1. 背景:
以人脑中的神经网络为启发,历史上出现过很多不同版本
最著名的算法是1980年的 backpropagation
2. 多层向前神经网络(Multilayer Feed-Forward Neural Network)
Backpropagation被使用在多层向前神经网络上
2.1 多层向前神经网络由以下部分组成:
输入层(input layer), 隐藏层 (hidden layers), 输入层 (output layers)
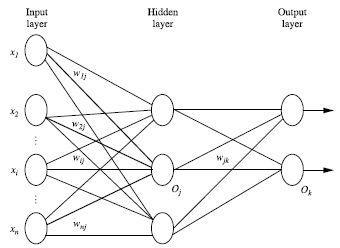
- 每层由单元(units)组成
- 输入层(input layer)是由训练集的实例特征向量传入
- 经过连接结点的权重(weight)传入下一层,一层的输出是下一层的输入
- 隐藏层的个数可以是任意的,输入层有一层,输出层有一层
- 每个单元(unit)也可以被称作神经结点,根据生物学来源定义
- 以上成为2层的神经网络(输入层不算)
- 一层中加权的求和,然后根据非线性方程转化输出
- 作为多层向前神经网络,理论上,如果有足够多的隐藏层(hidden layers) 和足够大的训练集, 可以模拟出任何方程
3. 设计神经网络结构
3.1 使用神经网络训练数据之前,必须确定神经网络的层数,以及每层单元的个数
3.2 特征向量在被传入输入层时通常被先标准化(normalize)到0和1之间 (为了加速学习过程)
3.3 离散型变量可以被编码成每一个输入单元对应一个特征值可能赋的值
比如:特征值A可能取三个值(a0, a1, a2), 可以使用3个输入单元来代表A。
如果A=a0, 那么代表a0的单元值就取1, 其他取0;
如果A=a1, 那么代表a1de单元值就取1,其他取0,以此类推
3.4 神经网络即可以用来做分类(classification)问题,也可以解决回归(regression)问题
对于分类问题,如果是2类,可以用一个输出单元表示(0和1分别代表2类)。如果多余2类,每一个类别用一个输出单元表示,所以输入层的单元数量通常等于类别的数量
没有明确的规则来设计最好有多少个隐藏层,根据实验测试和误差,以及准确度来实验并改进
4. 交叉验证方法(Cross-Validation)
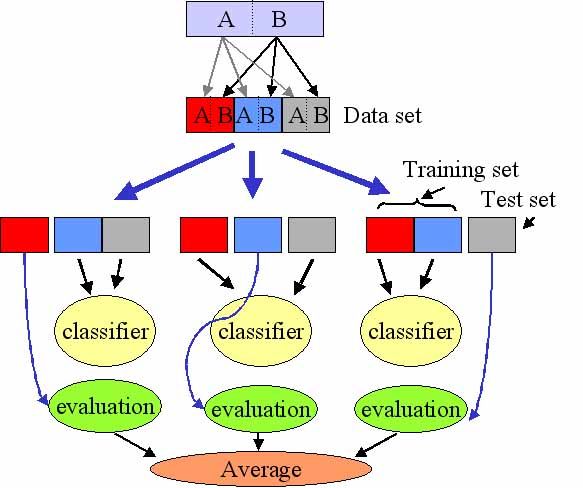
5. Backpropagation算法
5.1 通过迭代性的来处理训练集中的实例
5.2 对比经过神经网络后输入层预测值(predicted value)与真实值(target value)之间
5.3 反方向(从输出层=>隐藏层=>输入层)来以最小化误差(error)来更新每个连接的权重(weight)
5.4 算法详细介绍
输入:D:数据集,l 学习率(learning rate), 一个多层前向神经网络
输入:一个训练好的神经网络(a trained neural network)
初始化权重(weights)和偏向(bias): 随机初始化在-1到1之间,或者-0.5到0.5之间,每个单元有 一个偏向
对于每一个训练实例X,执行以下步骤:
(1)由输入层向前传送

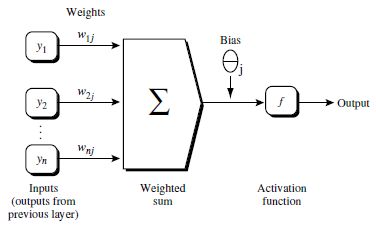
(2) 根据误差(error)反向传送
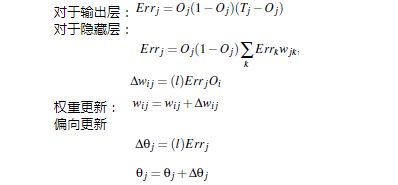
(3) 终止条件
- 权重的更新低于某个阈值
- 预测的错误率低于某个阈值
- 达到预设一定的循环次数
6. Backpropagation 算法举例

7. 关于非线性转化方程(non-linear transformation function)
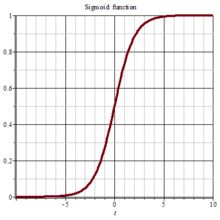
7.1 Sigmoid函数
Sigmoid函数(S 曲线)用来作为activation function:
Sigmoid函数是一个在生物学中常见的S型的函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0,1之间。
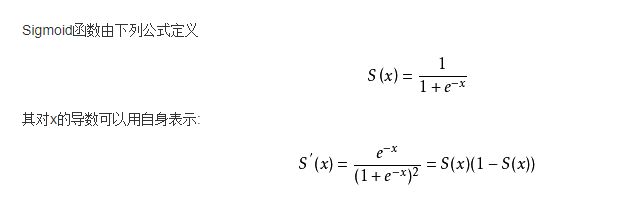
7.2 双曲函数(tanh)
定义:
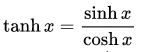
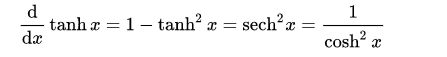
图像:
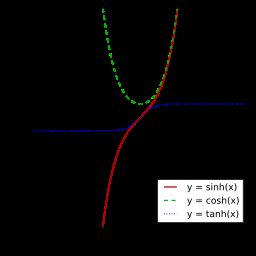
维基百科链接:https://zh.wikipedia.org/wiki/%E5%8F%8C%E6%9B%B2%E5%87%BD%E6%95%B0
7.3 逻辑函数(logistic function)
Logistic函数可用下式表示:

图像:

维基百科链接:
https://en.wikipedia.org/wiki/Logistic_function
https://zh.wikipedia.org/wiki/%E9%82%8F%E8%BC%AF%E5%87%BD%E6%95%B8
8. 用python实现神经网络算法
8.2 编写神经网络算法的一个类NeuralNetwork
import numpy as np
# 双曲函数(tanh)
def tanh(x):
return np.tanh(x)
# 双曲函数(tanh)的导数
def tanh_deriv(x):
return 1.0 - np.tanh(x)*np.tanh(x)
# 逻辑函数(logistic function)
def logistic(x):
return 1/(1 + np.exp(-x))
# 逻辑函数(logistic function)的导数
def logistic_derivative(x):
return logistic(x)*(1-logistic(x))
class NeuralNetwork:
# 默认使用双曲函数
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
# 权重
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25)
# X:数据集,是一个特征值矩阵 ;y:分类标记
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X)
temp = np.ones([X.shape[0], X.shape[1]+1])
temp[:, 0:-1] = X # adding the bias unit to the input layer
X = temp
y = np.array(y)
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)): #going forward network, for each layer
a.append(self.activation(np.dot(a[l], self.weights[l]))) #Computer the node value for each layer (O_i) using activation function
error = y[i] - a[-1] #Computer the error at the top layer
deltas = [error * self.activation_deriv(a[-1])] #For output layer, Err calculation (delta is updated error)
#Staring backprobagation
for l in range(len(a) - 2, 0, -1): # we need to begin at the second to last layer
#Compute the updated error (i,e, deltas) for each node going from top layer to input layer
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0]+1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
8.2 简单非线性关系数据集测试(XOR):
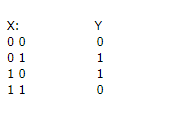
代码:
from NeuralNetwork import NeuralNetwork
import numpy as np
nn = NeuralNetwork([2, 2, 1], 'tanh')
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for i in [[0, 0], [0, 1], [1, 0], [1, 1]]:
print(i, nn.predict(i))
运行结果:
[0, 0] [ 0.00158086]
[0, 1] [ 0.99841709]
[1, 0] [ 0.99839162]
[1, 1] [ 0.01167852]
8.2 手写数字识别:
每个图片8x8
识别数字:0,1,2,3,4,5,6,7,8,9
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
# 每个图片8x8 识别数字:0,1,2,3,4,5,6,7,8,9
import numpy as np
from sklearn.datasets import load_digits
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.preprocessing import LabelBinarizer
from NeuralNetwork import NeuralNetwork
from sklearn.cross_validation import train_test_split
digits = load_digits()
X = digits.data
y = digits.target
X -= X.min() # normalize the values to bring them into the range 0-1
X /= X.max()
nn = NeuralNetwork([64, 100, 10], 'logistic')
X_train, X_test, y_train, y_test = train_test_split(X, y)
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
print("start fitting")
nn.fit(X_train, labels_train, epochs=3000)
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i])
predictions.append(np.argmax(o))
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
运行结果:
[[48 0 0 0 0 0 0 0 0 0]
[ 0 30 0 0 0 0 1 0 4 5]
[ 0 0 45 0 0 0 0 1 0 0]
[ 0 0 1 34 0 0 0 0 2 4]
[ 0 0 0 0 47 0 0 0 0 0]
[ 0 1 0 0 0 36 0 0 0 4]
[ 1 0 0 0 0 0 53 0 0 0]
[ 0 0 0 0 1 0 0 40 0 0]
[ 0 3 0 0 0 0 0 0 42 1]
[ 0 0 0 0 0 0 0 0 1 45]]
precision recall f1-score support
0 0.98 1.00 0.99 48
1 0.88 0.75 0.81 40
2 0.98 0.98 0.98 46
3 1.00 0.83 0.91 41
4 0.98 1.00 0.99 47
5 1.00 0.88 0.94 41
6 0.98 0.98 0.98 54
7 0.98 0.98 0.98 41
8 0.86 0.91 0.88 46
9 0.76 0.98 0.86 46
avg / total 0.94 0.93 0.93 450
【注】:本文为麦子学院机器学习课程的学习笔记