版本: 2.3.0 - 2.6.0
http://spark.apache.org/docs/latest/spark-standalone.html
- Installing Spark Standalone to a Cluster
- Starting a Cluster Manually
- Cluster Launch Scripts
- Connecting an Application to the Cluster
- Launching Spark Applications
- Resource Scheduling
- Executors Scheduling
- Monitoring and Logging
- Running Alongside Hadoop
- Configuring Ports for Network Security
- High Availability
- Standby Masters with ZooKeeper
- Single-Node Recovery with Local File System
spark除了可以在Mesos 或Yarn上运行, 也可以以standalone模式运行。
可以手工启动master 和workers 或者通过官方提供的启动脚本来进行 launch scripts.
Standalone模式下手工启动
手工启动master
./sbin/start-master.sh
启动时, master 会打印出 spark://HOST:PORT URL 。 这是master的 web UI 。
默认端口8080 。
手工启动一个或多个workers , 并连接到master:
./sbin/start-slave.sh
启动worker后, 可以在master的UI上查看到他,及为之分配的资源。
最后,如下选项可以传给master 和worker :

conf/spark-env.sh
拷贝conf/spark-env.sh.template 为 conf/spark-env.sh , 并将该文件同步到所有的机器上。
配置属性有如下:
| Environment Variable | Meaning |
|---|---|
| SPARK_MASTER_HOST | 指定master的主机名或ip . |
| SPARK_MASTER_PORT | 指定master的端口 (default: 7077). |
| SPARK_MASTER_WEBUI_PORT | master web UI 端口 (default: 8080). |
| SPARK_MASTER_OPTS | 以 "-Dx=y" (default: none)的格式配置只对master启动生效的参数. 参数选项见下 |
| SPARK_LOCAL_DIRS | Spark的 "scratch"目录, 包括映射output文件 和 RDDs。该目录应该是一个本地系统的快速目录. 它也可以是以逗号分隔的位于不同磁盘的目录列表. |
| SPARK_WORKER_CORES | 机器上运行spark应用程序使用的总共的cores (default: all available cores). |
| SPARK_WORKER_MEMORY | 机器上运行spark应用程序的总共的内存, e.g. 1000m, 2g (default: 最小 1 GB); 注意每个应用程序单独的内存使用spark.executor.memory 属性配置 |
| SPARK_WORKER_PORT | 指定Spark worker的端口 (default: random). |
| SPARK_WORKER_WEBUI_PORT | worker web UI 端口(default: 8081). |
| SPARK_WORKER_DIR | 应用程序运行的目录,包括 logs and scratch space (default: SPARK_HOME/work). |
| SPARK_WORKER_OPTS | 以 "-Dx=y" (default: none)格式配置worker启动参数 . See below for a list of possible options. |
| SPARK_DAEMON_MEMORY | 分配给Spark master and worker 守护进程本身的内存(default: 1g). |
| SPARK_DAEMON_JAVA_OPTS | 以 "-Dx=y" (default: none)格式启动master 和worker的守护进程的JVM 参数. |
| SPARK_DAEMON_CLASSPATH | Spark master and worker 守护进程本身的CLASSPATH (default: none). |
| SPARK_PUBLIC_DNS | Spark master and workers的默认DNS (default: none). |
Note: 该启动脚本目前不支持 Windows. 在 Windows下启动spark 需要手工启动master 和worker 。
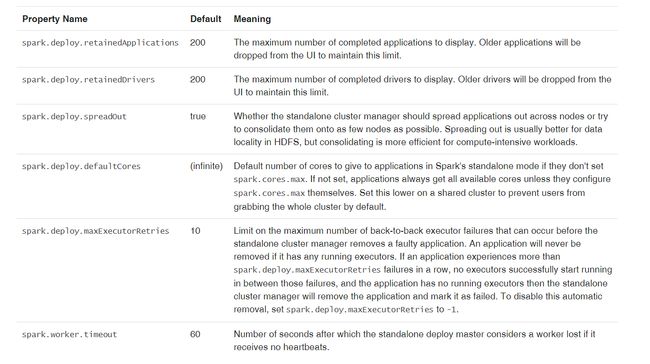
SPARK_MASTER_OPTS 支持的选项
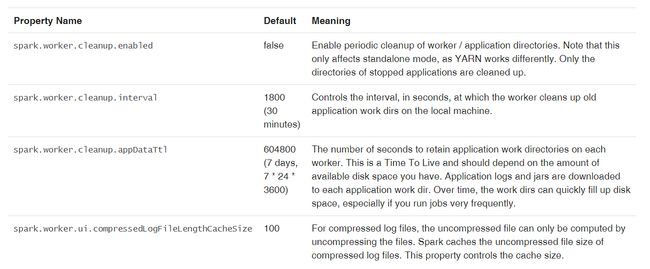
SPARK_WORKER_OPTS 支持的选项
连接集群
要连接spark集群, 传送 master 的 spark://IP:PORT URL 。
./bin/spark-shell --master spark://IP:PORT
可以通过输入 --total-executor-cores 选项来控制 spark-shell使用的cores数量。
启动spark 应用程序
spark-submit脚本提供提交spark应用程序到集群。 对于standalone集群, 当前支持两种部署模式, client 模式和 cluster 模式 。 client 模式下, dirver 进程同client进程。 cluster 模式下,driver有集群的摸个worder 进程启动, 客户端进程在提交成功后不会等待执行完成就会推出。
当使用spark-submit提交应用程序, 应用程序jar会自动分发给集群中的所有的worker 。 对于所有的依赖jar , 需要通过--jar参数指定, 使用逗号分隔。 要控制应用程序的配置或者执行环境,参见 Spark Configuration.
另外, standalone集群下,若应用程序返回非0code,支持自动重启应用程序 。 要使用该功能, 需要使用--supervise选项。 若你想关闭重复失败的应用程序, 使用如下:
./bin/spark-class org.apache.spark.deploy.Client kill
driver ID 可用通过master的 web ui http://
资源调度
standalone模型目前只支持FIFO调度。 但是,为运行多用户并行,可以控制每个应用程序使用的最大资源。 默认情况下, 当一次只运行一个应用程序,它将获取所有的cores。你可以在 SparkConf.中通过设置spark.cores.max来限制cores的数量。 例如:
val conf = new SparkConf()
.setMaster(...)
.setAppName(...)
.set("spark.cores.max", "10")
val sc = new SparkContext(conf)
另外,为防止未设置spark.cores.max的情况, 可以在master进程中设置 spark.deploy.defaultcores属性来设置默认值。 可以在spark-env.sh中配置如下:
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=
这对于用户没有单独配置最大内核数量的共享集群非常有用。
Executors 调度
分配给每个executor的cores是可以配置的 。 当明确设置spark.executor.cores 时, 同一个worker可在资源充足的情况下为同一应用程序启动多个executor 。 否则,每个executor默认获取所有的cores ,这种情况下一个应用程序只会启动一个executor。
监控和日志
standalone模型提供一个机遇web的用户界面来监控集群。 master 和每个worker都有各自的web UI 来显示集群和job统计信息 。 默认情况下可以通过8080端口访问master 。
另外,每个job的详细日志信息会保存在每个节点上(默认SPARK_HOME/work )。 每个job有两个, stdout 和stderr 。
在Hadoop上运行
可以在已经存在的hadoop集群上启动spark 。 通过hdfs://URL访问hadoop数据。 或者可以搭建单独的spark集群,通过网络访问hdfs (这将比访问本地磁盘慢, 但是如果在同一局域网可能会快些)。
HA
默认情况下, standalone集群对worker节点的失效有弹性的(spark本身可以将工作交给其他worker)。 但是对于master 是没有弹性的, 会产生单点故障,有两种解决方案。
基于zk的备用master
概览
基于ZK的选举机制和状态存储, 可以启动多个master ,其他一个会被选中为leader ,其他的处于备用状态。 当leader 失效, zk会自动进行选举,然后恢复调度。 整个恢复过程可能会1-2分钟。 注意该延迟只会影响新应用程序的调度,不会影响已经运行了的。
更多信息参见 ZooKeeper here.
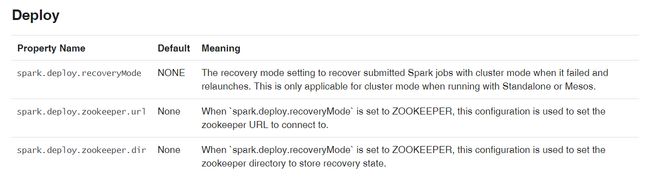
配置
要启用该配置, 在spark-env.sh中设置属性 SPARK_DAEMON_JAVA_OPTS 为 spark.deploy.recoveryMode and related spark.deploy.zookeeper.*
更多配置信息参见 configuration doc 。
注意: 如果没有正确进行zk配置, 所有的master都认为自己是leader ,就会造成集群状态不正常(所有的master都独立调度)。
详细信息
为了向集群提交新应用或增加worker , 就需要知道leader的ip地址。 这可以通过上送masters的列表进行。 例如:spark://host1:port1,host2:port2. 这样SparkContext会向两个master进行注册, 若host1失效,该配置仍旧有效。
当集群启动时, 应用或worker需要能够找到并注册当前的lead master 。 一旦成功注册,就好存储在zk中。 当失效发生, 新leader 会联系已注册的所有的应用和worker ,通知他们更新leader 信息 , 所以他们不需要知道新master出现。
基于该属性, 新master 可以在任何时间创建, 唯一需要担心的是新应用和worker可以找到并注册到该新master(当他变为leader时)。
基于本地文件系统的单节点恢复
概览
zk是最好的ha方式。 但若你向在master失效时重启之,就可以使用FILESYSTEM 模式 。 当应用和worker注册时, 他们向提供的目录中写状态,以便在master 重启时恢复。
配置
在 spark-env.sh中配置 SPARK_DAEMON_JAVA_OPTS 属性如下:
