英文原文链接:https://www.infoq.com/articles/machine-learning-techniques-predictive-maintenance
作者:Srinath Perera,Rosha Alwis 审阅:Srini Penchikala
关键摘要
- 了解预测性维护系统(PMS),以便监控日后的系统故障并提前安排维护工作
- 探讨如何构建机器学习模型来预测系统维护
- 机器学习过程和步骤,如模型选择和使用自动编码器消除传感器噪声
- 如何训练机器学习模型,并使用WSO2 CEP产品运行模型
- 使用NASA发动机故障数据集和回归模型预测剩余使用寿命(RUL)的示例应用程序
我们每天依赖许多系统和机器。我们开车去旅游,乘电梯上下楼,坐飞机出行;电力经由涡轮机传送,医院的机器维持着病人的生命。而这些系统都有可能故障。有的故障只是带来不便,而有的故障则关乎生死。
当风险较高时,我们会定期对系统进行维护。例如,汽车会每隔几个月进行一次维护,而飞机则要每天维护。但是,正如本文稍后将会详细讨论的,这些方法会导致资源浪费。
预测性维护对故障进行预测,采取的措施可能包括纠正措施、系统置换,甚至是计划故障。这样可以节省大量成本,提高可预测性并提升系统的可用性。
预测性维护节省成本有以下两种形式:
- 避免或尽量减少停机时间。这将避免不愉快的客户、省钱,有时甚至能挽救生命。
- 优化定期维护操作。
为了理解这个过程,我们可以设想一个出租车公司。如果一辆出租车出现故障,出租车公司需要安抚一个生气的客户,更换故障部件,而且出租车和司机在维修期间都无法提供服务。这个故障造成的损失远大于故障本身的花费。
解决这个问题的其中一种方法是更悲观一些,在故障出现以前就早早地把可能会故障的部件更换掉。例如,通过定期维护操作来解决这个问题,比如定期更换发动机机油或者定期更换轮胎。虽然定期维护比发生故障好,但我们可能会在需要维护之前就进行维护。因此这不是最佳解决方案。例如,每3000英里就更换汽车的机油可能导致机油没有被充分使用。如果我们能够更好地预测故障,那么这辆出租车在更换机油之前可能还可以再多行驶几百英里。
预测性维护避免了极端情况并能最大限度地利用资源。预测性维护将检测异常和故障模式,并提供预警。这些警告可以使这些部件得到有效的维护。
在这篇文章中,我们将探讨如何构建一个机器学习模型进行预测性维护。下一节将讨论机器学习技术,接着讨论我们将用作示例的NASA数据集。第四节和第五节将讨论如何训练机器学习模型。“使用WSO2 CEP运行模型”这一节会介绍如何将模型与现实世界的数据流一起使用。
机器学习技术用于预测性维护
要进行预测性维护,我们首先向系统添加传感器,以监控和收集有关其操作的数据。用于预测性维护的数据是时间序列数据。数据包括时间戳,与时间戳同时收集的一组传感器读数以及设备标识符。预测性维护的目标是在“t”时刻,通过到“t”时刻为止的数据,预测设备是否在不久的将来会出现故障。
预测性维护可以通过以下两种方式之一来实现:
- 分类方法 - 预测在后续n个步骤中是否有可能出现故障。
- 回归方法 - 预测在下一次故障之前还剩下多少时间。我们称之为剩余使用寿命(RUL)。
前一种方法仅提供一个布尔值答案,但可以使用较少的数据提供更高的准确性。后者需要更多的数据,尽管它可以提供有关何时发生故障的更多信息。我们将使用NASA发动机故障数据集来探讨这两种方法。
Turbofan发动机老化数据集
Turbofan发动机是NASA太空探测机构使用的现代燃气涡轮发动机。NASA创建了以下数据集,以预测Turbofan发动机随时间推移可能出现的故障。这些数据集可以在PCoE数据集中找到。
数据集中包括每台发动机的时间序列。所有的发动机都是相同类型的,但是每台发动机一开始会有不同程度的初始磨损和制造过程带来的变量,这些对用户来说是未知的。有三个可选设置项可以用来改变每台发动机的性能。每台发动机都有21个传感器在运行时收集与发动机状态相关的不同测量参数。收集的数据会被传感器噪声污染。
随着时间的推移,每台发动机都会发生故障,这可以通过传感器读数看出来。时间序列在故障前一段时间结束。记录的数据包括(发动机)编号、时间戳、三个设置项和21个传感器的读数。
如下图1和图2所示为数据的子集。

![[译]机器学习技术用于预测性维护_第1张图片](http://img.e-com-net.com/image/info10/04713eaba19a4e398ae7c4ecd57140fb.jpg)
这个实验的目的是预测下一次故障何时发生。
使用回归模型预测剩余使用寿命(RUL)
预测RUL时,目标是减少实际RUL与预测的RUL之间的误差。我们将使用均方根误差,因为它会严厉地惩罚大误差,这将使算法预测的RUL尽可能接近实际RUL。
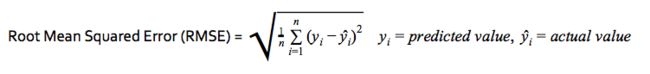
阶段1:以下流程图展示了预测的过程。作为深入了解的第一步,我们只运行了其中高亮显示的步骤。我们在原始数据上运行算法,没有执行任何特征工程。
阶段1:模型选择
下图3显示了包含模型选择的预测性维护流程图。这里仅用到了流程图中深色标记的步骤。
![[译]机器学习技术用于预测性维护_第2张图片](http://img.e-com-net.com/image/info10/5358e465ad0c46dc8b6a8bfd4de8a596.jpg)
我们使用了scikit learn和H2O中的一系列回归算法。对于深度学习,我们使用了H2O的深度学习算法,这个算法在分类和回归方法中都可以使用。它基于使用反向传播的随机梯度下降算法训练的多层前馈神经网络。
结果如下图4所示。不同预测模型可以得到约25-35的均方根误差(RMSE),这意味着预测RUL与实际RUL将有大约25-35个时间步长的误差。
![[译]机器学习技术用于预测性维护_第3张图片](http://img.e-com-net.com/image/info10/124d9c6a105748f6bb79073bd9aeeee7.jpg)
下一步我们将重点关注H2O深度学习模型。
阶段2:使用自动编码器消除传感器噪声
下图5显示了包含噪声消除的预测性维护流程图。这里仅用到了流程图中深色标记的步骤。
![[译]机器学习技术用于预测性维护_第4张图片](http://img.e-com-net.com/image/info10/25d478294efd4810a077e099e48f5bfe.jpg)
传感器读数通常会有噪声。发行版随附的ReadMe文件证实了这一点。因此,我们使用 自动编码器去除噪声。自动编码器是一种简单的神经网络,它使用同一套数据集同时作为网络的输入和输出进行训练,其中网络中的参数比数据集中的维数少。这与主成分分析(PCA) (http://setosa.io/ev/principal-component-analysis/)工作原理非常相似,其中数据以其主要维度表示。由于噪声的维度比常规数据高得多;这个过程减少了噪声。
我们使用具有三个隐藏层的H2O自动编码器和以下标准来消除噪声。
消除噪声将均方根误差减少了2个时间步长。

阶段3:特征工程
下图6显示了包含特征工程的预测性维护流程图。这里仅用到了流程图中深色标记的步骤。
![[译]机器学习技术用于预测性维护_第5张图片](http://img.e-com-net.com/image/info10/1a20748610364ec195130e083f16fa0b.jpg)
在这一步中,我们尝试了许多特征,并保留了最具预测性的特征子集。我们的数据集是一个时间序列数据集,因此读数是 自相关的。所以“t”时刻的预测可能会受到“t”之前的某个时间窗口的影响。我们使用的大多数特征都是基于这些时间窗口的。
如第3节所述,数据集包括21个传感器的读数。我们可以从数据集提供的ReadMe文件中找到有关读数的更多详细信息。经过测试,我们仅使用传感器2、3、4、6、7、8、9、11、12、13、14、15、17、20和21的数据。对于选择的每个传感器,我们通过应用移动标准差(窗口大小为5),移动k-closest平均值(窗口大小为5)以及具有窗口大小(窗口大小为10)的概率分布来生成特征。
我们尝试了但在最终解决方案中未使用的其他特征包括:移动平均值、自相关、直方图、移动熵和移动加权平均值。
通过特征选择将均方根误差减少了1个时间步长。

阶段4:使用网格搜索优化超参数
下图7显示了包含超参数优化的预测性维护流程图。这里仅用到了流程图中深色标记的步骤。
![[译]机器学习技术用于预测性维护_第6张图片](http://img.e-com-net.com/image/info10/406005c28be64ced9744c2303fa8f6ba.jpg)
超参数控制了算法的行为。在最后阶段,我们优化了以下超参数:epochs、distribution、activation和hidden layer size。你可以从H2O文档中找到每个参数的详细说明。我们使用网格搜索(Grid Search)寻找最佳参数,下表总结了结果。
![[译]机器学习技术用于预测性维护_第7张图片](http://img.e-com-net.com/image/info10/9d1672cc8a484852beaa4ce0e659e70c.jpg)
如结果所示,超参数调整将均方根误差减少了大约3个时间步长。在残差直方图中,可以看到残差收敛到了“0”。预测过早和预测过晚的频率被最小化了。
![[译]机器学习技术用于预测性维护_第8张图片](http://img.e-com-net.com/image/info10/1cf9a05150da4c36b1eaac679f7948be.jpg)
建立在后续N个步骤中预测故障的模型
这种方法不再提供剩余的生命周期数,而是要预测机器是否会在接下来的30个周期内故障。我们会将故障视为正(positive,P),而无故障视为常态(normal,N)。我们使用相同的特征工程和噪声消除过程来运行深度学习分类模型。结果如图9所示。
混淆矩阵

准确率描述了预测正确的测试用例所占的百分数。它给出了预测正确的测试用例数与所有测试用例数的比例。
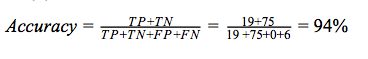
如果类不平衡,只考虑准确率将会产生误导。当数据集中同一类别数据量太多以致不成比例时,就会发生类不平衡。发生类不平衡时,一些模型可能具有高准确率,但预测性能差。
为了避免这个问题,我们使用精确率和召回率。召回率指的是预测为正值的样本数和应该被预测为正值的样本数之间的比例。
精确率被定义为模型预测正值的能力。它指的是预测为正值且实际也是正值的样本数和所有被预测为正值的样本数之间的比例。
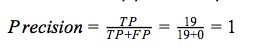
F1分数是衡量准确率的指标。计算F1分数时需要兼顾精确率和召回率。
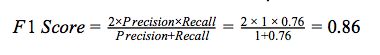
对于准确率、召回率、精确率和F1分数,它们的值越接近1越好。
使用WSO2 CEP运行模型
我们在批处理模式下构建模型,处理存储在磁盘中的数据。但是,要应用模型,我们需要在数据可用时将数据提供给运行中的模型。我们将数据的处理过程称作“流处理”。我们使用流处理引擎WSO2 CEP来应用该模型。
我们使用H2O构建了模型。H2O可以以两种格式之一导出模型:POJO(简单的Java对象)或MOJO(模型对象,经过优化)。前者需要编译,后者可以直接使用。我们使用了CEP的MOJO模型。
为了评估模型,我们使用了WSO2 CEP中的扩展。WSO2使用SQL查询语言处理数据流中的数据。
如图10所示,复杂事件处理系统接收数据作为事件流,并通过一组SQL查询进行评估。例如,通过给定的查询语句可以计算一分钟窗口内的stockQuotes流,并在给定条件下将其与一分钟窗口内的Tweets流合并,然后将事件发送到PredictedStockQuotes流。
![[译]机器学习技术用于预测性维护_第9张图片](http://img.e-com-net.com/image/info10/52645995878545b695baa79e38ddf896.jpg)
使用CEP评估模型的查询示例如下所示。
from data_input #h2opojo:predict('ccpp/DRF_model_python_1479702792496_1')
select T, V, AP, RH, prediction
insert into data_output
下图11显示了包括训练步骤以及评估步骤的整体流程图。
![[译]机器学习技术用于预测性维护_第10张图片](http://img.e-com-net.com/image/info10/e8270e128ef34eb79e0d85e8bede63a7.jpg)
通过查询将事件发送到“data input”流,并应用机器学习模型。应用机器学习模型包括以下步骤:
- 将“阶段3:特征工程”一节中描述的预处理步骤应用于事件中的值并创建特征
- 使用生成的特征评估机器学习模型
- 返回结果
小结
预测性维护的主要目标是预测何时会发生设备故障。然后通过采取相关措施防止故障发生。预测性维护系统(PMS)监控未来可能发生的故障,并提前安排维护工作。
这将带来以下几项成本节省:
- 降低维护频率。
- 最大限度地减少维护特定设备所花费的时间,并使时间利用效率更高。
- 最大限度的减少维护成本。
本文探讨了进行预测性维护的不同方法,包括不同的回归和分类算法。此外,本文还介绍了许多用于调整模型的技术。我们的最终解决方案预测RUL(剩余使用寿命)得到的均方根误差(RMSE)为18.77,而预测在后续N(30)个步骤中出现故障的概率则达到了94%的准确率。
以上技术需要大量的训练数据,包括足够多的故障场景。由于故障很少见,数据收集可能要花很长时间。这一点仍然是应用预测性维护的一大障碍。
参考资料
- Deep Learning with H2O
- PCoE Datasets
- A Simulation Study of Turbofan Engine Deterioration Estimation Using Kalman Filtering Techniques
- Predictive maintenance
关于作者
Srinath Perera是一名科学家、软件架构师,也是分布式系统的程序员。他是Apache Axis2项目的共同创始人,也是Apache Software基金会的成员。他是WSO2复杂事件处理引擎的联合架构师。Srinath撰写了两本关于MapReduce的书籍和许多技术文章。2009年他在美国印第安纳大学获得博士学位。
Roshan Alwin是莫拉图瓦大学计算机科学与工程系的班级代表(CSE 13)。