(仅供自己记录,可能提供不了实际参考价值。)
C&C服务器:远程命令和控制服务器,目标机器可以接收来自服务器的命令,从而达到服务器控制目标机器的目的。 C&C服务器指挥大量受到感染的计算机共同行动。
僵尸网络:攻击者(botmaster)出于恶意目的,通过命令控制信道(C&C channel)操控一群受害主机(bots)所形成的攻击平台。
dns给攻击者管理僵尸网络提供了一个平台。僵尸网络访问c&c域名或ip来访问c&c服务器,获取攻击者命令。通过使用域名,攻击者可以在不同的IP地址之间快速切换恶意系统。
一般来说,可以将一般的恶意行为分为以下几类:
1.传播恶意软件(to disseminate malware)
2.帮助C&C服务器进行通信(to facilitate command and control (C&C)communications)
3.发送垃圾邮件(to send spam messages)
4.诈骗和钓鱼(to host scam and phishing webpages)
恶意行为的检测有多种方式或途径,包括:
1.分析网络流量[18, 19]
2.检查网页内容[20, 21]
3.检查URL[22]
4.综合使用以上技术[23, 24]
5.分析DNS数据(aurhor评价其为最有前途的研究方向)
分析dns数据的好处
1.DNS数据只是整个网络数据中的一小部分,数据量适中便于进行分析、处理和实验。
2.恶意行为会在DNS数据中留下痕迹,因此可以通过提取有意义的特征(features)来分析域名和恶意行为之间的关系。
3.很多被提取的特征可以进一步和其他相关的补充信息进行联合,给分析提供了更加充足的空间。
4.大部分的DNS流量数据都是未加密的,使得获取并实验成为了可能。
5.可以通过不断进行的DNS数据分析提前预知和防卫即将到来的攻击。
DNS基本信息
DNS:域名系统,实现从域名到实际ip之间的映射。
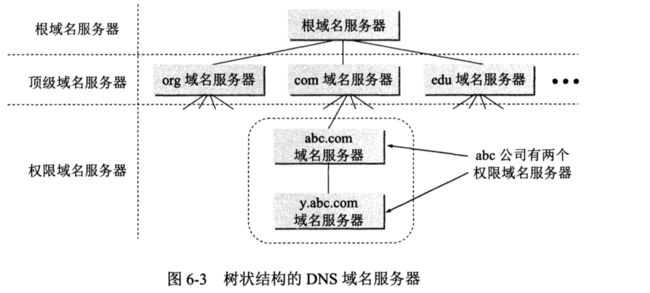
DNS服务器:根域名服务器,顶级域名服务器,权限域名服务器,本地域名服务器(又称为递归服务器:RDNS)。
递归服务器主要是用于接收并应答从 DNS 客户端或解析器发来的初始 DNS 查询,若本地没有查询的数据,则代替 DNS 客户端从根逐级发起迭代查询,直到请求到结果,并将结果返回给 DNS 客户端;同时对从其它权威服务器获取的域名 IP 地址信息进行缓存。一般递归服务器主要用于运营商或 Global DNS,大多数企业不需要搭建属于自己的递归服务器。递归服务器一般称为 Local DNS ,如北京联通的 202.106.0.20。
dns工作过程:当dns客户机需要查询域名时,它会查询本地域名服务器来解析该域名。客户机发送的每条查询消息都包括三条信息:1.指定的dns域名。2.指定的查询类型,可根据类型指定资源记录。3.dns域名的指定类别。(e.g:对于dns服务器,他始终应指定为internet(IN)类别。)
DNS查询流程
DNS 查询:递归和迭代。
递归:主机向本地域名服务器的查询通常是递归查询。如果主机查询的本地域名服务器不知道被查询域名的IP地址,那么本地域名服务器就以dns客户的身份,向其他域名服务器继续发出查询请求报文,而不是让该主机自己进行下一步的查询。
迭代:本地域名服务器向根域名服务器的查询通常是迭代查询。迭代查询是:当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所查询的IP地址,要么告诉本地域名服务器应该去哪里查询。然后让本地域名服务器进行后续的查询,而不是替本地域名服务器进行后续的查询。
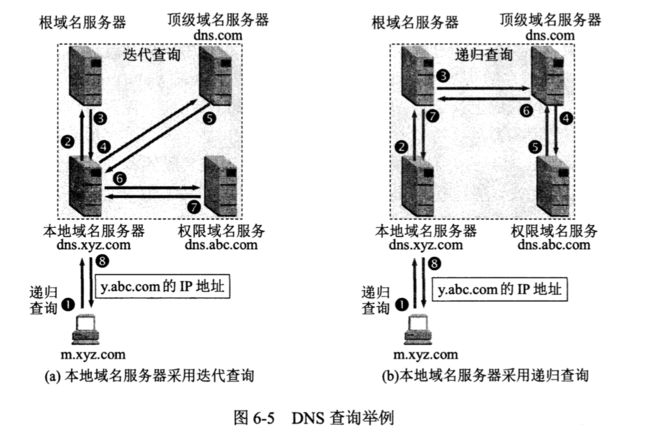
其中DNS解析域名的过程如下:
1.首先主机将域名提交给 :本地域名服务器。本地域名服务器首先检查自身缓存,如果存在记录则直接返回结果。
2.如果记录不存在的话,本地域名服务器将域名发给:根域名服务器
4.根域名服务器本地查找,没有,于是将 下一层顶级域名服务器IP地址 返回给本地域名服务器
5.本地域名通过获得的IP 地址将域名信息发送给顶级域名服务器,得到权限域名服务器的IP地址。
6.本地域名通过获得的IP地址将域名信息发送给权限域名服务器,得到主机的记录,存入自身缓存并返回给客户端。
通过dns分析僵尸网络的检测通常采用两种方式:1.检测涉及到恶意活动的域。目标是通过监控dns流量来识别受感染的主机。2.侧重于机器群组的行为来判断他们是否受到感染。(例如,计算机集合总是重复的联系同一个域)
域名解析两大步骤:1.本机向本地域名服务器发出一个dns请求报文,报文里携带需要查询的域名。2.本地域名服务器向本地主机回应一个dns响应报文,里面包含域名对应的ip地址或者别名等。
DNS报文:
Dns报文的格式:
DNS是一个应用层协议,基于TCP/IP传输,一般的DNS报文传输层是UDP报文。下面是DNS报文的格式:
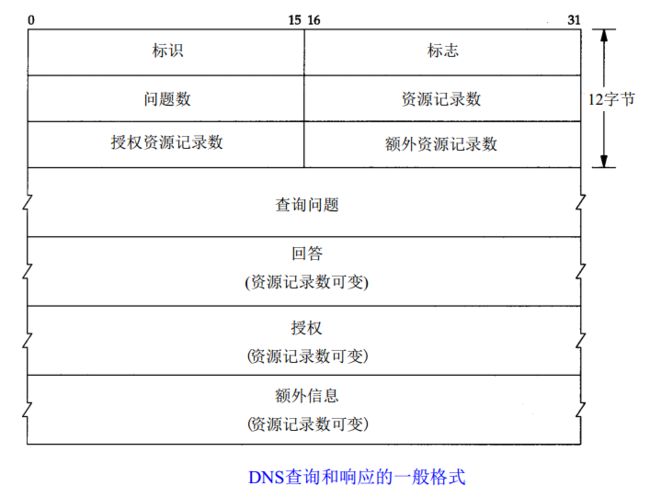
DNS报文由12字节长的首部和4个长度可变的字段组成。
报文头部:
会话标识:dns报文的id标识,用来对应请求和应答报文。
标志:定义各种标志位。
问题数:表示报文请求段中的问题记录数。
资源记录数:表示报文回答段中的回答记录数。
授权资源记录数:表示报文授权段中的授权记录数。
额外资源记录数:表示报文附加段中的附加记录数。
查询报文:

查询名:指要查找的域名。
查询类型:每个问题有一个查询类型,每一个相应也有一个类型。这个类型表明需要进行的服务类型,一般为A(IP地址查询)。
NS:查询授权的域名服务器。
CNAME:查询规范名称
MX:邮件交换记录
查询类通常是1,指互联网地址(IN)。
DNS响应报文中的资源记录部分:
DNS报文中最后的三个字段,回答字段、授权字段和附加信息字段,均采用一种称为资源记录RR( Resource Record)的相同格式。
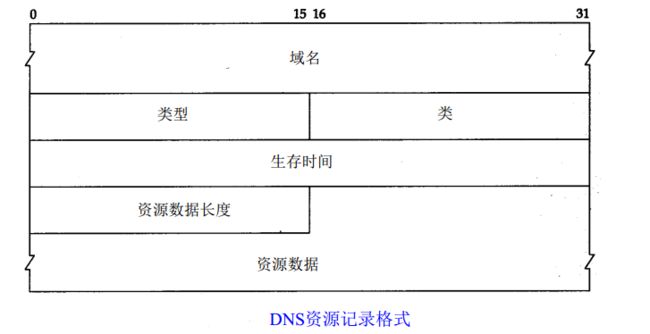
域名:资源记录中资源数据对应的名字。
类型:资源记录的类型。
类:通常为1,指internet数据。
生存时间字段:TTL值TTL值全称是“生存时间(Time To Live)”,简单的说它表示DNS记录在DNS服务器上缓存时间。这个缓存时间太长和太短都不好,如果缓存时间太长,一旦域名被解析到的IP有变化,会导致被客户端缓存的域名无法解析到变化后的IP地址,以致该域名不能正常解析,这段时间内有可能会有一部分用户无法访问网站。如果缓存时间太短,会导致用户每次访问网站都要重新解析一次域名。
资源数据长度: 。
资源数据:RDATA,表示按照查询段的要求返回的相关资源记录的数据。可以是Address(表明查询报文想要的回应是一个IP地址)或者CNAME(表明查询报文想要的回应是一个规范主机名)等。
DNS数据:
dns数据的问题:(摘自2018论文,文献去这儿找)
1.在单个组织的网络(例如,校园网络)中设置DNS流量传感器相对容易,但是收集的数据只能提供有限的本地全局威胁视图。许多现有的基于DNS的恶意域检测技术的特点是它们在大数据场景中效果最好。因此,他们可能无法在小型网络中收集的数据集上产生有意义的结果。
2.相关资源记录。 通过探索可以从DNS数据库检索的与其相关的其他RR,可以获得关于给定域或IP的更多信息。 例如,Hao等人。 [68]已经表明恶意域的IP空间中的DNS MX记录的分布与良性域的不同。 此外,Prieto等人。 [130]观察到与僵尸网络相关的域名通常没有任何相关的MX记录。
网络数据。 IP /域数据还可以利用来自网络活动的信息[130]来丰富,例如,如果网站与域相关联,HTTP响应是什么,打开了什么端口等等。 研究人员通常通过开发自己的探针或使用整个互联网扫描仪(如Censys [53]或Shodan [14])提供的信息来获取此类信息。
如何收集DNS数据:在给定的时间点上获取ip和域名之间现有关联的信息有两种方式:
主动dns:
定期积极主动地解析大量收集的域名以获得信息。
例文:Enabling Network Security Through Active DNS Datasets
概述:
我们介绍了主动DNS的概念,并讨论了一个新的大规模系统Thales,它能够系统地查询和收集大量活动DNS数据。该系统的输出是一个可以被安全社区轻松使用的提取数据集。
系统两模块:1.使用种子域名列表作为系统的输入生成大量的dns查询 2.收集网络流量并对这些原始dns数据集进行处理(例如删除重复数据)
种子域名列表包含了:Alexa [3]热门域名列表;各种顶级域(TLD)区域文件;构建了一个爬虫用于收集和解析Common-Crawl数据集中所见的域;安全公司提供的一些涉及到恶意活动的域名;一系列公共黑名单数据:Abuse.ch [2],Malware DL [9],Blackhole DNS [8],sagadc [10],hphosts [6],SANS [11]和itmate [1]。
为了证明其优点,我们提供了在大型大学网络上收集的活动DNS和被动DNS数据集之间的深入比较。该分析表明,活动的DNS数据提供了更大的覆盖范围(即,更大的数量和更多种类的记录),但被动DNS数据提供了更密集,更紧密连接的图。由于存在这些差异,我们提供了案例研究(第四部分案例分析,我没看),证明了如何使用主动DNS来促进新研究,甚至重新实施现有的DNS相关研究。我们真诚希望通过向安全社区开放积极的DNS,我们可以促进更多更好的DNS研究。
Q1:This creates a temporal history of the DNS activity capable of describing the IP infrastructure history that supported the domain name, before blacklisting, at the time, and after it was blacklisted. This is a new property that active DNS datasets will freely offer to the security community, and it is a property that is rarely seen in passive DNS data.
活动DNS数据不能用于利用依赖于用户级特征(例如,用户查询的时间统计)的技术来检测恶意域。
被动dns:
被动DNS(PassiveDNS)就是一个存储有公共DNS通信中涉及到的所有域名、服务器和IP地址相关的所有历史记录的安全数据库,被动地观察发送到DNS服务器的所有请求,提取必要的数据。
被动收集DNS数据是通过在DNS服务器前部署传感器或访问DNS服务器日志来获取真实DNS查询和响应来完成的。
例文:EXPOSURE: a Passive DNS Analysis Service to Detect and Report Malicious Domains
在实际部署中,DNS流量的数量和速率可能比出版物中使用的数据集大得多。因此,检测方法必须是可扩展的,以在这样的生产系统中工作。此外,一些方法需要大量的数据集来训练和调整它们的检测算法。为了解决这个问题,一些作者建议使用分布式计算平台,如Apache Hadoop[3]或Apache Giraph[2]。另一些则通过将被认为不太重要的数据元素分散出来来减小数据集的大小。例如,Exposure[35,36]过滤掉了Alexa前1000个域[25]和那些在预先防御期间被查询少于20次的域的所有域。不幸的是,这种过滤可能导致忽略可能具有潜在恶意的重要域集。在这种情况下,我们需要一个系统的性能评估,它不仅考虑到检测方法的复杂性和可伸缩性,还考虑到减少所需数据大小所需的抖动预处理步骤的特征。
被动dns分析和声誉(reputation)结合来检测恶意域。
reputation:
声誉主要指域和IP地址的信誉列表。
域列表:已知的良好的域名,已经的坏的域名,也可以包含其他元数据字段:域触发时的最后一个事件;域在域中保留的长度;首次触发匹配的时间。
IP地址列表:IP地址,其他元数据信息:域列表中的元数据。(元数据:主要用来描述数据属性的信息。)
可能存在着黑名单中的白名单域,即这个域是安全的,但是其可能会被攻陷。系统应该具有何时从白名单中取出域或IP的阈值,并定义其被视为恶意的标准。
声誉列表应考虑的问题:1.收集数据 2.域名通过什么被分类为恶意的 and so on.
选择哪种数据
主动dns的缺点:如果非法网络的管理员检测到主动探测其网络的系统,他们可以丢弃这个请求。
使用被动dns的原因:通过被动地观察数据,而不在分析期间进行主动DNS查询,系统可以保持隐蔽性并且不会被管理系统显示为恶意的域/网络的网络犯罪分子检测到。
几篇dns方面的经典论文:
1.Building a Dynamic Reputation System for DNS
2.Detecting Algorithmically Generated Domain-Flux Attacks with DNS Traffic Analysis
3.EXPOSURE: a Passive DNS Analysis Service to Detect and Report Malicious Domains
以下基于EXPOSURE系统:
EXPOSURE旨在执行被动DNS分析,以检测涉及恶意活动的域。
EXPOSURE 在部署和生成环境之前,使用各种数据集进行了一周的离线培训,然后将其设置为内联,用来实时捕获和处理数据。EXPOSURE 将恶意域定义为一个旨在涵盖所有恶意活动的通用术语,但也将它们划分为十个不同的类别:“我们将域名划分为十个组:垃圾邮件域(垃圾邮件),黑名单域名(BlackList),恶意Fast-Flux域名(FastFlux),恶意软件查询的域名,恶意软件分析工具(恶意软件),Conficker域名(Conficker),具有成人内容的域名,受Norton Safe Web和McAfee Site Advisor(Risky)怀疑存在风险的域名,网络钓鱼域名(网络钓鱼),以及我们无法从Google获取任何信息的域名或者来自其他来源(无信息),最后是被检测为恶意的良性域名(误报)。“
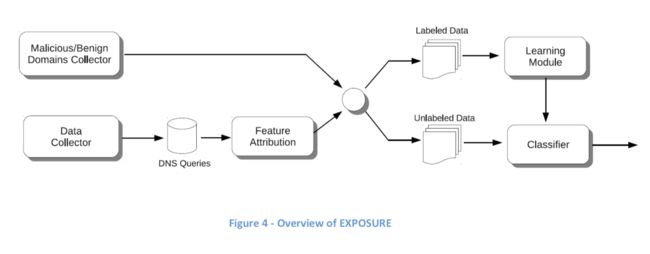
1.数据收集器:离线数据集,记录了来自安全信息交换(SIE)的递归DNS(即RDNS)流量[ISC 2010])。从SIE获取的数据包括从真实用户主动使用的多个递归DNS服务器收集的DNS流量。系统初始输入的部分RDNS流量包括从授权DNS服务器返回到RDNS服务器的DNS应答。 RDNS应答包括查询的域名,发出查询的时间,需要缓存应答的持续时间(即TTL)以及与查询域关联的IP地址列表。
2.特征选择:
通过研究大量DNS数据,我们定义了15种用于检测恶意域的不同特征。 他们主要来自四组特征:基于时间的特征,基于DNS应答的特征,基于TTL值的特征,基于域名的特征。
基于时间的特征:
请求发出的时间。单个请求的时间本身没什么用,但是分析对特定域的许多请求时,可能会出现指示恶意行为的模式,即恶意域通常会突然增加,然后突然减少请求数量。这是因为恶意服务经常使用一种叫做域通量的技术。每个机器人使用域生成算法(DGA)来计算要用作命令和控制服务器或Dropzone(Dropzone是一款适用于Mac操作系统的软件。)的域列表。由DGA生成的所有域的寿命都很短,因为他们仅在有效的时间内使用。
为了分析在给定时间段内域的请求数量的变化,我们将该时段划分为固定长度的时间间隔。对于每个间隔,我们计算为这个域发出的dns查询的数量。换句话说,将正在分析的域的dns查询的集合转换为时间序列,我们对两个不同的范围进行时间序列分析:1.分析全局(即这整个监控阶段)的时间序列,即时间序列的开始和结束时间被选择为与整个监视时段的开始和结束时间相同。2.本地范围(即对某个域进行分析时)时间序列分析,开始时间和结束时间对应于分析间隔期间查询域的第一次和最后一次被查询的时间。全局范围分析侧重于检测寿命较短或短时间内改变其行为的域,本地范围分析侧重于域在其生命周期中的行为方式。
Time-Based Features :1. Short life
2. Daily similarity
3. Repeating patterns
4. Access ratio
如果仅在时间t0和t1之间查询域,并且如果该持续时间相对较短(例如,少于几天),则域被定义为短寿命域(即,特征1)。突然出现在全局范围时间序列中并且在短时间活动后消失的域被认为是恶意域。
执行局部范围分析的主要思想是放大域的生命周期并研究其行为特征。我们主要关注三个特征(即特征2,3,4),这些特征可以通过自身或与其他特征结合使用来区分恶意和良性行为。特征2检查是否存在显示其请求计数随时间变化的每日相似性的域(即,每天以相同间隔增加或减少请求计数)。特征3旨在检测规则重复模式:算法检测到的变化的数量(特征3a)并且检测到变化之前观察到的行为持续时间的标准偏差(特征3b)。检测具有规则重复模式的短寿命域和域的问题可以被视为变化点检测(CPD)问题。 CPD算法按时间序列运行,其目标是找到数据值突然变化的那些时间点。 我们实施的CPD算法[Basseville和Nikiforov 1993]输出检测到变化的时间点和每个持续时间的平均行为。 最后,特征4检查域是否通常处于“空闲”状态(即,不查询域)(特征4a)或连续访问(即,流行域)(特征4b)。
基于DNS应答的特征:
服务器返回的域的DNS应答通常由若干个DNS A记录组成(例如:从主机到IP地址的映射)。由于域名可以映射到多个IP地址,DNS服务器以循环的方式循环遍历不同的IP地址,并且每次都返回不同的IP映射。攻击者通常使用映射到多个IP地址的域,并且这些IP地址遍布全世界。
基于此,从dns应答中提取了四个特征:
Number of distinct IP addresses
Number of distinct countries
Reverse DNS query results
Number of domains share the IP with
第一个特征是在实验窗口期间给定域解析的不同IP地址的数量。第二个特征是这些IP地址所在的不同国家/地区的数量。第三个特征是返回的IP地址的反向dns查询结果。第四个功能是共享给定域的解析的IP地址的不同域的数量。
基于TTL值的特征:
每个dns记录都有一个生存时间TTL(TTL(Time-To-Live),就是一条域名解析记录在DNS服务器中的存留时间。当各地的DNS服务器接受到解析请求时,就会向域名指定的NS服务器发出解析请求从而获得解析记录;在获得这个记录之后,记录会在DNS服务器中保存一段时间,这段时间内如果再接到这个域名的解析请求,DNS服务器将不再向NS服务器发出请求,而是直接返回刚才获得的记录;而这个记录在DNS服务器上保留的时间,就是TTL值。)攻击者通常会设置较低的TTL值和使用Round Robin(Round Robin:轮询调度是一种以轮询的方式依次将一个域名解析到多个IP地址的调度不同服务器的计算方法。)来抵御dns黑名单。Fast-Flux服务网络(FFSN)[T.Holz et al。 2008]是滥用Round-Robin DNS的恶意系统。大多数抵御FFSN的技术都是基于分析Round-Robin DNS的异常使用模式。
我们从dns应答中包含的TTL值中提取了五个特征:
Average TTL
Standard Deviation of TTL
Number of distinct TTL values
Number of TTL change
Percentage usage of specific TTL ranges
平均TTL:平均TTL值的使用情况(是个挺有用的特征?)
TTL的标准偏差:恶意域的TTL值更分散
不同TTL值的数量:不同TTL值的总数明显高于良性域
TTL变化的数量:变化的数量明显高于良性域
特定TTL值的范围的使用情况的百分比:[0,100]的范围表现出恶意域的显著峰值
基于域名的特征:
% of numerical characters:数字字符与域名长度的比率
% of the length of the LMS:最长有意义子字符串的长度比率(例如:字典中的一个单词)到SLD(二级域:例如,对于x.y.server.com,我们将使用server.com)的总长度的比率 (a little confused)
3..恶意域和良性域收集器收集的白名单和黑名单:
数据集:
恶意域数据:从多个来源收集了恶意域名。具体来说,我们从malwaredomains.com [域名2009],Zeus Block List[列表2009b],恶意软件域列表[列表2009a],Anubis[Bayer et al. 2006] 报告中获取了恶意域名,这些域名是从Wepawet [Cova]和Phishtank [Phishtank 2009]分析的可疑恶意URL中提取的域名列表。我们还使用了由Conficker的DGAs生成的域名列表[Porras et al。 2009]和Me-broot [Stone-Gross et al。 2009](即Torpig)僵尸网络。这些恶意域列表代表各种恶意活动,包括僵尸网络命令和控制服务器,偷渡式下载站点,网络钓鱼页面以及可在垃圾邮件中找到的诈骗站点。
良性域数据:超过一年的所有Alexa前1000个域构建初始良性域列表。对良性域进行验证筛选,使其不涉及恶意域。
创建检测模型:
4.学习模块:将标记的训练集训练成模型,用来检测恶意域名。
5.分类器:检测未标记的训练集中的恶意域。
分类器:
分类器由J48决策树算法构建,J48是C4.5算法的实现,用来生成修剪或未修剪的C4.5决策树。它通过使用信息熵的概念(训练集的属性值)从一组标记的训练集中构造决策树。
使用遗传算法(GA)选择特征,使用C4.5的J48实现及其默认参数和ecj20工具包[ecj 2012]用于遗传算法实现。
我们根据所使用的信息类型将我们使用的15个特征分为四个不同的类:从时间序列分析(基于时间的特征),DNS应答分析,TTL值分析,域名分析。使用不同的特征集组合训练分类器,使用产生最小错误率的特征组合。结果表明,所有特征组合在一起时,产生最小错误率。
分类器结果验证:
为了评估J48决策树分类器的准确性,我们将我们的训练集分类为10倍交叉验证和百分比分割,其中66%的训练集用于训练,其余用于检查正确性。对于两种方法,分类器的ROC曲线下面积[Bradley 1997]都很高。
工作的对比:
Perdisci 对多个isp网络收集的递归dns流量执行被动dns分析,目的是检测恶意Fast-Flux服务。他的工作不依赖于分析列入黑名单的域名和从垃圾邮件中提取出来的域名。
EXPOUSE和他们的区别是,其能够检测到所有不同类型的恶意域,例如网络钓鱼站点,垃圾邮件域,dropzones和僵尸网络命令和控制服务器。不仅专注于检测Fast-Flux服务网络。
EXPOUSE依赖于聚合数据或以批处理模式运行,因此,在能够决定域的恶意状态之前,它们必须观察大量DNS请求。然而,这些方法所引起的延迟可能使它们对于在短时间内提供恶意活动的域无效,就像域通量一样。例如,Sheng等人[143]发现“63%的网络钓鱼活动持续时间不到两个小时”。另一方面,一些方法利用了实时特性(而不是聚合),可以动态标记域。然而,与聚合特性相比,非聚合特性通常更容易伪造。
与之前的作品相比,EXPOSURE不依赖于大量的历史恶意数据(例如,以前受感染的服务器的IP地址),需要较少的培训时间,并且还能够检测映射到新的恶意域每次地址空间,再也不用于其他恶意目的。
设计检测恶意域的系统需要:
1.数据源:是要主动数据还是被动数据(基本上都使用被动数据)
dns数据的问题:
1.在单个组织的网络(例如,校园网络)中设置DNS流量传感器相对容易,但是收集的数据只能提供有限的本地全局威胁视图。许多现有的基于DNS的恶意域检测技术的特点是它们在大数据场景中效果最好。因此,他们可能无法在小型网络中收集的数据集上产生有意义的结果。
