本人英文水平有限,翻译读起来磕磕巴巴,大概只能表述基本意思,希望大家谅解,如果有好的建议,也欢迎指正.
翻译原文地址:https://cwiki.apache.org/confluence/display/solr/Running+Solr+on+HDFS
Solr支持从HDFS分布式文件系统读写它的索引和事务日志文件。它并不是利用Hadoop的MapReduce去处理solr数据,而仅仅是用HDFS文件系统来进行索引和事务日志的存储。
利用HDFS替换本地存储系统,你必须用Hadoop2.x版本,且你需要设置Solr使用HdfsDirectoryFactory,另外还有些其他的额外参数需要定义,你可以通过三种方式来设置它们:
1、在启动的时候作为JVM的参数传递给bin/solr这个脚本,不过它需要你每次启动的时候都需要传递。
2、更改solr.in.sh(solr.in.cmd windows上)去自动传递JVM参数,而不用手动指定。
3、在solrconfig.xml中定义,这些配置每个索引都要重复定义,不过对于部分需要存储在HDFS的索引来说是个好的选项。
独立模式
对于独立的solr实例来说,在启动前,一些参数需要修改。可以在solrconfig.xml或者直接在启动的时候传递给bin/solr脚本。
l需要指定使用HdfsDirectory和hdfs格式的数据目录:hdfs://host:port/path
l需要指定hdfs格式的更新日志目录位置:hdfs://host:prot/path
l需要指定锁定factory为hdfs或者空。
如果你不想更改solrconfig.xml文件,你可以使用:
bin/solr start -Dsolr.directoryFactory=HdfsDirectoryFactory
-Dsolr.lock.type=hdfs
-Dsolr.data.dir=hdfs://host:port/path
-Dsolr.updatelog=hdfs://host:port/path
云模式
在云模式中,最好的方式是简单的指定solr.hdfs.home选项,由solr在创建索引时候,会在solr.hdfs.home指定的目录下自动创建数据和更新日志目录。
l设定solr.hdfs.home=hdfs://host:port/path
l设定锁定工厂为hdfs或者空.
bin/solr start -c -Dsolr.directoryFactory=HdfsDirectoryFactory
-Dsolr.lock.type=hdfs
-Dsolr.hdfs.home=hdfs://host:port/path
更改solr.in.sh(solr.in.cmd)文件
以上方式是通过启动solr时候,人工传递JVM参数来使用HDFS,这样在每次启动的时候都需要设置。在Solr启动的时候会去在bin目录下找solr.in.sh(solr.in.cmd在windows下)去设置环境变量。你可以在这个文件里设置好相关参数,不用每次启动时候输入。
如果solr云模式经常是在HDFS上运行的,可以如下设置:
# Set HDFS DirectoryFactory & Settings
-Dsolr.directoryFactory=HdfsDirectoryFactory \
-Dsolr.lock.type=hdfs \
-Dsolr.hdfs.home=hdfs://host:port/path \
块缓存
为了性能原因,HdfsDirectoryFactory用Directory进行缓存HDFS块。这个缓存机制取代了solr利用的的标准文件系统缓存。默认情况下,缓存是在堆外分配的。
这个缓存是相当大的,你需要提高solr的特定JVM堆外缓存的限制。在Oracle/OpenJDK JVM中,以下的命令行参数你可以用来提升限制:
-XX:MaxDirectMemorySize=20g
HdfsDirectoryFactory参数
HdfsDirectoryFactory有许多参数设置,被定义为directoryFactory的一部分。
Solr的HDFS设置

块缓存设置

近实时查询设置
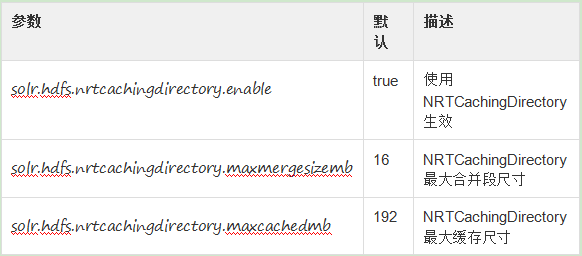
HDFS的客户端配置设置
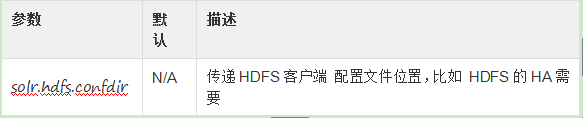
Kerberos认证设置
Hadoop可以配置使用Kerberos协议来确定用户身份,当用户访问类似HDFS等核心服务的时候,如果你的HDFS目录是用Kerberos来包婚的,你需要配置solr的HdfsDIrectoryFactory来使用Kerberos进行认证以便读写HDFS。
为此你需要设置下面参数:

Solr.confg中配置例子
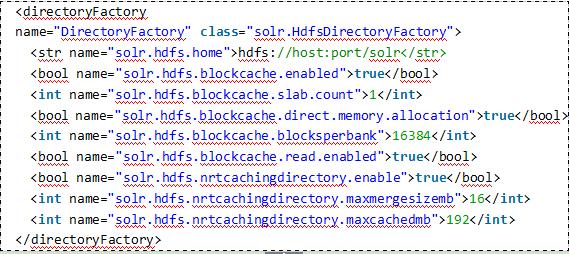
如果使用kerberos,你需要添加kerberos的相关属性,如下:

Solr云模式下自动添加副本
将Solr运行在HDFS上有个好处,就是监工注意到一个shard有问题时候,有能力自动添加一个新的副本。因为当掉的索引shard是保存在HDFS上的,新的core
将被创建。
Collection利用autoAddReplicas=true在一个共享的文件系统创建时候,可以具有自动添加一个副本能力。可以重写配置在solr.xml中配置部分的默认值。
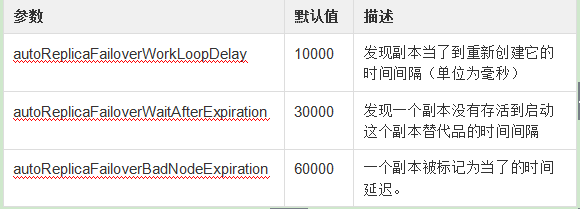
暂时为整个集群禁用自动添加副本功能
在离线维护集群和其他各种使用情况下,管理员想暂时禁止自动添加副本,下面的API将禁用和启用集群中所有collection的autoAddReplicas功能。
禁用自动添加集群副本功能,可以通过设置集群属性autoAddReplicas为false来得到:
http://localhost:8983/solr/admin/collections?action=CLUSTERPROP&name=autoAddReplicas&val=false
再次启用自动添加副本功能,当没有参数提供时候,集群属性是未设置的。
http://localhost:8983/solr/admin/collections?action=CLUSTERPROP&name=autoAddReplicas