一、概述
1、什么是聚类分析
聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。
2、基本的聚类分析算法
(1) K均值:
基于原型的、划分的距离技术,它试图发现用户指定个数(K)的簇。
(2) 凝聚的层次距离:
思想是开始时,每个点都作为一个单点簇,然后,重复的合并两个最靠近的簇,直到尝试单个、包含所有点的簇。
(3) DBSCAN:
一种基于密度的划分距离的算法,簇的个数有算法自动的确定,低密度中的点被视为噪声而忽略,因此其不产生完全聚类。
3、距离度量


4、算法思想
(1)普通算法
K均值算法需要输入待聚类的数据和欲聚类的簇数k,主要的聚类过程有3步:
(1)随机生成k个初始点作为质心
(2)将数据集中的数据按照距离质心的远近分到各个簇中
(3)将各个簇中的数据求平均值,作为新的质心,重复上一步,直到所有的簇不再改变
(2)二分K均值算法
二分K均值算法是K均值算法的改进版。该算法首先将所有的点作为一个簇,然后将该簇一分为二,之后选择其中的一个簇继续划分。选择哪一个簇进行划分取决于对其划分是否可以最大程度的降低误差平方和。重复上述基于误差平方和的划分过程,直到簇数目和指定的k值相等。
二、案列
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
#载入数据
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine))
dataMat.append(fltLine)
return dataMat
#计算距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
#创建初始质点
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))#create centroid mat
for j in range(n):#create random cluster centers, within bounds of each dimension
minJ = min(dataSet[:,j])
maxJ = max(dataSet[:,j])
rangeJ = float(maxJ - minJ)
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
#普通K均值算法
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print (centroids)
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean
return centroids, clusterAssment
#优化K均值算法
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] #create a list with one centroid
for j in range(m):#calc initial Error
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]#get the data points currently in cluster i
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = sum(splitClustAss[:,1])#compare the SSE to the currrent minimum
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print ("sseSplit, and notSplit: ",sseSplit,sseNotSplit)
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print ('the bestCentToSplit is: ',bestCentToSplit)
print ('the len of bestClustAss is: ', len(bestClustAss))
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#replace a centroid with two best centroids
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE
return mat(centList), clusterAssment
#画图
def draw(data,center):
length=len(center)
fig=plt.figure
# 绘制原始数据的散点图
plt.scatter(data[:,0].tolist(),data[:,1].tolist(),s=25,alpha=0.4)
# 绘制簇的质心点
for i in range(length):
plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=(center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='red'))
plt.show()
#main函数
if __name__=="__main__":
dat=mat(loadDataSet('testSet.txt'))
center,clust=kMeans(dat,4)
draw(dat,center)
dat=mat(loadDataSet('testSet2.txt'))
center,assment=biKmeans(dat,3)
draw(dat,center)
结果:
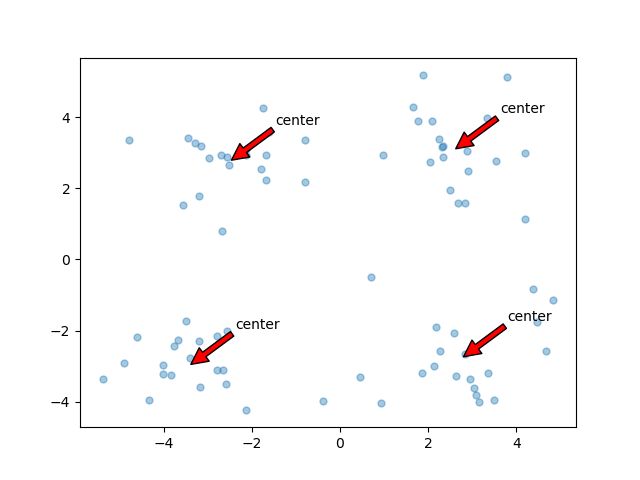
普通算法
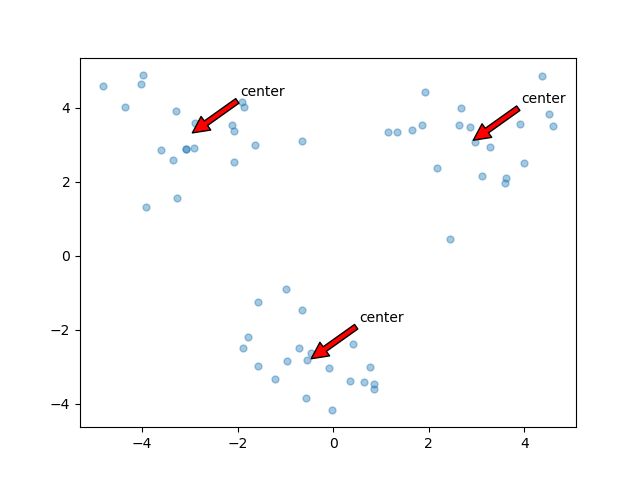
优化算法