本文翻译自https://nbviewer.jupyter.org/github/justmarkham/pandas-videos/blob/master/top_25_pandas_tricks.ipynb ,翻译如有不当之处,还请批评指正。
首先我们需要先提前下载好示例数据集:
- drinksbycountry.csv : http://bit.ly/drinksbycountry
- imdbratings.csv : http://bit.ly/imdbratings
- chiporders.csv : http://bit.ly/chiporders
- smallstockers.csv : http://bit.ly/smallstocks
- kaggletrain.csv : http://bit.ly/kaggletrain
- uforeports.csv : http://bit.ly/uforeports
利用以下代码导入上述数据集:
1. 显示已安装的版本
输入下面的命令查询pandas版本:
你可以查看到Python,pandas, Numpy, matplotlib等的版本信息。
2. 创建示例DataFrame
假设你需要创建一个示例DataFrame。有很多种实现的途径,我最喜欢的方式是传一个字典给DataFrame constructor,其中字典中的keys为列名,values为列的取值。
你可以想到,你传递的字符串的长度必须与列数相同。
3. 更改列名
让我们来看一下刚才我们创建的示例DataFrame:
4. 行序反转
让我们来看一下drinks这个DataFame:
你可以看到,行序已经反转,索引也被重置为默认的整数序号。
5. 列序反转
跟之前的技巧一样,你也可以使用loc函数将列从左至右反转:
逗号之前的冒号表示选择所有行,逗号之后的::-1表示反转所有的列,这就是为什么country这一列现在在最右边。
6. 通过数据类型选择列
这里有drinks这个DataFrame的数据类型:
7. 将字符型转换为数值型
让我们来创建另一个示例DataFrame: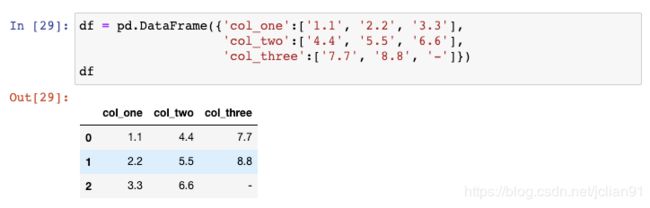
8. 减小DataFrame空间大小
pandas DataFrame被设计成可以适应内存,所以有些时候你可以减小DataFrame的空间大小,让它在你的系统上更好地运行起来。
这是drinks这个DataFrame所占用的空间大小:
通过将continent列读取为category数据类型,我们进一步地把DataFrame的空间大小缩小至2.3KB。
值得注意的是,如果跟行数相比,category数据类型的列数相对较小,那么catefory数据类型可以减小内存占用。
9. 按行从多个文件中构建DataFrame
假设你的数据集分化为多个文件,但是你需要将这些数据集读到一个DataFrame中。
举例来说,我有一些关于股票的小数聚集,每个数据集为单天的CSV文件。这是第一天的:
10. 按列从多个文件中构建DataFrame
上一个技巧对于数据集中每个文件包含行记录很有用。但是如果数据集中的每个文件包含的列信息呢?
