Pod是kubernets最基本的调度单元
前面我们已经了解了kubernetes的基本架构,以及如何使用资源清单在集群中部署一个应用。我们也了解到了Pod是k8s集群中最基本的调度单元,我们平时在集群中部署的应用都是以Pod为单位的,而并不是我们熟知的容器,这样设计的目的是什么呢?为什么不直接使用容器呢?
为什么需要Pod
假设k8s中调度的基本单元就是容器,对于一个非常简单的应用可以直接被调度使用,没什么问题,但是往往还有很多应用程序是由多个进程组成的,有的人可能会说把这些进程都打包到一个容器不就可以了吗?理论上是可以实现的,但是不要忘记了Docker管理的进程是pid=1的主进程,其他进程死掉了就会成为僵尸进程,没办法进行管理了,这种方式本身也不是容器推荐的运行方式,一个容器最好只干一件事情,所以在真实的环境中不会使用这种方式。
那么我们就把这个应用的进程进行拆分,拆分成一个一个的容器总可以了吧?但是不要忘记一个问题,拆分成一个一个的容器后,是不是就有可能出现一个应用下面的某个进程容器被调度到了不同的节点上啊?往往我们应用内部的进程与进程间通信(通过IPC或者共享本地文件之类的)都是要求在本地进行的,也就是需要在同一个节点上运行。
问题:进程与进程之间也可以跨主机通信,然后只要找到进程对应的主机IP地址或者域名,那这样的话我们就解决了进程容器被调度到了不同的节点上的问题。但是前提是我们这个进程容器被调度到的节点是固定的或者说是可以获取到进程容器所在节点列表。至于这个前提能不能实现,目前我个人不知,后面的学习中会慢慢了解更多,最后再回过头来看待此问题。
所以我们需要一个更高级别的结构来将这些容器绑定在一起,并将它们作为一个基本的调度单元进行管理,这样就可以保证这些容器始终在同一个节点上面,这也就是Pod设计的初衷。
Pod原理
在一个Pod下面运行几个关系非常密切的容器进程,这样一来这些进程本身又可以受到容器的管控,又具有几乎一致的运行环境,也就完美解决了上面提到的问题。
其实Pod也只是一个逻辑概念,真正起作用的还是Linux容器的Namespace和Cgroup这两个最基本的概念,Pod被创建出来其实是一组共享了一些资源的容器而已。首先Pod里面的所有容器,都是共享的同一个Network Namespace,但是涉及到文件系统的时候,默认情况下Pod里面的容器之间的文件系统是完全隔离的,但是我们可以通过声明来共享同一个Volume。
对于共享同一个Network Namespace这个概念是不是比较熟悉,我们之前在Docker网络模式的章节讲解了网络的Container模式,我们可以指定新创建的容器和一个已经存在的容器共享一个Network Namespace,在运行容器的时候只需要指定--net=container:目标容器名这个参数就可以了,但是这种模式有一个明显的问题那就是容器的启动先后顺序问题,那么Pod是怎么来处理这个问题的呢?那就是加入一个中间容器,这个容器叫做Infra容器,而且这个容器在Pod中永远都是第一个被创建的容器,这样其他容器都加到这个Infra容器就可以了,这样就完全实现了Pod 中的所有容器都和Infra容器共享同一个Network Namespace了,如下图所示:
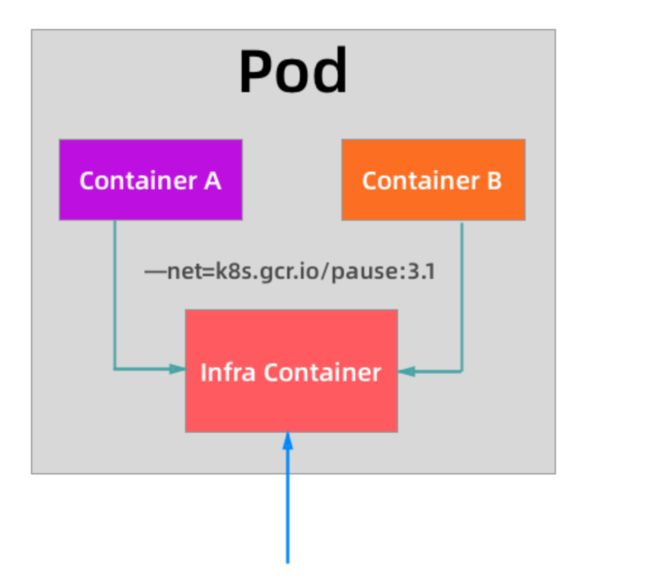
所以当我们部署完成k8s集群的时候,首先需要保证在所有节点上可以垃取到默认的Infra镜像,默认情况下Infra镜像地址为k8s.gcr.io/pause:3.1,这个容器占用的资源非常少,但是这个镜像默认是需要科学上网的,所以很多时候我们在部署应用的时候一直处于Pending状态,因为所有Pod最先启动的容器惊喜都拉不下来,肯定启动不了,启动不了其他容器肯定也就不能启动了:
[root@master ~]# kubelet --help |grep infra
--pod-infra-container-image string The image whose network/ipc namespaces containers in each pod will use. This docker-specific flag only works when container-runtime is set to docker. (default "k8s.gcr.io/pause:3.1")
从上面图中我们可以看出普通的容器加入到了 Infra 容器的 Network Namespace 中,所以这个 Pod 下面的所有容器就是共享同一个 Network Namespace 了,普通容器不会创建自己的网卡,配置自己的 IP,而是和 Infra 容器共享 IP、端口范围等,而且容器之间的进程可以通过 lo 网卡设备进行通信:
- 也就是容器之间是可以直接使用 localhost 进行通信的;
- 看到的网络设备信息都是和 Infra 容器完全一样的;
- 也就意味着同一个 Pod 下面的容器运行的多个进程不能绑定相同的端口;
- 而且 Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
对于文件系统k8s是怎么实现让一个Pod中的容器共享的呢?在Pod中,默认情况下容器的文件系统是互相隔离的,要实现共享只需要在Pod的顶层声明一个Volume,然后在需要共享这个Volume的容器中声明挂载即可。
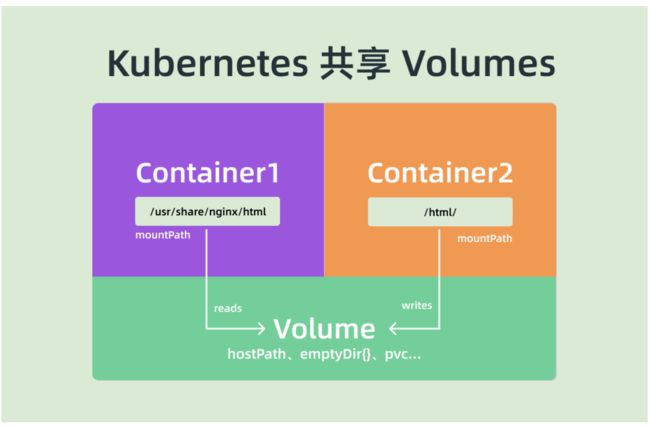
比如下面的示例:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
volumes:
- name: varlog
hostPath:
path: /var/log/counter
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
在示例中我们在Pod的顶层声明了一个名为varlog的Volume,而这个Volume的类型是hostPath,也就意味着这个宿主机的/var/log/counter目录将被这个Pod共享,共享给谁呢?在需要用到这个数据目录的容器上声明挂载即可,也就是通过volumeMounts声明挂载的部分,这样我们这个Pod就实现了共享容器的/var/log目录,而且数据被持久化到了宿主机目录上。
这个方式也是k8s中一个非常重要的设计模式:sidecar模式的常用方式。典型的场景就是容器日志收集,比如上面我们的这个应用,其中应用的日志被输出到容器的/var/log目录上的,这个时候我们可以把Pod声明的Volume挂载到容器的/var/log目录上,然后在这个Pod里面同时运行一个sidecar容器,他也声明挂载相同的Volume到自己的容器的/var/log(或其他)目录上,这样我们这个sidecar容器就只需要从/var/log目录下面不断消费日志发送到Elasticsearch中存储起来就完成了最基本的应用日志的基本收集工作了。
除了这个应用场景之外使用更多的还是利用 Pod 中的所有容器共享同一个 Network Namespace 这个特性,这样我们就可以把 Pod 网络相关的配置和管理也可以交给一个 sidecar 容器来完成,完全不需要去干涉用户容器,这个特性在现在非常火热的 Service Mesh(服务网格)中应用非常广泛,典型的应用就是 Istio。
如何划分 Pod
上面我们介绍了 Pod 的实现原理,了解到了应该把关系紧密的容器划分到同一个 Pod 中运行,那么怎么来区分“关系紧密”呢?举一个简单的示例,比如我们的 Wordpress 应用,是一个典型的前端服务器和后端数据服务的应用,那么你认为应该使用一个 Pod 还是两个 Pod 呢?
如果在同一个 Pod 中同时运行服务器程序和后端的数据库服务这两个容器,理论上肯定是可行的,但是不推荐这样使用,我们知道一个 Pod 中的所有容器都是同一个整体进行调度的,但是对于我们这个应用 Wordpress 和 MySQL 数据库一定需要运行在一起吗?当然不需要,我们甚至可以将 MySQL 部署到集群之外对吧?所以 Wordpress 和 MySQL 即使不运行在同一个节点上也是可行的,只要能够访问到即可。
但是如果你非要强行部署到同一个 Pod 中呢?从某个角度来说是错误的,比如现在我们的应用访问量非常大,一个 Pod 已经满足不了我们的需求了,怎么办呢?扩容对吧,但是扩容的目标也是 Pod,并不是容器,比如我们再添加一个 Pod,这个时候我们就有两个 Wordpress 的应用和两个 MySQL 数据库了,而且这两个 Pod 之间的数据是互相独立的,因为 MySQL 数据库并不是简单的增加副本就可以共享数据了,所以这个时候就得分开部署了,采用第二种方案,这个时候我们只需要单独扩容 Wordpress 的这个 Pod,后端的 MySQL 数据库并不会受到扩容的影响。
将多个容器部署到同一个 Pod 中的最主要参考就是应用可能由一个主进程和一个或多个的辅助进程组成,比如上面我们的日志收集的 Pod,需要其他的 sidecar 容器来支持日志的采集。所以当我们判断是否需要在 Pod 中使用多个容器的时候,我们可以按照如下的几个方式来判断:
这些容器是否一定需要一起运行,是否可以运行在不同的节点上
这些容器是一个整体还是独立的组件
这些容器一起进行扩缩容会影响应用吗
基本上我们能够回答上面的几个问题就能够判断是否需要在 Pod 中运行多个容器了。
Pod生命周期
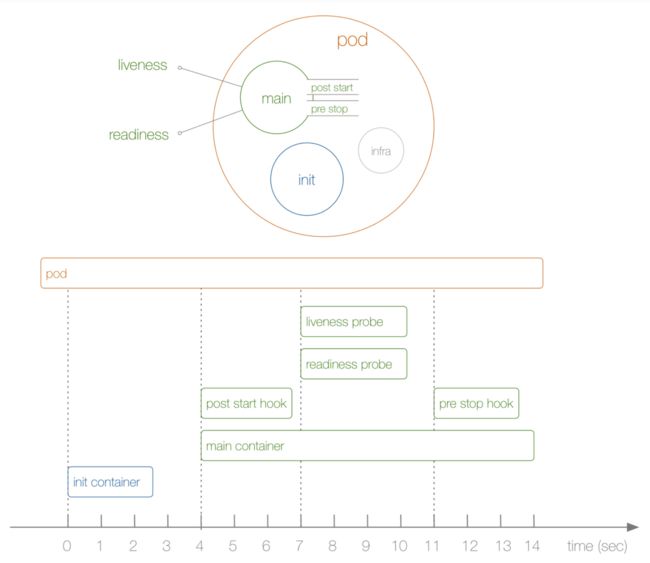
上图展示了一个Pod的完整生命周期,其中包含Init Container、Pod Hook、健康检查 三个主要部分,接下来分别介绍影响Pod生命周期的部分:
首先在介绍Pod的生命周期之前,我们先了解下Pod的状态,因为Pod的状态可以反映出当前我们的Pod的具体状态信息,也是我们分析排错的一个必备方式。
Pod 状态
Pod状态值,我们可以通过kubectl explain pod.status命令来了解关于Pod状态的一些信息,Pod的状态定义在PodStatus对象中,其中一个phase字段,下面是phase的可能取值。
- 挂起(Pending): Pod信息已经提交给了集群,但是还没有被调度器调度到合适的节点或者Pod里的镜像正在下载。
- 运行中(Running): 该Pod已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 成功(Succeeded): Pod中的所有容器都被成功终止,并且不会再重启
- 失败(Failed): Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非
0状态退出或者被系统终止。 - 未知(Unknown): 因为某些原因无法取得Pod的状态,通常是因为与Pod所在主机通信失败导致的。
除此之外,PodStatus对象还包含一个PodCondition的数组,里面包含的属性有:
- lastProbeTime: 最后一次探测Pod Condition的时间戳
- lastTransitionTime: 上次Condition从一种状态转换到另一种状态的时间
- message: 上次Condition状态转换的详细描述
- reason: Condition最后一次转换的原因
- status: Condition状态类型,可以为"True","False",and "Unknown"
- type: Condition类型,包括以下方面:
- PodScheduled(Pod已经被调度到其他node里)
- Ready(Pod能够提供服务请求,可以被添加到所有可匹配服务的负载均衡池中)
- Initialized(所有的
init containers已经启动成功) - Unschedulable(调度程序现在无法调度Pod,例如由于缺乏资源或其他限制)
- ContainersReady(Pod里的所有容器都是ready状态)
重启策略
我们可以通过配置restartPolicy字段来设置Pod中所有容器的重启策略,其可能为Always,OnFailure和Never,默认值为Always。restartPolicy仅指通过kubelet在同一节点上重新启动容器。通过kubelet重新启动的退出容器将以指数增加延迟(10s,20s,40s...)重新启动,上限为5分钟,并在成功执行10分钟后重置。不同类型的控制器可以控制Pod的重启策略:
- Job: 适用于一次性任务,如批量计算,任务结束后Pod会被此类控制器清除。Job的重启策略只能是
OnFailure或者Never。 - Replication Controller,ReplicaSet,or Deployment,此类控制器希望Pod一直运行下去,它们的重启策略只能是
Always。 - DaemonSet:每个节点上启动一个Pod,很明显此类控制器的重启策略也应该是
Always。
初始化容器
了解了Pod状态后,首先来了解下Pod中最新启动的Init Container,也就是我们平时常说的初始化容器。Init Container就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行。我们知道一个Pod里面的所有容器是共享数据卷和Network Namespace的,所以Init Container里面产生的数据可以被主容器使用到。从上面的Pod生命周期的图中可以看出初始化容器是独立于主容器之外的,只有所有的初始化容器执行完之后,主容器才会被启动。那么初始化容器有哪些应用场景呢?
- 等待其他模块 Ready:这个可以用来解决服务之间的依赖问题,比如我们有一个 Web 服务,该服务又依赖于另外一个数据库服务,但是在我们启动这个 Web 服务的时候我们并不能保证依赖的这个数据库服务就已经启动起来了,所以可能会出现一段时间内 Web 服务连接数据库异常。要解决这个问题的话我们就可以在 Web 服务的 Pod 中使用一个 InitContainer,在这个初始化容器中去检查数据库是否已经准备好了,准备好了过后初始化容器就结束退出,然后我们主容器的 Web 服务才被启动起来,这个时候去连接数据库就不会有问题了。
- 做初始化配置:比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。
- 其它场景:如将 Pod 注册到一个中央数据库、配置中心等。
比如现在我们来实现一个功能,在Nginx Pod启动之前去重新初始化首页内容,如下所示的资源清单:(init-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: init-demo
spec: # Pod规格清单
volumes:
- name: workdir # volume的名字,必须要有
hostPath:
path: /tmp/1 # volume在宿主机的路径
initContainers: # 初始化的容器
- name: initcontainers # 初始化的容器的名字
image: busybox
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://www.baidu.com
volumeMounts: # 要挂载到初始化的容器的volume
- name: workdir # volume的名字,和宿主机的volume必须一致
mountPath: "/work-dir" # 挂载到初始化的容器的哪个路径下
containers: # 主容器
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
上面的资源清单中我们首先在Pod顶层声明了一个名为workdir的Volume,然后使用hostPath指明宿主机路径。
然后我们定义了一个初始化容器,该容器会下载一个html文件到/work-dir目录下面,但是由于我们又将该目录声明挂载到了全局的Volume,同样主容器的nginx也将目录/usr/share/nginx/html声明挂载到了全局的Volume,所以在主容器的该目录下面会同步初始化容器中创建的index.html文件。
如下创建Pod
[root@master my_kubernets_yaml]# kubectl apply -f init-pod.yaml
pod/init-demo created
[root@master my_kubernets_yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-demo 0/1 Init:0/1 0 5s
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 45h
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 45h
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 45h
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 45h
[root@master my_kubernets_yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-demo 0/1 PodInitializing 0 9s
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 45h
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 45h
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 45h
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 45h
[root@master my_kubernets_yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-demo 1/1 Running 0 17s
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 45h
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 45h
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 45h
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 45h
然后验证http://www.baidu.com首页是否已经覆盖了主容器的首页
[root@master my_kubernets_yaml]# kubectl describe pod init-demo
Name: init-demo
Namespace: default
Priority: 0
Node: node01/172.17.122.151
Start Time: Fri, 17 Jan 2020 15:37:33 +0800
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"init-demo","namespace":"default"},"spec":{"containers":[{"image":"ngi...
Status: Running
IP: 10.244.1.11 "# Pod的IP地址"
IPs:
IP: 10.244.1.11
Init Containers:
initcontainers:
Container ID: docker://60857d6ee5855d4671aff60b44180544a96da8910a2435ef56ca72827cbcec04
Image: busybox
Image ID: docker-pullable://busybox@sha256:6915be4043561d64e0ab0f8f098dc2ac48e077fe23f488ac24b665166898115a
Port:
Host Port:
Command:
wget
-O
/work-dir/index.html
http://www.baidu.com
State: Terminated
Reason: Completed
Exit Code: 0
Started: Fri, 17 Jan 2020 15:37:40 +0800
Finished: Fri, 17 Jan 2020 15:37:40 +0800
Ready: True
Restart Count: 0
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-557h9 (ro)
/work-dir from workdir (rw)
Containers:
nginx:
Container ID: docker://c54bf4ad5e58a6b5e782fb4b4b56c50a09a1f9c7b50a67f617e8a52e9ee60ccd
Image: nginx
Image ID: docker-pullable://nginx@sha256:8aa7f6a9585d908a63e5e418dc5d14ae7467d2e36e1ab4f0d8f9d059a3d071ce
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Fri, 17 Jan 2020 15:37:48 +0800
Ready: True
Restart Count: 0
Environment:
Mounts:
/usr/share/nginx/html from workdir (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-557h9 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
workdir:
Type: HostPath (bare host directory volume)
Path: /tmp/1
HostPathType:
default-token-557h9:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-557h9
Optional: false
QoS Class: BestEffort
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled default-scheduler Successfully assigned default/init-demo to node01
Normal Pulling 2m6s kubelet, node01 Pulling image "busybox"
Normal Pulled 119s kubelet, node01 Successfully pulled image "busybox"
Normal Created 119s kubelet, node01 Created container initcontainers
Normal Started 119s kubelet, node01 Started container initcontainers
Normal Pulling 118s kubelet, node01 Pulling image "nginx"
Normal Pulled 111s kubelet, node01 Successfully pulled image "nginx"
Normal Created 111s kubelet, node01 Created container nginx
Normal Started 111s kubelet, node01 Started container nginx
[root@master my_kubernets_yaml]#
[root@master my_kubernets_yaml]# curl http://10.244.1.11 "# 能够看到百度首页内容"
百度一下,你就知道

然后我们再在宿主机上查看index.html文件。
注意:先查看Pod运行在哪台宿主机上
[root@master tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
init-demo 1/1 Running 0 14m 10.244.1.11 node01
然后到node01节点上查看/tmp/1目录,如下:
[root@node01 1]# pwd
/tmp/1
[root@node01 1]# ls -lh
total 4.0K
-rw-r--r-- 1 root root 2.4K Jan 17 15:37 index.html
Pod Hook
我们知道Pod是k8s集群中的最小单元,而Pod是由容器组成的,所以在讨论Pod的生命周期的时候我们可以先来讨论下容器的生命周期。实际上k8s为我们的容器提供了生命周期的钩子,就是我们说的Pod Hook,Pod Hook是由kubelet发起的,当容器中的进程启动前或者容器的进程终止之前运行,这是包含在容器的生命周期之中。我们可以同时为Pod 中的所有容器都配置hook。
k8s为我们提供了两种钩子函数:
-
PostStart:这个钩子在容器创建后立即执行。但是,并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费太长的时间以至于不能运行或者挂起,容器将不能达到running状态。
-PreStop: 这个钩子在容器终止之前立即被调用。它是阻塞的,意味着它是同步的,所以必须在删除容器的调用发出之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起,Pod阶段将停留在running状态并且永不会达到failed状态。
如果PostStart或者PreStop钩子失败,它会杀死容器。所以我们应该让钩子函数尽可能的轻量。当然有些情况下,长时间运行命令是合理的,比如在停止容器之前预先保存状态。
另外我们有两种方式来实现上面的钩子函数:
-
Exec: 用于执行一段特定的命令,不过要注意的是该命令消耗的资源会被计入容器。 -
HTTP: 对容器上的特定的端点执行HTTP请求。
以下示例中,定义了一个Nginx Pod,其中设置了PostStart钩子函数,即在容器创建成功后,写入一句话道/usr/share/message文件中:(pod-poststart.yaml)
apiVersion: v1
kind: Pod
metadata:
name: hook-demo1
spec:
containers:
- name: hook-demo1
image: nginx
lifecycle: # 管理系统将对容器采取的措施,在生命周期开始后或结束结束前
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
直接创建上面的Pod:
[root@master my_kubernets_yaml]# kubectl apply -f pod-poststart.yaml
pod/hook-demo1 created
[root@master my_kubernets_yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
hook-demo1 0/1 ContainerCreating 0 8s
init-demo 1/1 Running 0 58m
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 46h
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 46h
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 46h
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 46h
[root@master my_kubernets_yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
hook-demo1 1/1 Running 0 17s
init-demo 1/1 Running 0 59m
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 46h
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 46h
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 46h
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 46h
创建成功后我们可以到容器中/usr/share/message文件查看内容是否存在
[root@master my_kubernets_yaml]# kubectl exec -ti hook-demo1 cat /usr/share/message
Hello from the postStart handler
当用户请求删除含有Pod的资源对象时(如Deployment等),k8s为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),k8s提供了两种信息通知:
- 默认:k8s通知node执行
docker stop命令,docker会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送SIGKILL的系统信号强制执行kill命令,强行kill掉进程。 - 使用Pod生命周期(利用
PreStop回调函数),它在发送终止信号之前执行。
默认所有的优雅退出时间都在30秒内。kubectl delete 命令支持--grace-period=选项,这个选项允许用户用他们自己指定的值覆盖默认值。值'0'代表强制删除 pod。 在 kubectl 1.5 及以上的版本里,执行强制删除时必须同时指定--force --grace-period=0。
强制删除一个Pod是从集群状态还有etcd里立刻删除这个Pod,只是当Pod被强制删除时,APIServer不会等待来自Pod所在节点上kubelet的确认消息:Pod已经被终止。在API里Pod会被立刻删除,在节点上,pods被设置成立刻终止后,在强行杀掉前还会有一个很小的宽限期。
以下示例中,定义了一个Nginx Pod,其中设置了PreStop钩子函数,即在容器退出之前,优雅的关闭Nginx:(pod-prestop.yaml)
apiVersion: v1
kind: Pod
metadata:
name: hook-demo2
spec:
containers:
- name: hook-demo2
image: nginx
lifecycle:
preStop:
exec:
command: ["/usr/sbin/nginx", "-s", "quit"] # 优雅退出
---
apiVersion: v1
kind: Pod
metadata:
name: hook-demo3
spec:
volumes:
- name: message
hostPath:
path: /tmp/2
containers:
- name: hook-demo3
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: message
mountPath: /usr/share
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from preStop Handler > /usr/share/message; ls -l /usr/share/ >> /usr/share/message"] # 执行了2条命令
上面定义的两个Pod,一个是利用preStop来进行优雅删除,另外一个是利用preStop来做一些信息记录的事情,同样直接创建上面的Pod:
[root@master my_kubernets_yaml]# kubectl apply -f pod-prestop.yaml
pod/hook-demo2 created
pod/hook-demo3 created
[root@master my_kubernets_yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hook-demo1 1/1 Running 0 113m 10.244.2.11 node02
hook-demo2 1/1 Running 0 7s 10.244.2.25 node02
hook-demo3 0/1 ContainerCreating 0 7s node01
init-demo 1/1 Running 0 172m 10.244.1.11 node01
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 2d 10.244.1.8 node01
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 2d 10.244.2.8 node02
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 2d 10.244.1.6 node01
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 2d 10.244.2.7 node02
[root@master my_kubernets_yaml]#
[root@master my_kubernets_yaml]#
[root@master my_kubernets_yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hook-demo1 1/1 Running 0 113m 10.244.2.11 node02
hook-demo2 1/1 Running 0 27s 10.244.2.25 node02
hook-demo3 1/1 Running 0 27s 10.244.1.19 node01
init-demo 1/1 Running 0 172m 10.244.1.11 node01
nginx-deploy-745bd74b44-4k2np 1/1 Running 0 2d 10.244.1.8 node01
nginx-deploy-745bd74b44-jr7wv 1/1 Running 0 2d 10.244.2.8 node02
nginx-deploy-745bd74b44-ngkrg 1/1 Running 0 2d 10.244.1.6 node01
nginx-deploy-745bd74b44-plgkw 1/1 Running 0 2d 10.244.2.7 node02
然后执行删除容器,必须使用kubectl delete -f pod-prestop.yaml的方式删除容器才会执行preStop里的命令
查看/tmp/2目录下的message文件内容:(一定要到Pod被调度到的目标节点上查看)
[root@node01 2]# cat message
Hello from preStop Handler
total 4
-rw-r--r-- 1 root root 27 Jan 17 10:33 message
另外 Hook 调用的日志没有暴露个给 Pod,所以只能通过describe命令来获取,如果有错误将可以看到 FailedPostStartHook或 FailedPreStopHook 这样的 event。