补充昨日知识
昨天学习了条形图的绘制,今天学习折线图,饼图,散点图的绘制
绘制折线图
- 绘制折线图(1)
# 绘制正弦曲线
# [0,2Π]p闭区间等间距100个点
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = np.linspace(0,2*np.pi,num = 100)
print(x) #输出[0,2Π]之间的100个点
siny = np.sin(x) #sin曲线
cosy = np.cos(x) #cos曲线
plt.xlabel('时间(s)')
plt.ylabel('电压(v)')
plt.title('正弦曲线')
plt.plot(x,siny,color='g',label='sin(x)')
plt.plot(x,cosy,color='r',label='cos(x)')
plt.legend()
plt.show()
绘制图如下所示:
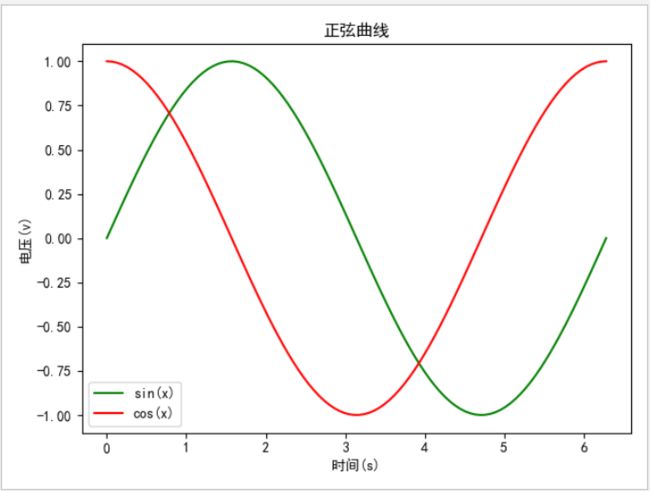
正弦曲线
- 绘制折线图(2)
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = np.linspace(0,2*np.pi,num = 100)
print(x)
siny = np.sin(x)
cosy = np.cos(x)
plt.xlabel('时间(s)')
plt.ylabel('电压(v)')
plt.title('正弦曲线')
plt.plot(x,siny,color='g',linestyle='--',marker='+',label='sin(x)')
#可以改变曲线颜色,状态,等等
plt.plot(x,cosy,color='r',label='cos(x)')
plt.legend()
plt.show()
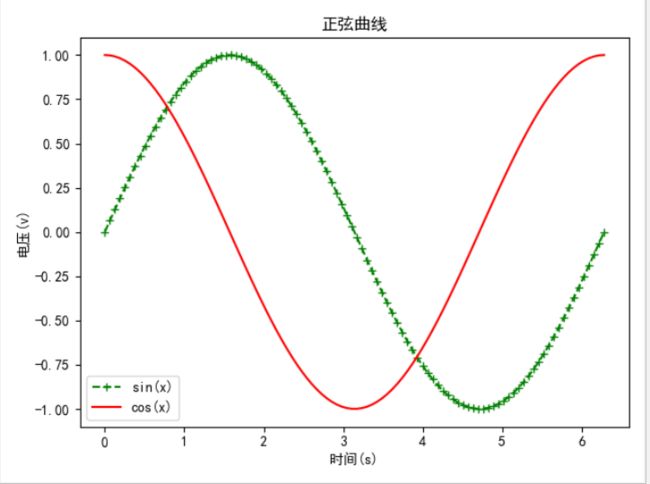
正弦曲线
绘制饼状图
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from random import randint
import string
counts = [randint(3500,10000)for i in range(5)] #在[3500,10000]中随机数
print(counts) #输出员工工资
labels = ['员工{}'.format(i) for i in string.ascii_uppercase[:5]]
print(labels) #输出员工名字
explode = [0.1,0,0,0,0]
colors = ['red','yellow','green','purple','orange']
plt.pie(counts,labels=labels,explode=explode,shadow=True,
colors=colors,autopct='%1.1f%%') #autopct指定百分比
plt.legend(loc = 2)
plt.title('员工工资占比图')
plt.show()
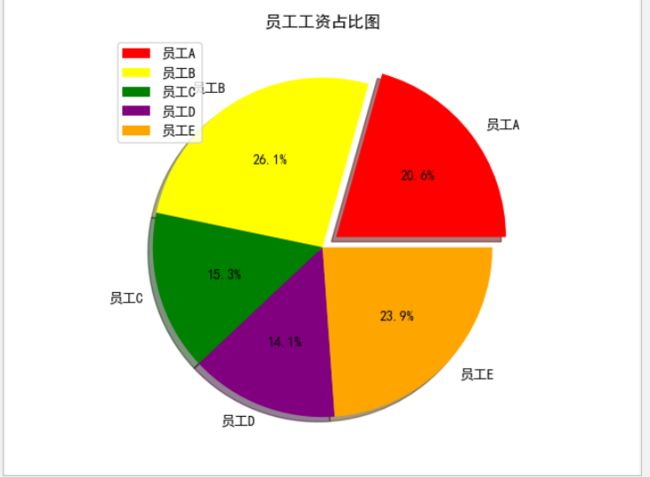
员工工资占比图
绘制散点图
import numpy as np
from matplotlib import pyplot as plt
from random import randint
import string
x = np.random.normal(0,1,100) #100表示点数
y = np.random.normal(0,1,100)
plt.scatter(x,y,alpha=1) #透明度
plt.show()
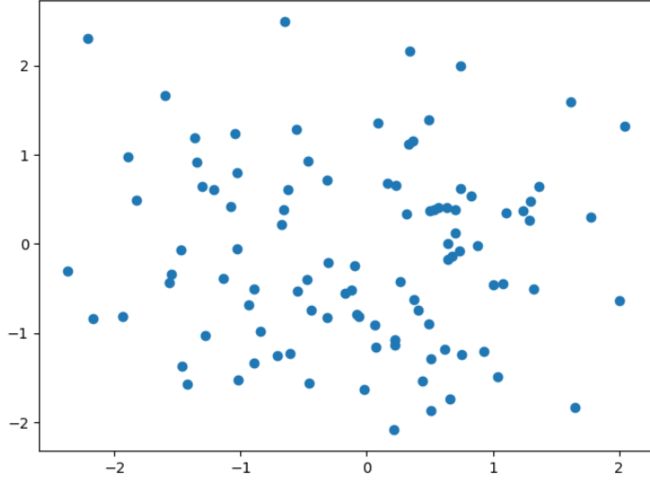
散点图
字典解析和集合解析
它和列表推导式很像
from random import randint
stu_grade = {'student{}'.format(i):randint(50,100) for i in range(1,101)} #定义100名学生,在[50,100]之间随机数匹配
for k,v in stu_grade.items():
print(k,v) #输出一百名学生的成绩
# 筛选出及格的学生
res_dict = {k:v for k,v in stu_grade.items() if v>60}
for k,v in res_dict.items():
print(k,v) #输出及格的学生
#集合解析
