当中NULL值是最小的.