一、算法原理
k-nearest neighbor, k-NN是一种可以用于多分类和回归的方法。knn是一个很简单的分类方法。它的工作原理是存在一个样本数据集合(训练样本集),并且样本集中每个数据都存在标签,即我们知道样本集中每一数据域所属分类的对应关系。输入每一标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前 k 个最相似的数据,这就是 k-近邻算法中 k 的出处,通常 k 是不大于 20 的整数。最后,选择 k 个最相似数据中出现次数最多的分类,作为新数据的分类。
通过以上的话已经足够理解k近邻,如果说的再具象一些:
首先,我们需要输入一个这样的数据集T= {(x1,y1),(x2,y2),(x3,y3),···,(xN,yN)}。其中xi是实例的特征向量,yi是xi这个实例对应的类别,有可能是c1,c2,c3,··· , cK。
然后我们要再输入一个需要被分类的实例的特征向量x。再根据给定的某种距离度量,在T中找到与x最接近的k个点。
最后在k个点中根据某种分类的决策规则(例如,哪个类别多就是哪个类别)决定x的类别y。输出x的类别y。
二、示例
基于电影中出现的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,自动划分电影的题材类型。有人统计过很多电影的打斗镜头和接吻镜头,图1显示了 6 部电影的打斗和接吻镜头数。假如有一部未看过的电影,如何确定的它是爱情片还是动作片呢?可以使用 kNN 来解决这个问题:

首先我们需要知道这个未知电影存在多少个打斗镜头和接吻镜头:

计算未知电影与样本集中其他电影的距离:
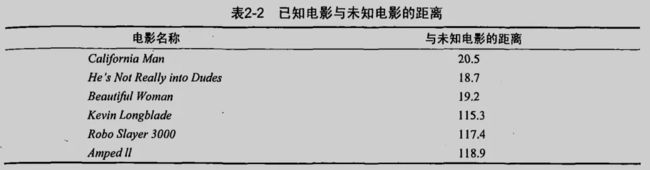
现在得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到 k 个距离最近的电影。假定 k=3 ,则三个最近的电影依次是He...、Bea...、Cal...。k-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影都是爱情片,因此判定未知电影是爱情片。
三、距离量度
特征空间中两个实例点的距离是两个实例点相似程度的反映。k近邻模型的特征空间一般是n维实数向量空间。使用的距离是欧式距离,也可以是其他距离,如更一般的Lp距离。Lp距离:

当p = 2时Lp距离就称为欧氏距离。欧氏距离简单说就是两点的每一个维度的元素分别做差,再求平方和,最后开根号。
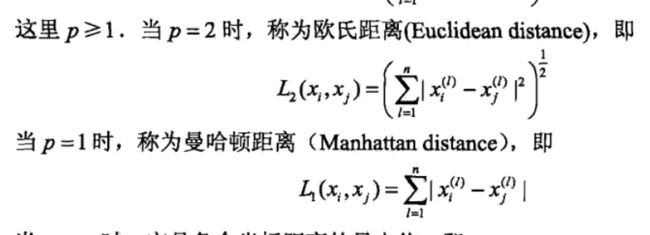
四、k值得选择
K值一般取一个较小的值,通常采用交叉验证法来选取最优的k值。
K值的选择会对k近邻法的结果产生较大的影响。
如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用.但缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错.换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合.
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少学习的估计误差.但缺点是学习的近似误差会增大.这时与输入实例较远的(不相似的)训练实例也会对预测起作用, 使预测发生错误,k 值的增大就意味着整体的模型变得简单。
如果k=N,那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类.这时,模型过于简单,完全忽略训练实例中的大量有用信息, 是不可取的.
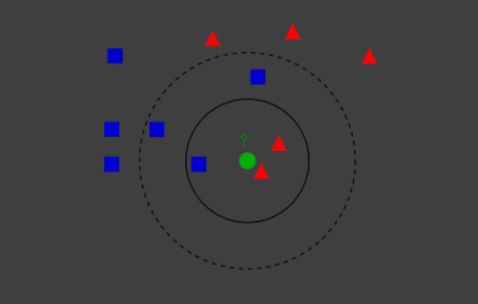
从上图可以看出,k = 3 与 k = 5 时的分类结果是不同的。然而k值并不会在学习过程中自动优化,而是在模型初始化是人为约定好的。因此k值对于k近邻至关重要,需要给予更多的关注。
五、构造kd树
在实现 k近邻时,需要计算输入x与数据集中的每一个xi的距离,从而选择距离最小的k个。当训练集很大或维数很大时,计算会非常耗时。因此为了提高 k近邻的效率,下面介绍kd树方法来存储训练数据,减少计算次数。
kd树是对k维空间中的实例点进行存储以便对其快速检索的二叉树数据结构,表示对k维空间的一种划分。
构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个节点对应于一个k维超矩形区域。
构造算法:

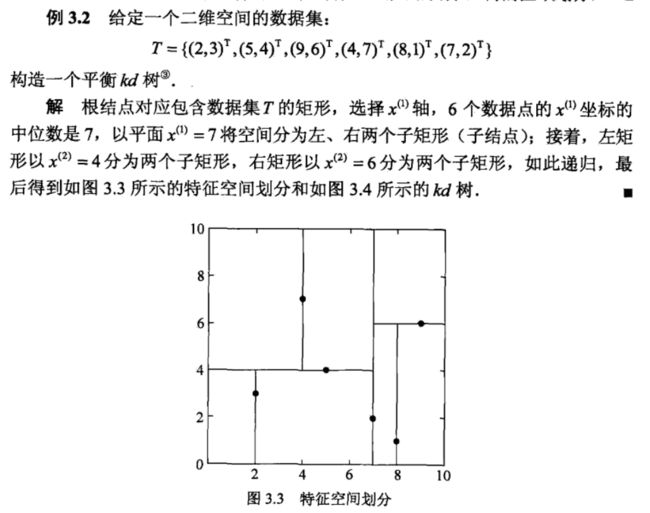
例题:
六、用kd树的最近邻搜索
给定一个目标点,搜索其最近邻。首先找到包含目标点的叶结点。然后从该叶结点出发,依次回退到父结点。不断查找与目标点最邻近的结点,当确定不可能存在更近的结点时终止. 这样搜索就被限制在空间的局部区域上,效率大为提高。
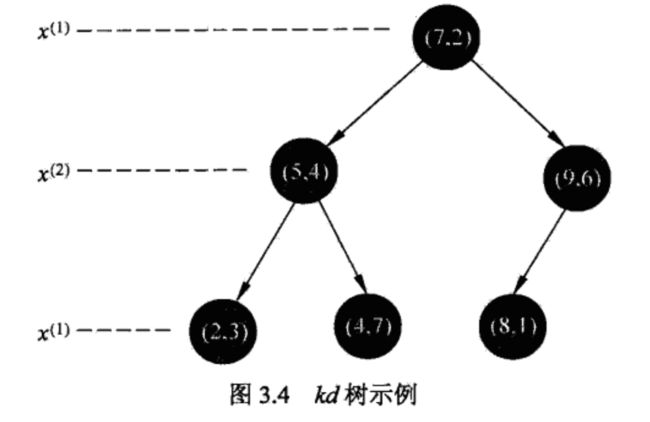
包含目标点的叶结点对应包含目标点的最小超矩形区域。以此叶结点的实例点作为当前最近点,目标点的最近邻一定在以目标点为中心并通过当前最近点的超球体的内部。然后返回当前结点的父结点,如果父结点的另一子结点的超矩形区域与超球体相交,那么在相交的区域内寻找与目标点更近的实例点,如果存在这样的点,将此点作为新的当前最近点。算法转到更上一级的父结点,继续上述过程。如果父结点的另一子结点的超矩形区域与超球体不相交,或不存在比当前最近点更近的点,则停止搜索。
例题:
七、在CIFAR-10数据集上使用k近邻算法给测试图片进行分类

训练集和测试集分别有50000和10000张图片,RGB3通道,尺寸32×32,如下为data_batch_1的组成(使用pickle.load函数):
KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
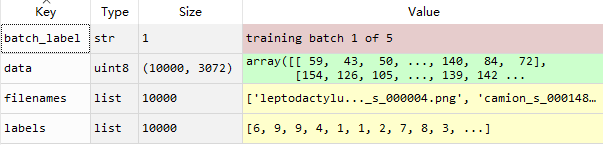
计算测试图片与训练集图片的距离:
测试结果:
根据测试结果发现,例如第一个卡车图片,在给出的最近距离的10(即k)个图片中,船的图片占五个,根据少数服从多数,会给出错误的分类。因此直接计算距离找出K个最近距离的图片,这种方法不是很准确。
优化方法:
问题:

那么该如何选取一组最优的参数呢(距离、K值等其他超参数)?(组合最优)
1、选取一组超参数的正确方法是:将原始训练集分为训练集和验证集,在验证集上尝试不同的超参数,最后保留那个最好的。
2、如果训练数据量不够,使用交叉验证法,他能帮我们在选取最优参数时减少噪音。
3、一旦找到最优参数,就让算法以该参数在测试集跑且跑一次,根据测试结果评价算法。
4、预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值( zero mean)和单位方差( unit variance)。
5、如果数据是高维数据,考虑使用降维方法,比如PCA
6、将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集
7、在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。

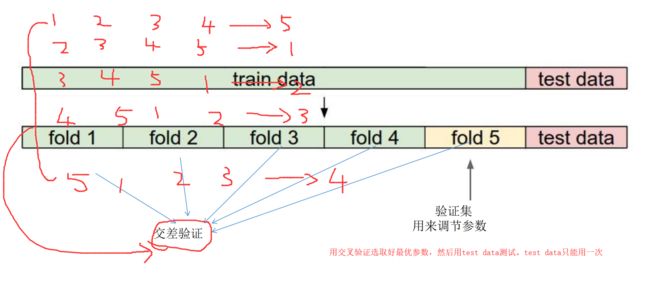
例如上图,我们可以随意选择train data集中的一个作为验证集。但是分的五个验证集不是很均匀,或者某个验证集存在问题,如fold 5数据集过于简单,拿它验证,结果会偏高,如fold 1数据集存在误差值、异常值,会导致结果偏低。所以我们最好进行五次迭代,分别拿不同的fold作为验证集,把五次迭代的结果求和再求平均值。可以消除偏高和偏低的结果,使评估模型变得科学。所以交叉验证方法真的很实用。
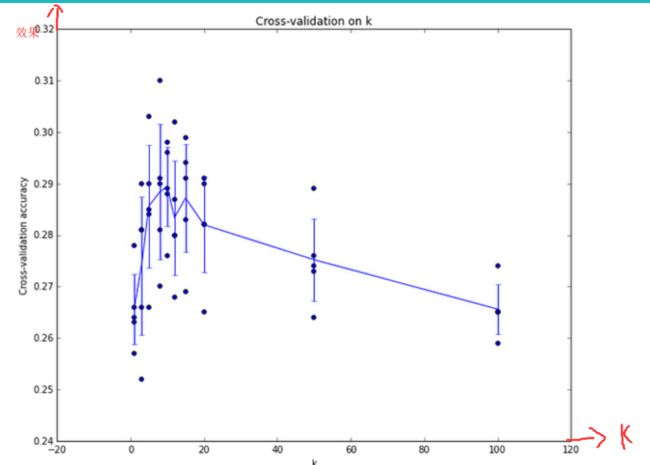
采用交叉验证得出不同的准确率时的k值。如下:
八、采用k近邻分类存在缺陷
1、 最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于耗费计算能力。
2、整张图片中,主体占很小,背景很大,计算距离时容易造成错误(背景主导)
3、不同的变换和原图具有相同的L2距离
