目标
爬取无聊图板块下所有图片和gif
难点
以前煎蛋网是没有难度的,数据都明文写在网页源码里,但是因为爬的人太多,所以做了一些反爬措施,主要是将真实的图片地址用Base64加密了。也希望观看这篇文章的人设计友好爬虫,不要给网站增加太多负担。
做法
一:从网页源码中找到数据位置
我用的是Chrome浏览器,打开网页后按下F12进入开发者工具,在网页中找到你想要的数据,然后通过开发者工具左上角的箭头中的来选中

二:从网页源码中获取有效信息
获取网页源码可以通过python的requests库或者urllib,甚至你可以用aiohttp来实现异步获取提高性能,这里我用的是requests。
url = 'http://jandan.net/pic'
print(requests.get(url).text)
通过打印得到的源码可以看到应该出现图片地址的地方变成了
![]() Ly93eDIuc2luYWltZy5jbi9tdzY5MC8wMDcydnZIQ2d5MWZ0MW80NXhwMDBnMzBhOTA1a3UxYS5naWY=
Ly93eDIuc2luYWltZy5jbi9tdzY5MC8wMDcydnZIQ2d5MWZ0MW80NXhwMDBnMzBhOTA1a3UxYS5naWY=
这里煎蛋对图片地址做了加密,如果你熟悉Base64的话,看到
img-hash你就可以合理的猜测是对地址用了Base64编码。
三:解决网址加密问题
从源码的onload="jandan_load_img(this)"入手,全局查找jandan_load_img函数,发现函数长这样:
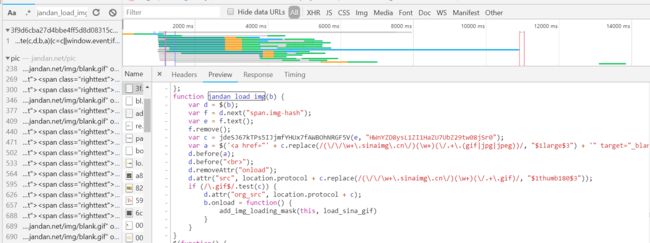
可以发现关键的地方在于
var c = jdeSJ67kTPs5IJjmfYHUx7fAWBOhNRGF5V(e, "HWnYZD8ysL1ZI1HaZU7UbZ29tw08jSr0");
继续全局找这个函数:
var jdeSJ67kTPs5IJjmfYHUx7fAWBOhNRGF5V = function(o, y, g) {
var d = o;
var l = "DECODE";
var y = y ? y : "";
var g = g ? g : 0;
var h = 4;
y = md5(y);
var x = md5(y.substr(0, 16));
var v = md5(y.substr(16, 16));
if (h) {
if (l == "DECODE") {
var b = md5(microtime());
var e = b.length - h;
var u = b.substr(e, h)
}
} else {
var u = ""
}
var t = x + md5(x + u);
var n;
if (l == "DECODE") {
g = g ? g + time() : 0;
tmpstr = g.toString();
if (tmpstr.length >= 10) {
o = tmpstr.substr(0, 10) + md5(o + v).substr(0, 16) + o
} else {
var f = 10 - tmpstr.length;
for (var q = 0; q < f; q++) {
tmpstr = "0" + tmpstr
}
o = tmpstr + md5(o + v).substr(0, 16) + o
}
n = o
}
var k = new Array(256);
for (var q = 0; q < 256; q++) {
k[q] = q
}
var r = new Array();
for (var q = 0; q < 256; q++) {
r[q] = t.charCodeAt(q % t.length)
}
for (var p = q = 0; q < 256; q++) {
p = (p + k[q] + r[q]) % 256;
tmp = k[q];
k[q] = k[p];
k[p] = tmp
}
var m = "";
n = n.split("");
for (var w = p = q = 0; q < n.length; q++) {
w = (w + 1) % 256;
p = (p + k[w]) % 256;
tmp = k[w];
k[w] = k[p];
k[p] = tmp;
m += chr(ord(n[q]) ^ (k[(k[w] + k[p]) % 256]))
}
if (l == "DECODE") {
m = base64_encode(m);
var c = new RegExp("=","g");
m = m.replace(c, "");
m = u + m;
m = base64_decode(d)
}
return m
};
代码的解读呢,就是它对加密的图像地址进行了base64解码,所以解决思路是直接对源码中的Base64图像地址进行解码。
在python中利用base64这个库可以很方便的对数据进行Base64编码和解码
随意对其中一个地址进行解码,发现长这样
b'//wx2.sinaimg.cn/mw690/0072vvHCgy1ft1o45xp00g30a905ku1a.gif'
# 构建正确的图片地址
url = ('http:' + str(base64.b64decode(item.string.encode('utf-8')))[2:]).replace('\'', '')
四:下载数据到本地
这部分就比较简单了,代码如下
def download_data(url):
global num
dir_path = os.path.abspath('..')
file_name = url.split('.')[2][-8:-1]
postfix = url.split('.')[-1].replace('\'', '')
with open(dir_path + f'\\jan_dan\\wu_liao_tu\\{file_name}.{postfix}', 'wb') as f:
f.write(requests.get(url, headers=header).content)
print(f'{num} task done')
num += 1
Flag 是我用来做多进程循环爬取时退出的一个标记
其中BeautifulSoup的使用可以直接查看官网中文文档,除了它之外,还有lxml等,可以根据自己需要了解选取。这些库的作用简单来说就是:
通过html代码构造一个结构化的数据,提供API方便对数据处理
所以,你其实可以完全不用这些解析器,直接通过re编写正则表达式来获取信息也是可以的。
最后
学习爬虫原则:学习技术,友好爬取,不要给服务器增加额外负担。
为什么会给服务器增加负担:
服务器可以比作是一个内存等资源较大的个人计算机,就像你同时开很多进程的时候计算机会卡甚至死机一样,服务器同时处理太多的请求也是这样的道理。
所以如果你只是学习技术而不是看重数据的话,最终可以拿到那最终的一份数据就可以了。
如果需要获取数据的话,可以考虑在夜深人少服务器比较空闲的时候进行。
贴下完整代码
# -*- coding:utf-8 -*-
# author: 禾斗 2018.7
import requests
from bs4 import BeautifulSoup
import base64
import os
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time, random
start_url = 'http://jandan.net/pic/page-232#comments'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
num = 0
Flag = True
def download_data(url):
global num
dir_path = os.path.abspath('..')
file_name = url.split('.')[2][-8:-1]
postfix = url.split('.')[-1].replace('\'', '')
with open(dir_path + f'\\jan_dan\\wu_liao_tu\\{file_name}.{postfix}', 'wb') as f:
f.write(requests.get(url, headers=header).content)
print(f'{num} task done')
num += 1
def get_wuliaotu(url):
global start_url, Flag
try:
resp = requests.get(url, headers=header)
bs = BeautifulSoup(resp.text, 'html.parser')
next_url = 'http:'+ bs.find('a', class_='previous-comment-page').get('href')
except Exception as err:
print(f'Error:{err}')
Flag = False
return Flag
url_ls = set()
for item in bs.find_all('span', class_='img-hash'):
url = ('http:' + str(base64.b64decode(item.string.encode('utf-8')))[2:]).replace('\'', '')
url_ls.add(url)
pool = ProcessPoolExecutor(max_workers=8)
pool.map(download_data, url_ls)
url_ls.clear()
start_url = next_url
time.sleep(random.randint(3,6))
if __name__ == '__main__':
while True:
get_wuliaotu(start_url)
如果有碰到什么问题,欢迎留言交流
考虑一下,如果要根据OO跟XX数来抓取的话,要怎么做