Redis 是何时会选取 intset 作为底层存储结构?
我们从最基础的 SADD 命令开始,让我们一起看看 Redis 是如何使用 intset 存储元素的
我们来看看 saddCommand() 方法里面的部分逻辑内容:
// 如果当前集合不存在则创建该集合
if (set == NULL) {
// 使用指定的名称创建一个 set 集合
// todo: 这里是 set 底层结构创建的地方
set = setTypeCreate(c->argv[2]->ptr);
// 往 db 中添加该集合
dbAdd(c->db,c->argv[1],set);
} else {
// 如果不是 set 类型
if (set->type != OBJ_SET) {
// 抛出异常
addReply(c,shared.wrongtypeerr);
return;
}
}
进入 setTypeCreate 一探究竟:
robj *setTypeCreate(sds value) {
// 判断 sds 类型的 value 是否可以装换成 long long 类型
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
// 返回 intset 集合类型
return createIntsetObject();
// 否则创建一个 SET 对象,底层是 hashtable
return createSetObject();
}
我们可以看到,redis 先会把 sds 的 value 装换成 long long 类型,如果转换成功则返回 intset 集合类型作为底层的存储结构,并将当前 set 的编码类型设置成 intset。否则使用 hashtable 作为底层的存储结构。然而这个 value 的值又是怎么来的呢?
set = setTypeCreate(c->argv[2]->ptr);
看到 c->argv[2]-> ptr 这个就是拿到我们输入命令的值,我们知道 redis 会把每个命令根据空格分开而放到 argc 数组里面。比如 sadd marvel "k1" "k2" "k3" 那么 c->argv[2]-> ptr 拿到的值就是 k1 了。
但是只拿第一个元素就创建一个 intset 集合这样是不是不太严谨呢?因为我们的数据形式可能是前几个是数字,后面可能就是字符串了。那现在 redis 又会怎么办呢?别急,我们继续往下看
saddCommand 里面还有添加所有 value 的逻辑:循环添加每一个值
// 往集合中添加元素
for (j = 2; j < c->argc; j++) {
// 循环将每个值都添加到指定的 set 里面
if (setTypeAdd(set,c->argv[j]->ptr)) added++;
}
这里 j 为什么从 2开始我在前面已经解释。saddCommand 是通过循环添加 value 的。接下来我们就进入 setTypeAdd 探探险吧!
// 如果 set 编码格式是 hashtable
if (subject->encoding == OBJ_ENCODING_HT) {
dict *ht = subject->ptr;
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL);
return 1;
}
}
setTypeAdd 方法里面会再次判断 set 的编码类型,如果是 hashtable,则直接在hashtable 中添加元素。
// 如果 subject 的编码格式是 intset
if (subject->encoding == OBJ_ENCODING_INTSET) {
// 这里还得判断 value 是否可以转换成 long long 类型
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
uint8_t success = 0;
// 往 intset 中添加元素
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
/*
* 如果元素太多,则会转换成 hashtable 来存储。
* todo:如何 intset 集合中的元素 > server.set_max_intset_entries(配置文件中配置)则转换成 hashtable 存储
*/
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
// 重新装换成 hashtable
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
/**
* todo:无法从对象中获取整数,则会将 intset 装换成 hashtable
*/
setTypeConvert(subject,OBJ_ENCODING_HT);
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
}
这里我们看到 set 实际中的 intset 集合的。了解过 redis set 集合的小伙伴们都知道,set 如果采用 intset 存储整数元素,一旦里面的元素超过某个阈值就会转成 hashtable 来存储,看到源码里面会直接判断 intset 长度是否大于配置文件中配置的 server.set_max_intset_entries ,一旦大于则会重新将 intset 里面的元素填充到 hashtable 里面。这里有个小疑问。为什么超过了这个阈值就不要用 intset 存储了呢?为甚就要装换成 hashtable 来存储呢?小伙伴们可以带着这个问题继续往下看。
细心的小伙伴们会发现,这段逻辑里面会判断后加入的 vaule 是否可以转成 long long 类型,如果可以则继续往 intset 里面添加,如果装换不了,说明后续添加了非整型的数据,那么这样肯定就不能使用 intset 存储元素了,redis 就会调用 setTypeConvert 方法将 set 的底层存储结构装换成 hashtable,并将原来 intset 里面的所有元素都转移到 hashtable 里面去。
以上就是 set 如何选取底层结构的过程。小伙伴们都清楚了么?
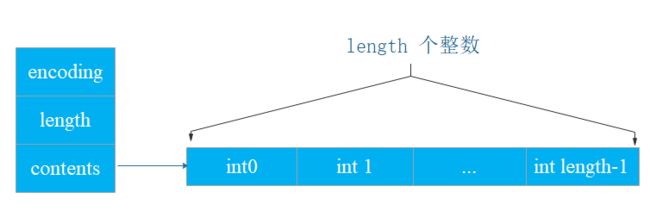
intset 数据结构简介
/**
* 整型数据结构体
*/
typedef struct intset {
// 数据编码,表示 intset 中的每个元素用几个字节来存储
uint32_t encoding;
// 集合长度
uint32_t length;
/*
* 用来存储集合的容器,是一个柔性数组(flexible array member)
*
* 比起指针用空数组有这样的优势:
* 1. 不需要初始化,数组名直接就是缓冲区数据的起始地址(如果存在数据)
* 2. 不占任何空间,指针需要占用4 byte长度空间,空数组不占任何空间,节约了空间
*/
int8_t contents[];
int8_t contents[];
} intset;
下面介绍一下每个字段的意思:
· encoding:数据编码,INTSET_ENC_INT16 表示每个元素用2个字节存储、INTSET_ENC_INT32 表示每个元素用4个字节存、INTSET_ENC_INT64 表示每个元素用8个字节存储,因此,intset中存储的整数最多只能占用64bit。这里为什么不直接使用 INTSET_ENC_INT64 存储呢?
· length:表示 intset 中的元素个数。encoding 和 length 两个字段构成了 intset 的头部(header)
· contents:是一个柔性数组,表示 intset 的 header 后面紧跟着的数据元素。C 语言不定长度数组了解一下。
intset 的存储结构如下图:
元素存储特点
作为一个集合,判断集合中是否存储在某一个元素是一个常用的操作。如果一般在数组中查找元素无非就是遍历整个是数组,但是这样效率太慢了,由于 intset 存储的元素都是有序的,所以 redis 采用二分法加快查找过程。为什么说 intset 存储的元素是有序的呢?这就得靠 intsetSearch() 方法了。我们从intset 的添加方法开始分析。
// 添加一个整数节点
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
// 返回该值实际的编码
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
// 将intset升级为更大的编码并插入给定的整数。
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is, value);
} else {
// todo:判断该值是否已经存在该集合之中,并计算该元素应该放置的位置
if (intsetSearch(is, value, &pos)) {
if (success) *success = 0;
return is;
}
// todo: 给数组扩容,每次扩容 1 个单位
is = intsetResize(is, intrev32ifbe(is->length) + 1);
// 如果 pos < length 则将 pos 后面的元素后移一位,想想数组实现的线下表就能明白了
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is, pos, pos + 1);
}
// 在指定位置插入元素
_intsetSet(is, pos, value);
is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);
return is;
}
看到源码的小伙伴可能会有疑惑,这里面并没有做排序处理呀,怎么就能保证插入的元素是有序的呢?接着看 intsetSearch() 方法了。
// todo: intset.c 使用二分法查找该元素是否已经存在该集合之中,同时计算该位置应该要放置的位置
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length) - 1, mid = -1;
int64_t cur = -1;
/* 如果集合为空,则之间将 pos 设置为0 */
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
// 这里说明元素肯定不在集合当中
/* 如果该值比最后一个元素还要大,则将 pos 设置为 length */
if (value > _intsetGet(is, intrev32ifbe(is->length) - 1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
// 如果元素比第一元素还小,则将 pos 设置为 0
} else if (value < _intsetGet(is, 0)) {
if (pos) *pos = 0;
return 0;
}
}
// 元素可能会在集合中,采用二分法查找元素
while (max >= min) {
// 标准二分法
mid = ((unsigned int) min + (unsigned int) max) >> 1;
// 获取指定位置上的元素
cur = _intsetGet(is, mid);
if (value > cur) {
min = mid + 1;
} else if (value < cur) {
max = mid - 1;
} else {
// mid 可能和 value 相同,或者
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
// todo:给 pos 赋值
if (pos) *pos = min;
return 0;
}
}
我们发现 intsetSearch() 方法其实做了两件事,一件事是查找指定元素是否存在集合中,另一件事就是添加元素的时候计算元素应该插入的位置。里面涉及元素大小比较。我们知道二分法其实不涉及排序,但是 redis 添加操作却可以结合二分法完成元素排序操作(也就是根据元素大小插入到指定位置),以此来保证 intset 里面的元素都是有序的。不得不说设计的非常巧妙啊。
升级&降级
当我们创建一个 intset 集合的时候,redis 会直接创建一个 intset_enc_int16 的intset。
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
// 创建一个保存两字节大小的 intset 集合
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}
我们知道 intset.c 中是这样定义这几个常量的
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
我们知道 int16_t 其实就是 16bit,所以只能存储两个字节的数字。然而我们添加的数据可能是占 2字节,也可能是占 4字节,也可能占 8字节。那么这样就涉及到 intset 升级了。升级整数集合并添加新元素分为三步进行:
① 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
② 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
③ 将新元素添加到底层数组里面。
/*
* todo: 如果给定的值超过了当前数组的编码,那么该方法会将 intset 升级为更大的编码然后插入给定整数
* 插入的元素要么比当前集合编码大,要么比编码小,所以要么在尾部插入,要么在头部插入
*/
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
// 旧的编码格式
uint8_t curenc = intrev32ifbe(is->encoding);
// 插入元素的编码格式
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
// 该值是用来判断 value 在 beginning 还是 end 位置插入的标志
int prepend = value < 0 ? 1 : 0;
/* First set new encoding and resize */
is->encoding = intrev32ifbe(newenc);
// 扩容一个元素
is = intsetResize(is, intrev32ifbe(is->length) + 1);
while (length--)
_intsetSet(is, length + prepend, _intsetGetEncoded(is, length, curenc));
/* Set the value at the beginning or the end. */
if (prepend)
_intsetSet(is, 0, value);
else
_intsetSet(is, intrev32ifbe(is->length), value);
is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);
return is;
}
看上边的源码好像并没有看到集合升级过程,但是我们看到了一个 intsetResize() 扩容方法,我们看看里面的具体实现是什么吧!
// Resize the intset 扩容,重新分配数组的大小, 每次扩容一个元素
static intset *intsetResize(intset *is, uint32_t len) {
// 计算新增的字节数,因为可能涉及扩容了
// 比如 len = 11 但是现在编码变成了 INTSET_ENC_INT64,所以要重新计算is 的内存大小
uint32_t size = len * intrev32ifbe(is->encoding);
// 重新分配内存
is = zrealloc(is, sizeof(intset) + size);
return is;
}