set1 = {randint(50,100) for i in range(1,101)}
print(set1) #将成绩提取形成字典
#筛选能被三整除的
res = {x for x in set1 if x%3==0}
for x in res:
print(x)#输出能被三整除的数
爬虫知识预热
首先我们学习一下html,超文本标记语言
html
新建html文件,html文件中都是成对出现的语句。
Title
欢迎来到王者荣耀
- 猪八戒
- 虞姬
- 典韦
- 曹操
- 吕布
- 安琪拉
- 加入图片
选择好图片进行添加
 上官婉儿
上官婉儿
- 加入文字和网址
上官婉儿选择一个点,然后以自己的位置为终点进行书写,
落笔的一瞬间对触碰的敌人造成150/180/210/240/270/300(+20%法术加成)
点法术伤害,书写过程中将会对触碰敌人造成300/360/420/480/540/600(+40%法术加成)
点法术伤害和50%减速持续2秒(每12秒储存一次笔势,最多可储备2次)
点击跳转至百度
豆瓣top25爬虫
import requests
from lxml import etree
def parse():
'''豆瓣网top250爬虫'''
# #1.获取url地址
for i in range(0,226,25):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
print(url)
#获取byte的类型的响应
requests.get(url).content
resp =requests.get(url)
data = resp.content
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
url = 'https://movie.douban.com/top250?start={}&filter='
#获取byte的类型的响应
resp = requests.get(url, headers=headers)
data = resp.content
# 调用etree.HTML获取html对象,然后调用html的xpath语法
html = etree.HTML(data)
movie_list = html.xpath('//div[@id="content"]//ol/li')
print(len(movie_list))
for movie in movie_list:
# 获取电影序号
serial_number = movie.xpath('./div[@class="item"]/div[@class="pic"]/em/text()')
serial_number = '' if len(serial_number) == 0 else serial_number[0]
print(serial_number)
#获取电影名
movie_name = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="hd"]/a/span[1]/text()')
movie_name = '' if len(movie_name) == 0 else movie_name[0]
print(movie_name)
#获取电影介绍
introduce = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/p/text()')
introduce = '' if len(introduce) == 0 else introduce[0]
print(introduce)
#获取电影星级
star = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[2]/text()')
star = '' if len(star) == 0 else star[0]
print(star)
#获取电影评价
evalute = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[4]/text()')
evalute = '' if len(evalute) == 0 else evalute[0]
print(evalute)
#获取电影描述
describe = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/p/span/text()')
describe = '' if len(describe) == 0 else describe[0]
print(describe)