数据集用的是iris也就是一个记录鸢尾属植物品种的样本集,数据集中一共包含了150条记录,每个样本的包含它的萼片长度和宽度,花瓣的长度和宽度以及这个样本所属的具体品种。每个品种的样本量为50条。
#导入数据
attach(iris)
#查看数据结构
str(iris)

#查看数据前3行
head(iris,3)
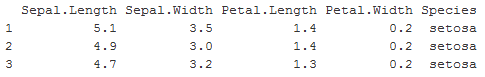
因为要使用knn包进行聚类分析,则将列Species置为空,将此数据集作为测试数据集
data<-iris[,-5]
第一种方法:层次聚类
层次聚类首先将每个样本单独作为一类,然后将不同类之间距离最近的进行合并,合并后重新计算类间距离。这个过程一直持续到将所有样本归为一类为止。
#首先计算均值和标准差
mean<-sapply(data,mean)
sd<-sapply(data,sd)
#再将数据进行z-score标准化
scaledata<-scale(data,center=mean,scale=sd)
head(scaledata,3)

method表示计算哪种距离。method的取值有:
euclidean 欧几里德距离,就是平方再开方。
maximum 切比雪夫距离
manhattan 绝对值距离
canberra Lance 距离
minkowski 明科夫斯基距离,使用时要指定p值
binary 定性变量距离
#再计算距离
dist<-dist(scaledata,method="euclidean")
#作热力图,通过生成一堆的向量,转换为矩阵,得到想要的数据,去掉行标签和列标签
heatmap(as.matrix(dist),labRow = F,labCol = F)

从图中可以看到颜色越深表示样本间距离越近,大致上可以区分出三到四个区块,其样本之间比较接近。
然后使用hclust函数(d=dist,即样本间的距离矩阵,method为计算类间距离的方法),建立聚类模型,结果存clustemodel变量中,其中ward参数是将类间距离计算方法设置为离差平方和法。使用plot(clustemodel)可以绘制出聚类树图。如果我们希望将类别设为3类,可以使用cutree函数提取每个样本所属的类别。
#使用Ward方法层次聚类
clustemodel<-hclust(dist,method='ward.D')
plot(clustemodel)

#选择聚类的适当个数
library(NbClust)
devAskNewPage(ask = TRUE)#控制(对于当前设备)是否在开始输出新页面之前提示用户,如果TRUE,将来会在启动新页面输出之前提示用户
nc<-NbClust(scaledata,distance="euclidean",min.nc = 2,max.nc = 15,method = "average")
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),xlab = "聚类个数",ylab = "判定准则")

result1<-cutree(clustemodel,k=2)
result1

result2<-cutree(clustemodel,k=3)
result2

最后我们来观察真实地类别和聚类之间的差别
table(iris[,5],result1)

table(iris[,5],result2)

发现virginica类错分了23个样本
最后我们计算3个组的中心点即实心圆,空心圆表示不同样本的位置
plot(data[,1],data[,2])
center<-aggregate(data,list(result1),mean)
points(center[,2],center[,3],pch=19)

层次聚类的特点是:基于距离矩阵进行聚类,不需要原始数据,可用于不同形状的聚类,但它对于异常点非常敏感,对于数据规模较小的数据比较合适,否则计算量会很大,聚类后切分数组可根据业务知识,也可根据聚类树图的特点
第二种方法:K-means聚类
K均值聚类又称为动态聚类,它的计算方法较为简单,也不需要输入距离矩阵。首先要指定聚类的分类个数N,随机取N个样本作为初始类的中心,计算各样本与类中心的距离并进行归类,所有样本划分完成后重新计算类中心,重复这个过程直到类中心不再变化。
在R中使用kmeans函数进行K均值聚类,centers参数用来设置分类个数,nstart参数用来设置取随机初始中心的次数,其默认值为1,但取较多的次数可以改善聚类效果。clustemodel1$cluster可以用来提取每个样本所属的类别。
使用K均值聚类时需要注意,只有在类的平均值被定义的情况下才能使用,还要求事先给出分类个数。一种方法是先用层次聚类以决定个数,再用K均值聚类加以改进。或者以轮廓系数来判断分类个数。改善聚类的方法还包括对原始数据进行变换,如对数据进行降维后再实施聚类。
data<-iris[,1:4]
#决定聚类的个数
library(NbClust)
devAskNewPage(ask = TRUE)
nc<-NbClust(scaledata,min.nc = 2,max.nc = 15,method = "kmeans")
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),xlab = "聚类个数",ylab = "判定准则")

#数据用上面已经标准化后的数据,因为涉及到距离,就要将不同维度上的值域统一
set.seed(123)
#进行K均值聚类
clustemodel1<-kmeans(scaledata,centers = 3,nstart = 10)
#聚类规模
clustemodel1$size
clustemodel1$cluster
