工作总结
这半个月主要围绕组会要讲的内容进行展开。
组会的整体框架:
- DCASE2019的任务介绍
- McDonnell的技术报告
- mixup的方法
- 谷歌大脑AutoAugment
主体工作:
- 这半个月一直在查找和阅读论文。
- 尝试从数据增强角度来解决DCASE任务,将语谱图随机对称翻转,发现其实对识别率影响不大。
- 了解了Eghbal-zadeh_CPJKU的技术报告,但是因为代码量实在太大,复现起来着实困难。
- 阅读谷歌大脑的《AutoAugment:Learning Augmentation Strategies from Data》,阅读了代码,发现公开的代码只给了相关数据集的训练参数,尝试用在语谱图上,但是效果不理想。
2019.12.01 日
-
阅读《Deep Convolutional Neural Network with Mixup for Environmental Sound Classification》
上海大学的文章,来源:Chinese Conference on Pattern Recognition and Computer Vision(PRCV)
主要内容:
① 文中列举了大量的相关方法,今后可以引用。
② 仿照VGG提出模型框架
③ Mixup
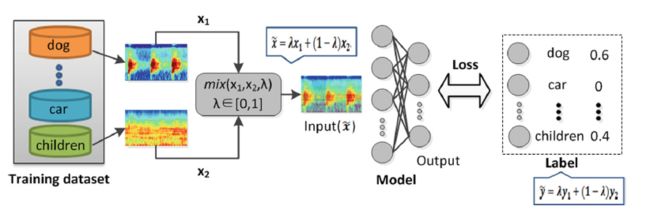
④ 将特征和特征一阶差分作为双通道输入网络 阅读《ENVIRONMENTAL SOUND CLASSIFICATION WITH CONVOLUTIONAL NEURAL NETWORKS》
来源:IEEE
主要内容:
① 现有方法仍主要限于分析高度预处理的声学特征。
②
2019.12.02 一
-
阅读《Temporal transformer networks for acoustic scene classification》
① 作者认为,ASC系统的理想特性是消除时间偏移干扰。 比如盘子的碰撞声是餐馆里的声音,如下图所示
主要内容:
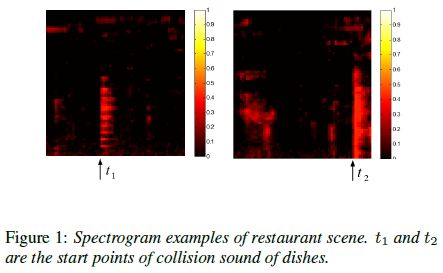
认为t1和t2处的事件相同,但与时间无关。
② 提出时间转变模块,该模块由用于特征图的傅立叶变换层和可学习的特征约简层组成。
2019.12.03 二
-
再补充一下频谱和语谱图的性质和关系。
来源:知乎:不同元音辅音在声音频谱的表现是什么样子?
频谱:由一小段波形(即一帧)做傅里叶变换(Fourier transform)之后取模得到的。如下图所示。录音的采样率用的是16000 Hz,频谱的频率范围也是0 ~ 16000 Hz。但由于0 ~ 8000 Hz和8000 ~ 16000 Hz的频谱是对称的,所以一般只画0 ~ 8000 Hz的部分。
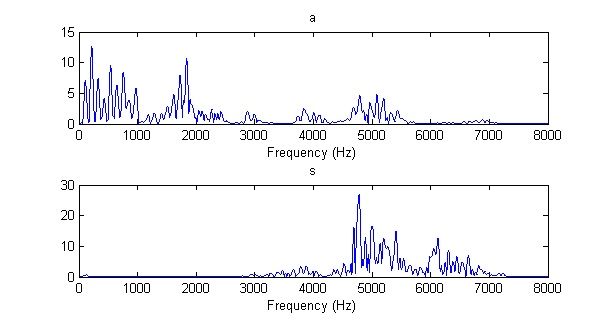
为什么所得信号的频谱均是关于中心点对称的:调制后的信号频谱以载波频率为中心,呈中心对称。每侧都是被调制信号的完整频谱。相当于把被调制信号的频谱搬到载波频率的两侧。
是实系列的对称性决定的,这种对称性叫做周期共轭对称,因为这个性质的存在,我们呢在计算DFT时,只需要计算一半,另一半可以根据这个性质推出。
语谱图:把一整段语音信号截成许多帧,把它们各自的频谱“竖”起来(即用纵轴表示频率),用颜色的深浅来代替频谱强度,再把所有帧的频谱横向并排起来(即用横轴表示时间),就得到了语谱图,它可以称为声音的时频域表示。 -
再复习下快速傅里叶变换(FFT)
来源:十分简明易懂的FFT(快速傅里叶变换)
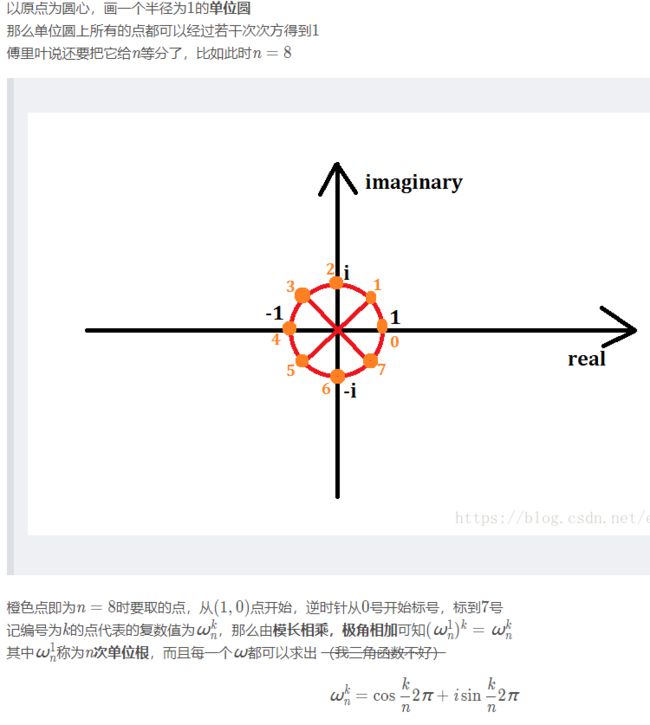
单位根的一些性质:
它们表示的点(或向量)表示的复数是相同的。
它们表示的点关于原点对称,所表示的复数实部相反,所表示的向量等大反向。
都等于,或 精读McDonnell的技术报告
① 一阶差分二阶差分的特征提取方法受到《Towards end-to-end speech recognition with deep convolutional neural networks》的启发
② 作者认为,低频特征的模式可能代表与高频特征不同的物理源。
2019.12.04 三
继续精读McDonnell的技术报告
③ 作者认为,为了确保CNN可以在所有时间样本中学习全局时间信息,使用标准的图像分类方法,即使用第2步卷积层定期进行定期下采样。 原理是,重要的提示可能会在10秒的样本中的任何时间点以相同的可能性发生,就像图像中的对象可以出现在任何空间位置一样。阅读《Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks》
该文中提出使用特征的一阶差分和二阶差分作为其他channel,保留频谱图的局部相关性。
2019.12.05 四
- 阅读Eghbal-zadeh_CPJKU的技术报告
① 主要还是ResNet和DenseNet
② 提出频率Frequency-Aware Convolutional Neural Networks (FACNNs),输入的频率位置作为附加通道添加到CNN层
③ 感受野正则化 - 开始研究Eghbal-zadeh_CPJKU的代码,pytorch。
2019.12.06 五
- 学习python的可调用对象(callable)。
① 来源:Python call详解
- 凡是可以把一对括号()应用到某个对象身上都可称之为可调用对象。
- 如果在类中实现了 call 方法,那么实例对象也将成为一个可调用对象。
- 基于类的装饰器:
class Counter:
def __init__(self, func):
self.func = func
self.count = 0
def __call__(self, *args, **kwargs):
self.count += 1
return self.func(*args, **kwargs)
@Counter
def foo():
pass
for i in range(10):
foo()
print(foo.count) # 10
首先这里的@Counter是装饰器,执行起来顺序是 foo = Counter(foo), 实例化,把foo函数传到类Counter里面,并存到对象属性里面,然后返回foo = Counter实例。 这时foo已经是Counter实例,而不是本身foo函数。
当执行foo()的时候,其实已经变成了,执行call函数,而这个函数里面是执行了本身的self.func 即foo的实际逻辑, 而且加上了计算调用次数。这样就记录状态了。
②
来源:python func(*args, **kwargs)
func(*args, **kwargs)
*args, **kwargs表示函数的可变参数
*args 表示任何多个无名参数,它是一个tuple
**kwargs 表示关键字参数,它是一个dict
例:
def foo(*args,**kwargs):
print('args=',args)
print('kwargs=',kwargs)
print('**********************')
if __name__=='__main__':
foo(1,2,3)
foo(a=1,b=2,c=3)
foo(1,2,3,a=1,b=2,c=3)
foo(1,'b','c',a=1,b='b',c='c')
输出:
args= (1, 2, 3)
kwargs= {}
**********************
args= ()
kwargs= {'a': 1, 'b': 2, 'c': 3}
**********************
args= (1, 2, 3)
kwargs= {'a': 1, 'b': 2, 'c': 3}
**********************
args= (1, 'b', 'c')
kwargs= {'a': 1, 'b': 'b', 'c': 'c'}
**********************
③ repr() 函数
来源:Python repr()方法:显示属性
class Apple:
# 实现构造器
def __init__(self, color, weight):
self.color = color;
self.weight = weight;
# 重写__repr__方法,用于实现Apple对象的“自我描述”
def __repr__(self):
return "Apple[color=" + self.color +\
", weight=" + str(self.weight) + "]"
a = Apple("红色" , 5.68)
# 打印Apple对象
print(a)
输出:
Apple[color=红色, weight=5.68]
从上面的运行结果可以看出,通过重写 Apple 类的 repr() 方法,就可以让系统在打印 Apple 对象时打印出该对象的“自我描述”信息。
2019.12.07 六
CPJKU是用json读取的程序参数,这一块儿可以学习一下。
2019.12.08 日
整理组会要做的内容
2019.12.09 一
-
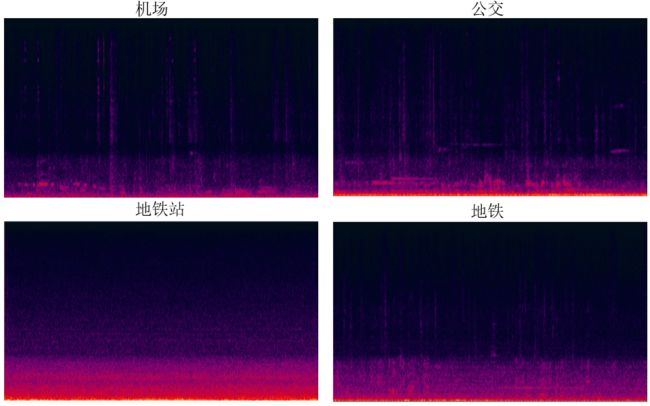
再次观测数据,从音频数据中挑出10个wav,利用cool Edit Pro生成语谱图,观察情况。发现,高频位置信息量很少,绝大部分信息集中在低频。
- 阅读《Mixup-Based Acoustic Scene Classification Using Multi-Channel Convolutional Neural Network》,寻找数据增强的方法。
① 多通道的音频数据输入CNN。
② 引入mixup
在其中发现了2017年的DCASE中有人使用GAN做数据增强,但是2017年的比赛只有单一录音设备。
2019.12.10 二
阅读《THE DETAILS THAT MATTER: FREQUENCY RESOLUTION OF SPECTROGRAMS IN ACOUSTIC SCENE CLASSIFICATION》
文章论证了对于MFCC,更多的梅尔波段可以提高准确性,而对学习时间的影响则可以忽略不计。阅读《AutoAugment: Learning Augmentation Strategies from Data》
AutoAugment: Learning Augmentation Policies from Data(一种自动数据增强技术)
谷歌大脑提出自动数据增强方法AutoAugment:可迁移至不同数据集。
① 现在视觉方向的研究将重点放在了深度学习框架中,人们很少关注寻找更好的、包含更多不变性的数据增强方法。
② 每个策略都表示一些可能的数据增强操作的选项和顺序,其中每一个操作是图像处理函数(例如,平移、旋转或色彩归一化),及应用该函数的概率和幅度(magnitude)。
③ 从一个数据集中学到的策略能够被很好地迁移到其它相似的数据集上。
2019.12.11 三
-
在GitHub上找到了AutoAugment的代码,运行了结果:
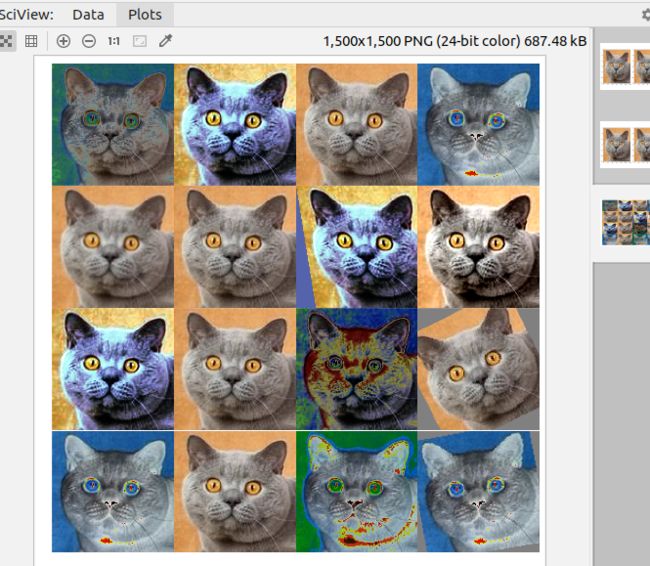
尝试从图像转换到语谱图的应用上。
尝试的过程中发现,GitHub的代码是直接对图像文件进行操作,而不是对对应的矩阵值进行操作,因此没有办法直接使用,所以现在需要对log-mel特征矩阵再做进一步分析。
分析发现,librosa提取的特征,都是大于0的,而这个值是“能量”,再去了解一下能量的概念。
2019.12.12
-
尝试训练时随机翻转语谱图进行训练,得到的结果为76.68%
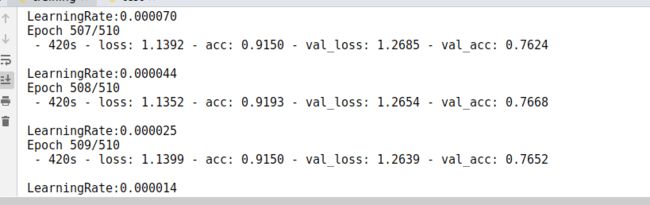
- 开始训练不添加mixup的模型
-
在生成数据时添加了对频率维度的随机裁剪,但暂时来看训练结果并不理想。

2019.12.13
着手准备组会PPT,绘制McDonnell的模型框架图。
2019.12.14
仔细阅读《mixup: BEYOND EMPIRICAL RISK MINIMIZATION》