这里有一个例子,dinks数据集被划分成两个CSV文件,每个文件包含三列:
现在我们的DataFrame已经有六列了。
11. 从剪贴板中创建DataFrame
假设你将一些数据储存在Excel或者Google Sheet中,你又想要尽快地将他们读取至DataFrame中。
你需要选择这些数据并复制至剪贴板。然后,你可以使用read_clipboard()函数将他们读取至DataFrame中: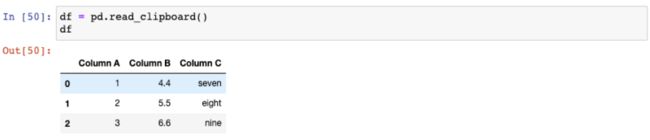
需要注意的是,如果你想要你的工作在未来可复制,那么read_clipboard()并不值得推荐。
12. 将DataFrame划分为两个随机的子集
假设你想要将一个DataFrame划分为两部分,随机地将75%的行给一个DataFrame,剩下的25%的行给另一个DataFrame。
举例来说,我们的movie ratings这个DataFrame有979行:![]()
需要注意的是,这个方法在索引值不唯一的情况下不起作用。读者注:该方法在机器学习或者深度学习中很有用,因为在模型训练前,我们往往需要将全部数据集按某个比例划分成训练集和测试集。该方法既简单又高效,值得学习和尝试。
13. 通过多种类型对DataFrame进行过滤
让我们先看一眼movies这个DataFrame:
这种方法能够起作用是因为在Python中,波浪号表示“not”操作。
14. 从DataFrame中筛选出数量最多的类别
假设你想要对movies这个DataFrame通过genre进行过滤,但是只需要前3个数量最多的genre。
我们对genre使用value_counts()函数,并将它保存成counts(type为Series):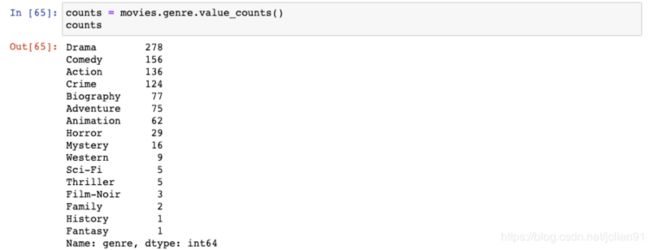
这样,在DataFrame中只剩下Drame, Comdey, Action这三种类型的电影了。
15. 处理缺失值
让我们来看一看UFO sightings这个DataFrame:
len(ufo)返回总行数,我们将它乘以0.9,以告诉pandas保留那些至少90%的值不是缺失值的列。
16. 将一个字符串划分成多个列
我们先创建另一个新的示例DataFrame: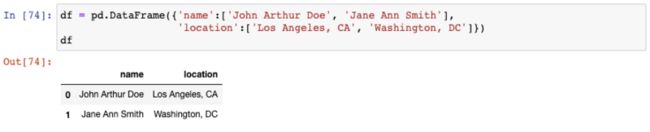
17. 将一个由列表组成的Series扩展成DataFrame
让我们创建一个新的示例DataFrame: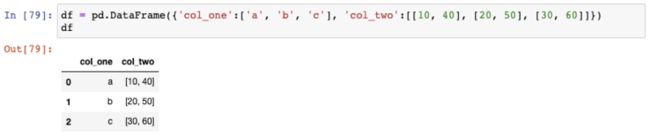
18. 对多个函数进行聚合
让我们来看一眼从Chipotle restaurant chain得到的orders这个DataFrame:
这将告诉我们没定订单的总价格和数量。
19. 将聚合结果与DataFrame进行组合
让我们再看一眼orders这个DataFrame: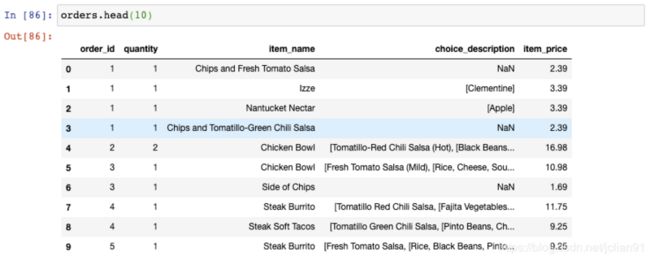
20. 选取行和列的切片
让我们看一眼另一个数据集: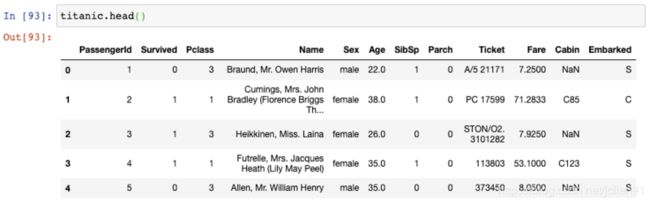
21. 对MultiIndexed Series进行重塑
Titanic数据集的Survived列由1和0组成,因此你可以对这一列计算总的存活率:
该DataFrame包含了与MultiIndexed Series一样的数据,不同的是,现在你可以用熟悉的DataFrame的函数对它进行操作。
22. 创建数据透视表(pivot table)
如果你经常使用上述的方法创建DataFrames,你也许会发现用pivot_table()函数更为便捷:
这个结果展示了每一对类别变量组合后的记录总数。
23. 将连续数据转变成类别数据
让我们来看一下Titanic数据集中的Age那一列:
这会对每个值打上标签。0到18岁的打上标签"child",18-25岁的打上标签"young adult",25到99岁的打上标签“adult”。
注意到,该数据类型为类别变量,该类别变量自动排好序了(有序的类别变量)。
24. 更改显示选项
让我们再来看一眼Titanic 数据集: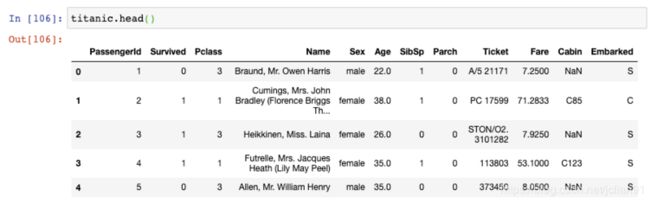
对于其它的选项也是类似的使用方法。
25. Style a DataFrame
上一个技巧在你想要修改整个jupyter notebook中的显示会很有用。但是,一个更灵活和有用的方法是定义特定DataFrame中的格式化(style)。
让我们回到stocks这个DataFrame: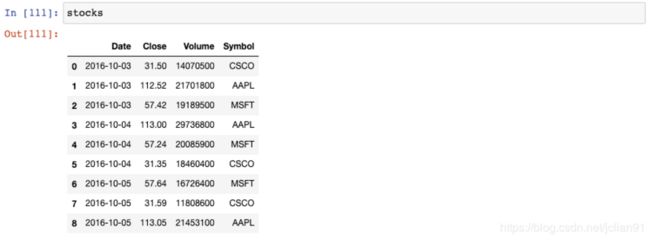
现在,Volumn列上有一个条形图,DataFrame上有一个标题。
请注意,还有许多其他的选项你可以用来格式化DataFrame。
额外技巧:Profile a DataFrame
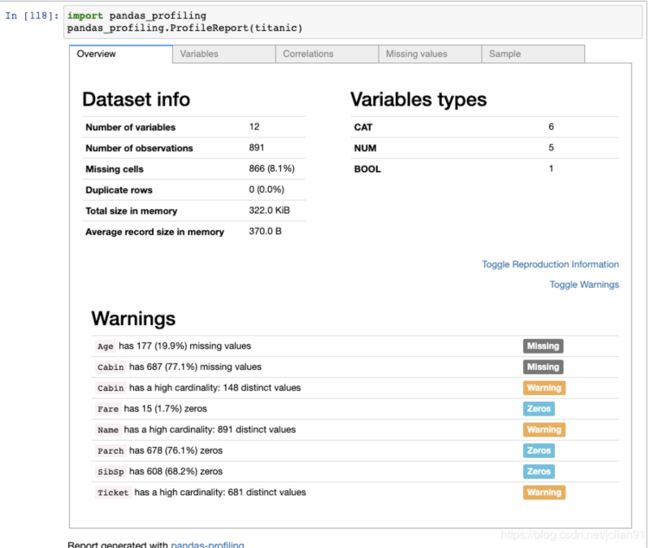
假设你拿到一个新的数据集,你不想要花费太多力气,只是想快速地探索下。那么你可以使用pandas-profiling这个模块。
在你的系统上安装好该模块,然后使用ProfileReport()函数,传递的参数为任何一个DataFrame。它会返回一个互动的HTML报告:
- 第一部分为该数据集的总览,以及该数据集可能出现的问题列表;
- 第二部分为每一列的总结。你可以点击"toggle details"获取更多信息;
- 第三部分显示列之间的关联热力图;
- 第四部分为缺失值情况报告;
- 第五部分显示该数据及的前几行。
使用示例如下(只显示第一部分的报告):
这部分的代码已经放在Github上,网址为:https://github.com/percent4/panas_usage_25_tricks 。
感谢大家的阅读~