光看源码可能理解起来有点困难,那么我们看一个 demo 吧!举个栗子:假设现在有一个 INTSET_ENC_INT16 编码的整数集合,集合中
我们要将int32_t 的整数值 65535 添加到整数集合,集合中包含三个 int16_t 类型的元素,每个元素都占用 16 位空间,所以整数集合底层数组的大小为 3 * 16 = 48bit,如下图:

现在,假设我们要将类型为 int32_t 的整数值 65535 添加到整数集合里面,因为 65535 的类型 int32_t 比整数集合当前所有元素的类型都长,所以在将 65535 添加到整数集合之前,程序需要先对整数进行升级。
升级首先要做的是,根据新类型的长度,以及集合元素的数量(包括要添加的新元素在内),对底层数组进行空间重分配,也就是上面的 intsetResize() 方法。整数集合目前有三个元素,再加上新元素 65535,整数集合需要分配四个元素的空间,因为每个 int32_t 整数值需要占用 32位空间,所以在空间重分配之后,底层数组的大小将是 32 * 4 = 128bit,如下图所示。虽然程序对底层数组进行了空间重分配,但数组原有的三个元素 1、2、3任然是 int16_t 类型,这些元素还保存在数组的前 48位里面。所以程序接下来要做的就是将这三个元素转换成 int32_t 类型,并将转换后的元素放到正确的位上,而且在放置元素的过程中,需要维持底层数组的有序性质不变。

首先,因为元素 3 在 1、2、3、65535 四个元素中排名第三,所以它将被移动到 contents 数组的索引 2 位置上,也即是数组 64位至95位的空间内,如图所示:

接着,因为元素 2 在 1、2、3、65535 四个元素中排名第二,所以它将被移动到 contents 数组的索引 1 位置上,也即是数组 32位至64位的空间内,如图所示:

同理,对元素1 也是和前面做同样的操作,当这些元素全部放到这指定的位置上之后,在添加新元素,如图所示:
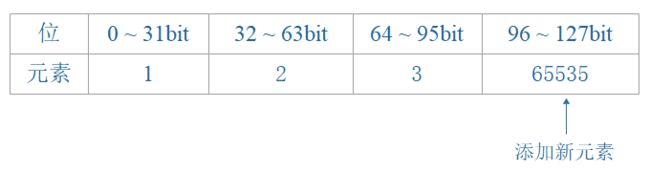
最后,程序将整个集合 encoding 属性的值从 INTSET_ENC_INT16 改为 INTSET_ENC_INT64,并将 length 属性从 3 改为 4。好了,一个升级的过程到此就结束了。小伙伴们都明白了么?
升级的好处:要让一个数组可以同时保存 int16_t、int32_t、int64_t 三种类型的值,最简单的方法就是直接使用 int64_t 类型数组作为整数集合的底层实现。但是这样如果添加到集合中的元素里面都是int16_t、int32_t 类型的值,数组都需要使用 int64_t 类型的空间去保存它们,从而出现浪费内存的情况。所以升级可以尽量节省内存。
疑问:为什么不直接采用三个数组来存储元素呢?因为 intset 只有升级没有降级,如果一个数组里面只有一个数是 int64_t,那不还是到了最坏的情况吗?
intset 暂时并没有提供降级操作......
文章进行到这里,基本上已经把 intset.c 里面的难点讲的差不多了,至于删除和修改操作这里就不再讲述了,比较简单,感兴趣的小伙伴们可以去看看源码哦!!!
大端序列和小端序列
看到这里不知道小伙伴们有不有这样一个疑问,代码里面 intrev32ifbe() 方法出镜率很高啊!它到底是干什么的呢,接下来我们就讲讲这个方法!
endianconv.h 里面有这样几个方法
#define intrev16ifbe(v) intrev16(v)
#define intrev32ifbe(v) intrev32(v)
#define intrev64ifbe(v) intrev64(v)
我们到 endianconv.c 里面看看具体的定义,由于方法类似,只是操作位数不一样而已,所以这里只挑出 intrev16ifbe() 来讲
uint64_t intrev64(uint64_t v) {
memrev64(&v);
return v;
}
/*
* 由于 Redis 大部分采用的是小端序列,但是 TCP/IP 协议要求网络传输的时候
* 统一采用大端序列传输数据,所以这里就涉及小端切换大端的操作
*
* 将* p指向的16位无符号整数从小端切换到大端
*/
void memrev16(void *p) {
unsigned char *x = p, t;
t = x[0];
x[0] = x[1];
x[1] = t;
}
其实方法很简单,只是把小端序列转换成大端序列。大小端序列在 java nio 中出现了哦。不知道你们读 java nio 源码的时候有没有发现呢?这里就不对大小端做过多介绍了。感兴趣的朋友可以去查阅资料哦!
答疑区:
总结一下文章里面我提出的问题,算是自问自答吧!
① 为什么要设置 set_max_intset_entries 这个阈值?
② 为什么不直接使用 INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64三种类型的数组分别存储元素呢?
大家可以进群讨论源码:
钉钉群:
微信群:
