各种SPI实现均通过ClassLoader加载, 如何获取ClassLoader, 可以参考各框架源码, 或参考链接:
https://www.jianshu.com/p/8c0adcdbafa5
1.SPI概述
SPI 全称为 Service Provider Interface,是一种服务发现机制.
比如你有个接口,该接口有3个实现类,那么在系统运行时,这个接口到底选择哪个实现类呢?
这就需要SPI了,需要根据指定的配置或者是默认的配置,找到对应的实现类加载进来,然后使用该实现类的实例.
#如:
接口A => 实现A1,实现A2,实现A3
配置一下,接口A = 实现A2
在系统实际运行的时候,会加载你的配置,用实现A2实例化一个对象来提供服务
比如说你要通过jar包的方式给某个接口提供实现,
然后你就在自己jar包的META-INF/services/目录下放一个接口同名文件,
指定接口的实现是自己这个jar包里的某个类.
ok了,别人用了一个接口,然后用了你的jar包,就会在运行的时候通过你的jar包的那个文件找到这个接口该用哪个实现类.
这是JDK提供的一个功能.
比如你有个工程A,有个接口A,接口A在工程A是没有实现类的,那么问题来了,系统运行时,怎么给接口A选择一个实现类呢?
你可以自己搞一个jar包,META-INF/services/,放上一个文件,文件名即接口名,接口A,接口A的实现类=com.javaedge.service.实现类A2
让工程A来依赖你的jar包,然后在系统运行时,工程A跑起来,对于接口A,
就会扫描依赖的jar包,看看有没有META-INF/services文件夹,
如果有,看再看有没有名为接口A的文件,如果有,
在里面找一下指定的接口A的实现是你的jar包里的哪个类!
经典的思想体现,其实大家平时都在用,比如说JDBC
Java定义了一套JDBC的接口,但是并没有提供其实现类
但实际上项目运行时,要使用JDBC接口的哪些实现类呢?
一般来说,我们要根据自己使用的数据库,比如
MySQL,你就将mysql-jdbc-connector.jar
oracle,你就将oracle-jdbc-connector.jar引入
系统运行时,碰到你使用JDBC的接口,就会在底层使用你引入的那个jar中提供的实现类
2.jdk中的SPI机制(jdk1.6开始)
2.1基本要求
0.定义一个接口, 以及接口对应的实现类
1.配置文件要求
1.1必须在classpath下, 即resources目录下建立META-INF/services/目录
1.2以接口全限定名为文件名, 实现类全限定名写在对应接口文件中, 多个实现类时, 换行展示
2.ServiceLoader类实现了Iterable接口, 以便于遍历某接口下的所有实现类
3.ServiceLoader类通过ClassLoader来读取classpath下META-INF/services/目录的文件:
默认使用"Thread.currentThread().getContextClassLoader()"来加载, 也可指定其他类加载器
4.ServiceLoader类的私有内部类LazyIterator实现了Iterable接口,功能 & 要求如下:
4.1支持懒加载机制(可通过某实现类中添加'静态代码块', 该实现类不配置到META-INF/services文件中来验证)
4.2由于在其遍历时,通过反射new了实现类, 因此接口实现类必须要有空参构造器, 否则加载失败
5.Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。



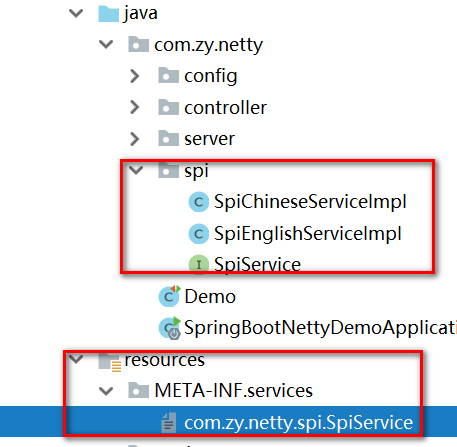
package com.zy.netty.spi;
/**
* jdk的spi机制
*/
public interface SpiService {
void sayHello(String name);
}
package com.zy.netty.spi;
public class SpiChineseServiceImpl implements SpiService {
@Override
public void sayHello(String name) {
System.out.println(name + ", 你好啊!");
}
}
package com.zy.netty.spi;
public class SpiEnglishServiceImpl implements SpiService {
@Override
public void sayHello(String name) {
System.out.println(name + ", hello!");
}
}
在src/main/resources 下创建META-INF/services/目录,然后新建文件:
文件名为接口的全限定名,接口中的内容按行分开,每一行是实现类的全限定名

@Test
public void fn03() {
ServiceLoader loader = ServiceLoader.load(SpiService.class);
Iterator it = loader.iterator();
while (it.hasNext()) {
it.next().sayHello("tom");
}
}
3.dubbo中的SPI机制
http://dubbo.apache.org/zh-cn/docs/source_code_guide/dubbo-spi.html
http://dubbo.apache.org/zh-cn/docs/dev/SPI.html
https://www.jianshu.com/p/764cec6ebb3d (Dubbo SPI重点参考)
3.1基本要求
1.定义一个接口, 接口必须加 '@SPI'注解, 否则报错
1.1由于通过反射new了实现类, 因此接口实现类必须要有空参构造器, 否则加载失败
2.配置文件要求
2.1必须在classpath下, 即resources目录下建立目录, 目录名分三类
2.2以接口全限定名为文件名, 实现类全限定名写在对应接口文件中(k-v结构), 多个实现类时, 换行展示
3.ExtensionLoader通过ClassLoader加载目录



使用示例
dubbo提供了多种通信协议类型, 如dubbo类型, http类型, hessian类型等
若想在项目中使用其中一种类型, 可行的配置如下图所示


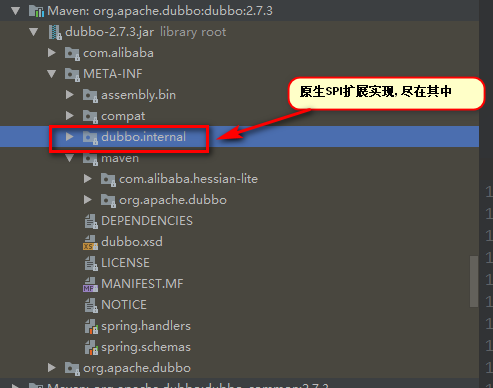
3.2 Dubbo SPI 扩展实现
http://dubbo.apache.org/zh-cn/docs/dev/impls/filter.html

引入下述依赖后, 即可看到相关扩展实现类
org.apache.dubbo
dubbo
2.7.3
3.3 @Activate
3.3.1 @Activate 源码示例 org.apache.dubbo.rpc.Filter
https://www.jianshu.com/p/f390bb88574d
关于激活的过滤器:
都需要在扩展类的配置文件中标识 过滤器名=xxx.xxx.xxx.xxxFilter
1.默认过滤器
>> 需要被@Activate标识
>> 如果需要在服务暴露时装载,那么group="provider"
>> 如果需要在服务引用的时候装载,那么group="consumer"
>> 如果想被暴露和引用时同时被装载,那么group={"consumer", "provider"}
>> 如果需要url中有某个特定的值才被加载,那么value={"token", "bb"}
那么就需要配置一个token, value数组与URL中的某一个属性相同就行了
2.普通自定义过滤器
>> 需要配置在url上 比如
过滤器扩展类上可以有@Activate也可以没有(自定义的就不要加了)
3.去掉某个过滤器
在filter属性上使用-号标识需要去掉的过滤器 比如:
registry://192.168.1.7:9090/org.apache.dubbo.service1?server.filter=-defalut,value1 去掉默认的,添加value1
registry://192.168.1.7:9090/org.apache.dubbo.service1?server.filter=value1,-value2 去掉value2,添加value1
dubbo filter官网
http://dubbo.apache.org/zh-cn/docs/dev/impls/filter.html
将dubbo中filter聚合的wrapper
org.apache.dubbo.rpc.protocol.ProtocolFilterWrapper
该类实现了程序启动时, 将所有filter搞成一个链表, 然后调用时候, 依次调用.
Dubbo 自定义一个 Filter

3.3.2 @Activate 源码分析
3.3.3 @Activate小demo


test
package com.zy.activate;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.extension.ExtensionLoader;
import org.junit.Test;
import java.util.List;
/**
* 参考链接
* https://www.jianshu.com/p/bc523348f519
*
* @Activate 适用场景
* 主要用在filter上,有的 filter 需要在 provider 边需要加的,有的需要在 consumer 边需要加的,
* 根据URL中的参数指定,当前的环境是 provider 还是 consumer,运行时决定哪些 filter 需要被引入执行。
*
*/
public class ActivateTest {
/**
* @Activate 注解中声明一个 group
*/
@Test
public void fn01() {
ExtensionLoader loader = ExtensionLoader.getExtensionLoader(IActivate.class);
URL url = URL.valueOf("activate://127.0.0.1/activate");
// 查询 group 为 default_group 的 IActivate 的实现
List list = loader.getActivateExtension(url, new String[]{}, "default_group");
list.forEach(e -> System.out.println(e.getClass()));
}
/**
* @Activate 注解中声明多个 group
*/
@Test
public void fn02() {
ExtensionLoader loader = ExtensionLoader.getExtensionLoader(IActivate.class);
URL url = URL.valueOf("activate://127.0.0.1/activate");
// 查询 group 为 group01 的 IActivate 的实现
List list = loader.getActivateExtension(url, new String[]{}, "group01");
list.forEach(e -> System.out.println(e.getClass()));
}
/**
* @Activate 注解中声明了 group 与 value
*/
@Test
public void fn03() {
ExtensionLoader loader = ExtensionLoader.getExtensionLoader(IActivate.class);
URL url = URL.valueOf("activate://127.0.0.1/activate");
// 根据 key = v1, group = value
// @Activate(value = {"v1"}, group = {"value_group"}) 来激活扩展
// com.zy.activate.ValueActivate
// 这里有个坑, url 被重新赋值了
url = url.addParameter("v1", "value_group");
// 查询 value 为 v1, group 为 value_group 的 IActivate 的实现
List list = loader.getActivateExtension(url, new String[]{}, "value_group");
list.forEach(e -> System.out.println(e.getClass()));
}
/**
* @Activate 注解中声明了 order, 低的排序优先级高
*/
@Test
public void fn04() {
ExtensionLoader loader = ExtensionLoader.getExtensionLoader(IActivate.class);
URL url = URL.valueOf("activate://127.0.0.1/activate");
List list = loader.getActivateExtension(url, new String[]{}, "group_by_order");
// 查询 group 为 group_by_order, 并且有 order 排序的 IActivate 的实现
list.forEach(e -> System.out.println(e.getClass()));
}
}
classpath下文件: com.zy.activate.IActivate
group=com.zy.activate.GroupActivate
order01=com.zy.activate.OrderActivate01
order02=com.zy.activate.OrderActivate02
value=com.zy.activate.ValueActivate
com.zy.activate.DefaultActivate
3.4 @Adaptive
自适应扩展点注解。
adaptive设计的目的是为了识别固定已知类和扩展未知类。
在实际应用场景中,一个扩展接口往往会有多种实现类,而Dubbo是基于URL驱动,
所以在运行时,通过传入URL中的某些参数来动态控制具体实现,这便是Dubbo的扩展点自适应特性。
URL来自于 ReferenceConfig, ConsumerConfig等各种config, 即yml或XML中的producer或consumer的各种配置.
在Dubbo中,@Adaptive一般用来修饰类和接口方法,在整个Dubbo框架中,
只有AdaptiveExtensionFactory和AdaptiveCompiler使用在类级别上,
其余都标注在方法上。
3.4.1 修饰方法级别
当扩展点的方法被@Adaptive修饰时,
在Dubbo初始化扩展点时会自动生成和编译一个动态的Adaptive类。
含有@Adaptive的方法中都可以根据方法参数动态获取各自需要真实的扩展点。
它主要是用于SPI,因为spi的类是不固定、未知的扩展类,所以设计了动态$Adaptive类;
ExtensionLoader.getAdaptiveExtension方法会返回动态编译生成的$Adaptive
例如:
Protocol的spi类有injvm、dubbo、registry、filter、listener等很多未知扩展类,
ExtensionLoader.getAdaptiveExtension会动态编译Protocol$Adaptive的类,
再通过在动态累的方法中调用ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(spi类);来提取对象。
以Protocol接口为例
package org.apache.dubbo.rpc;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.extension.Adaptive;
import org.apache.dubbo.common.extension.SPI;
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
Exporter export(Invoker invoker) throws RpcException;
@Adaptive
Invoker refer(Class type, URL url) throws RpcException;
void destroy();
}
export 和 refer 两个方法被 @Adaptive 注解修饰
Dubbo在初始化扩展点时(即provider或consumer向注册中心注册,会生成一个Protocol$Adaptive类,
该动态代理类会实现这两个方法,方法里会有一些抽象的通用逻辑,
根据解析URL得到的信息,找到并调用真正的实现类。
生成的代码如下:
package org.apache.dubbo.rpc;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class Protocol$Adaptive implements org.apache.dubbo.rpc.Protocol {
public void destroy() {
throw new UnsupportedOperationException("The method public abstract void org.apache.dubbo.rpc.Protocol.destroy() of interface org.apache.dubbo.rpc.Protocol is not adaptive method!");
}
public int getDefaultPort() {
throw new UnsupportedOperationException("The method public abstract int org.apache.dubbo.rpc.Protocol.getDefaultPort() of interface org.apache.dubbo.rpc.Protocol is not adaptive method!");
}
public org.apache.dubbo.rpc.Exporter export(org.apache.dubbo.rpc.Invoker arg0) throws org.apache.dubbo.rpc.RpcException {
if (arg0 == null)
throw new IllegalArgumentException("org.apache.dubbo.rpc.Invoker argument == null");
if (arg0.getUrl() == null)
throw new IllegalArgumentException("org.apache.dubbo.rpc.Invoker argument getUrl() == null");
org.apache.dubbo.common.URL url = arg0.getUrl();
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null)
throw new IllegalStateException("Failed to get extension (org.apache.dubbo.rpc.Protocol) name from url (" + url.toString() + ") use keys([protocol])");
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol)ExtensionLoader.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.export(arg0);
}
public org.apache.dubbo.rpc.Invoker refer(java.lang.Class arg0, org.apache.dubbo.common.URL arg1) throws org.apache.dubbo.rpc.RpcException {
if (arg1 == null)
throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg1;
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null)
throw new IllegalStateException("Failed to get extension (org.apache.dubbo.rpc.Protocol) name from url (" + url.toString() + ") use keys([protocol])");
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol)ExtensionLoader.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
}
}
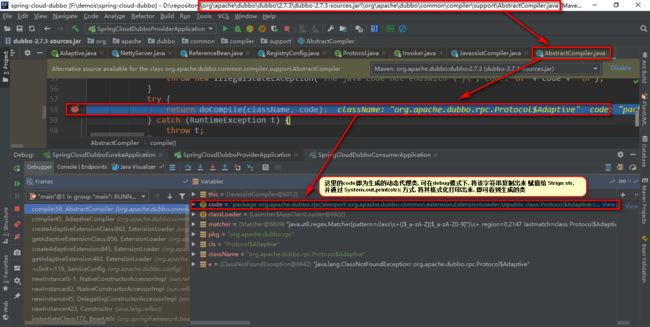
解释下上述生成的export(org.apache.dubbo.rpc.Invoker arg0)方法
1.String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
从arg0中解析出扩展点名称extName,extName的默认值为@SPI的value。
这是adaptive的精髓:每一个方法都可以根据方法参数动态获取各自需要的扩展点。
2.Protocol extension = (Protocol)ExtensionLoader.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
根据extName重新获取指定的Protocol.class扩展点。
如果所有扩展点中含有Wrapper(listener,fiter)则ExtensionLoader.getExtension()
会将真正的实现类通过 Wrapper(listener,fiter)包装后返回。
如
>> ProtocolListenerWrapper
>> ProtocolFilterWrapper
>> QosProtocolWrapper
>> StubProxyFactoryWrapper
3.extension.export(arg0)
执行目标类的目标方法
3.4.2 修饰类级别
以AdaptiveCompiler类为例,它作为Compiler扩展点的实现类,被@Adaptive在类级别修饰。
在类所在工程的resource/META-INF/dubbo/internal路径下可以找到扩展点配置文件:
org.apache.dubbo.common.compiler.Compiler
这样在Dubbo加载扩展点时便可以根据adaptive属性找到AdaptiveComiler实现类,
再通过compiler方法决定是调用默认实现,还是指定的实现,默认实现由扩展点接口上的@SPI注解指定。
此处:
@SPI("javassist")
public interface Compiler { ... }
对比方法级别,类级别省略了生成动态代理类的过程,由指定类决定具体实现,
另外对于同一个扩展点,类级别的Adaptive只能有一个。
// 1. 为什么AdaptiveCompiler这个类是固定已知的?
因为整个框架仅支持Javassist和JdkCompiler;
// 2. 为什么AdaptiveExtensionFactory这个类是固定已知的?
因为整个框架仅支持2个objFactory,一个是spi,另一个是spring;
ExtensionLoader.getAdaptiveExtension方法会直接返回这个类的实例
4.Spring中的SPI机制
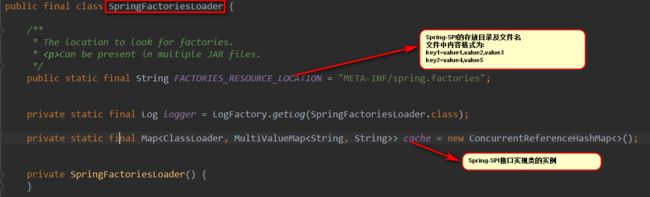
关于何时加载classpath下的spring.factories文件, 参考下文
https://www.jianshu.com/p/5d5890645165
参考资源
https://www.jianshu.com/p/08b41189eb4c (dubbo-spi)
https://www.jianshu.com/p/0d196ad23915 (spring-spi)
https://www.cnblogs.com/leeego-123/p/10906674.html
https://blog.csdn.net/vbirdbest/article/details/79863883
https://www.jianshu.com/p/bc523348f519 (@Activate扩展)
https://www.cnblogs.com/qiaozhuangshi/p/11007032.html (@Activate扩展)
https://www.jianshu.com/p/7e116f480165 (@Activate扩展示例)
https://blog.csdn.net/qq_30051265/article/details/82776395 (Dubbo 中的 filter)
https://blog.csdn.net/u011212394/article/details/102762197 (@Adaptiv)