2.相关资源记录。 通过探索可以从DNS数据库检索的与其相关的其他RR,可以获得关于给定域或IP的更多信息。 例如,Hao等人。 [68]已经表明恶意域的IP空间中的DNS MX记录的分布与良性域的不同。 此外,Prieto等人。 [130]观察到与僵尸网络相关的域名通常没有任何相关的MX记录WHOIS数据。
网络数据。 IP /域数据还可以利用来自网络活动的信息[130]来丰富,例如,如果网站与域相关联,HTTP响应是什么,打开了什么端口等等。 研究人员通常通过开发自己的探针或使用整个互联网扫描仪(如Censys [53]或Shodan [14])提供的信息来获取此类信息。
检测恶意域的事实依据:
恶意域来源:主要做法是从公共黑名单中提取。一些黑名单仅涉及特定的恶意活动,例如垃圾邮件(Spamhaus [15],Yahoo Webspam Database [21]),网络钓鱼(PhishTank [125],OpenPhish [13]),而其他一些则更为笼统,包括域名/ IP涉及任何类型的恶意活动,例如VirusTotal [159],McAfee SiteAdvisor [10],恶意软件域[153]和恶意软件域名列表[9]。其中一些来源,如WoT [19],也可以将那些本身不与恶意活动相关联的域列入黑名单。如果对于所考虑的特定黑名单的政策(例如,色情内容,暴力,种族主义,受版权保护的材料等),此类网站的内容被认为是不合适的,则属于这种情况。构建基本事实的另一个来源是专有黑名单/白名单,或由反病毒安全公司(例如赛门铁克)部署的专有信誉系统,其对一般研究社区的可用性非常有限。
良性域来源:主要来自高度排名的流行域。例如,Alexa排名靠前的域[25]是常用的.5另一种常见做法,至少在构建初始候选良性域集时,基于顶级域。例如,来自“gov”和“mil”区域的域或者谷歌和微软的域(例如,参考文献[174]中使用的域)通常被认为比来自“com”或“info”的域更可信。此外,一些公共网络情报工具,如McAfee SiteAdvisor [10],Google Safe Browsing [8]或Web of Trust [19]不仅报告了恶意域和可疑域,还报告了良性域,因此也可用于提取良性基础事实。
所存在的问题:
恶意域:为一种方法收集的基本事实可能不适用于另一种侧重于检测涉及其他类型恶意活动的域的方法。其次,黑名单采用不同的收集方法。例如,他们可能依赖人群来源数据(例如,PhishTank [125],Web of Trust [19]),可以抓取和分析网站内容(例如,Wepawet [59]),可以在沙箱中运行恶意软件和分析所访问的域(例如,Anubis [1]),可以反转僵尸网络协议并生成由DGA生成的名称的馈送(例如,Conficker [99]),可以使用内部工具(例如,Google Safe Browsing [8])获得,或者可以汇总来自不同来源的数据(例如,UrlVoid [18]或VirusTotal [159])。第三,没有一个黑名单是完全可靠的。 Sinha等。 [145]和Ramachandran等人。 [135]显示黑名单表现出高假阳性率和假阴性率。一些方法通过交叉检查多个黑名单中的域来解决这个问题。例如,Kheir等人。 [85]通过对三个不同的黑名单进行投票,建立了一个地面实况数据集。
良性域:虽然使用顶级K Alexa域名[25]作为良性基础事实是有意义的(流行网页的管理员投入更多精力来保护他们的资源),但它既有限又缺乏高误报率。该列表仅包含2LD域,并且不提供有关子域的任何信息,这使得它相当有限。域名根据其受欢迎程度排名,但不基于其安全性或安全性,从而导致高误报率。它包含恶意网页的代理,甚至包含托管恶意内容的域。例如,一个非常受欢迎的2LD,unblocksit.es(截至2016年4月1日排名为11550),提供代理访问其他可能被列入黑名单的域名。这个2LD本身并不是恶意的,因为它可以被合法用户用来试图绕过他们所面临的审查措施。同样,恶意用户可以滥用此服务作为打败已知阻止机制的安全避风港。此外,由于来自大量受感染客户端的查询请求突然爆发,一些恶意域可能出现在前K个Alexa域中。Stevanovic等。 [150]来自Alexa顶级K域的UrlVoid交叉检查域[18],该服务汇总了来自不同黑名单的信息。结果显示,相对较高比例的域(在10,000个顶级域中约占15%)被至少一个黑名单报告为恶意。
这些良性基础事实的杂质会对域检测方法的准确性产生负面影响。例如,考虑一个恶意域d,它被错误地标记为基本事实中的良性,就像在Alexa top K域中一样。 d的正确检测将被错误地计为假阳性,导致测量的假阳性率高于其实际值。同时,由于缺乏与恶意域的关联,可能会错过与d有很强关联的恶意域,这会对真正的阳性率产生负面影响。为了减轻Alexa顶级K杂质的影响,一些方法在将它们添加到良性基础事实之前过滤域。例如,Rahbarinia等人。 [133]只考虑一年内在Alexa排名前100万的网站中持续出现的域名。同样,Bilge等人。 [35,36]只考虑1年以上的域名为良性。在构建良性域的基本事实之前,一些其他方法(例如,参考文献[28,82])移除动态DNS服务域,例如no-ip.com。可以看出,对于什么可以或应该构成良性域的基本事实尚未达成共识。
共同的挑战:
1.是否应该将恶意/良性域的任何子域视为恶意/良性?如果域的大多数子域是恶意/良性的,我们是否应该将域视为恶意/良性?不幸的是,这些问题没有明确的“是”或“否”答案。在某种程度上,对于属于Google或Facebook等私人组织的2LD,对这些问题回答“是”可能是合理的。但是,动态DNS服务的子域(如no-ip.com和3322.org)可能完全不相关,因此,即使绝大多数子域是良性的,也不能假设是良性的。
2.我们在文献中发现的另一个常见问题是对包含地面实况数据的训练和测试集进行有限的定量讨论。已经证明(参见参考文献[42,160]),不平衡的训练数据集可能对分类器的学习产生相当大的影响,因此可能影响一些测量的度量。
2选择能够区分出恶意域的特征,使用哪种检测方法来检测恶意域。
特征:。。。
检测方法: 监督学习,半监督学习,无监督学习
无监督学习:无监督学习方法,即聚类技术[78],仅使用数据的内部属性自动将域划分为聚类。理论上,通过仔细选择对恶意域和良性域表现出完全不同行为的特征,可以启用聚类算法将提供的样本划分为两个聚类。然后,研究人员决定哪个群集包含恶意和良性域[45,46,150]。然而,一些方法,例如参考文献[154,171],不遵循这条路径并且更进一步。他们跨越与不同恶意行为相关的多个维度对域进行分组,然后通过将所识别的组彼此关联来选择恶意域的集群。
尽管这些方法在标记数据的独立性方面具有明显的益处,但它们在文献中并不常见。我们认为这主要是因为这些技术是最难设计的。此外,鉴于标记数据集通常存在于该区域(althogh既不完整也不完全正确),研究人员更愿意探索更容易使用的监督和半监督方法。
Q:能否可以用无监督学习搞一下。。。
检测方法的挑战:1.在实际部署中,dns流量的数据集很大。通过过滤掉被认为不太重要的数据元素来减少其数据集大小。例如,Exposure [35,36]过滤掉Alexa Top 1000域[25]中的所有域以及在预定义时间段内查询少于20次的域。不幸的是,这种过滤可能导致忽略可能具有潜在恶意的重要域集。在这种情况下,我们需要进行系统的性能评估,不仅要考虑检测方法的复杂性和可扩展性,还要考虑所需数据大小减少所需的过滤预处理步骤的特性。
2.恶意域检测方法面临的第二个问题与检测之前遇到的延迟有关。像[35,36]这样的方法依赖于聚合数据或以批处理模式运行,因此,在能够对域的恶意状态做出决定之前,他们必须观察许多DNS请求。然而,这种方法引起的延迟可能使它们对于在短时间内服务于恶意活动的域无效,如域流动的情况。例如,Sheng等人。 [143]表明“63%的网络钓鱼活动持续时间不到两小时。”但是,有些方法利用实时功能(而不是聚合),可以动态标记域名。但是,与聚合功能相比,非聚合功能通常更容易伪造。这两种方法都有优点和局限性,因此,一个在另一个上的最佳选择受到部署环境的严重影响。
混合方法:
1.Notos系统[28]。它在第一阶段训练五个元分类器,使用监督学习技术评估域与预定义域组(Popular,Common,Akamai,CDN和Dynamic DNS)的接近程度。然后将计算的接近度分数用作第二阶段监督学习算法的特征。
2.Oprea等。 [126]将半监督方法(信念传播BP)与监督学习算法(线性回归)相结合。
还有一些结合图的检测方法。。。暂时未作了解。。。