问题一:数据库日志文件过大
近期一直在做爬虫,Sql Server数据库读写操作相对频繁,某日突然发现磁盘空间不足,检查发现mdf大概 20G,ldf大概 110G,后使用常规日志压缩、截取等操作,节省空间不明显
检查发现Sql Server 默认恢复模式为完整,会保存所有日志文件,便于数据恢复,正常需要不断备份log之后,才可截断log,因目前日志文件已较为庞大,备份较麻烦,直接将恢复模式修改为简单再进行收缩清理,再设置每天定时自动备份
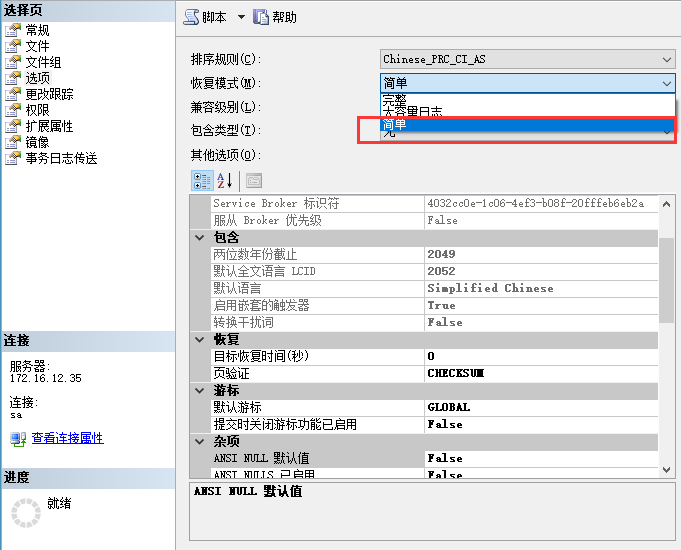
image.png
问题二:查询总条数慢
因监控页面需统计所有爬取数据总数,数据量大表明显统计总条数较慢
image.png
# 常用统计记录数 sql
select count(0) from dt_name
select count(1) from dt_name
select count(ID) from dt_name
因不涉及数据过滤,单纯统计总条数,可使用系统索引表(sysindexes)检索
注:该方法仅适合 不进行数据过滤 的数据统计
#系统索引表统计sql
select rowcnt from sysindexes where id=object_id('dt_name')
分页查询慢
之前使用过程中,针对常用查询字段建立聚集索引,但数据量大后发现普通分页也容易出现查询超时
分析查询sql,发现因为给分页字段ID未建立索引,后续修改为给ID设置为聚集索引,其他常用查询字段设置为非聚集索引
# 查询原始sql
select column_0 as 'SiteCode',column_1 as 'Date',column_2 as 'Hour',
column_3 as 'AQI',column_4 as 'PM2.5',column_6 as 'PM10',
column_8 as 'SO2',column_10 as 'NO2',column_12 as 'O3',
column_14 as 'O3_8h',column_16 as 'CO',ID as '唯一标识' from (
select ROW_NUMBER() OVER(ORDER BY Space0029A.ID DESC ) as rn,
Space0029A.column_0, Space0029A.column_1,Space0029A.column_2,
Space0029A.column_3, Space0029A.column_4, Space0029A.column_6,
Space0029A.column_8, Space0029A.column_10, Space0029A.column_12,
Space0029A.column_14, Space0029A.column_16, Space0029A.ID
from Space0029A where 1=1 )t
where rn<=10 and rn>0
注:
1、聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
2、非连续性内容(文字检索)更适合非聚集索引
数据量大后,修改索引超时
使用界面化操作索引创建,操作超时
使用创建索引Sql创建,注意检查索引字段,等待操作执行即可

创建索引
/*聚集索引*/
/****** Object: Index [ClusteredIndex-20170928-153215] Script Date: 2018/3/29 17:24:35 ******/
CREATE CLUSTERED INDEX [ClusteredIndex-20170928-153215] ON [dbo].[Space0009A]
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
/*非聚集索引*/
/****** Object: Index [NonClusteredIndex-20170928-153215] Script Date: 2018/3/29 17:25:16 ******/
CREATE NONCLUSTERED INDEX [NonClusteredIndex-20170928-153215] ON [dbo].[Space0009A]
(
[column_0] ASC,
[column_1] ASC,
[column_2] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO