8.1 session与cookie
首先要理解session和cookie的区别,这是理解模拟登录和网站交互的基础。
cookie是浏览器支持的本地存储方式,是以dict键值对的方式存储的,在浏览器文件中是文本的形式,浏览器会对这个文本进行解析。
Http本身是一种无状态协议,服务器在接收到浏览器的请求之后,直接返回内容给浏览器,不管浏览器是谁请求的。比如浏览新闻的网站,不在乎是谁发起的浏览请求。但是对于像淘宝这种需要记住请求是由哪个对象发起的时候,无状态协议就不能做到了。
有状态请求如下:

cookie的作用就是在浏览器A访问服务器的时候,就给这个A一个id,浏览器会将这个id保存到本地,cookie中,后来的请求都会带着这个id,浏览器就会知道是哪个对象。浏览器为了安全性,cookie存储是有很多要求的,比如服务器A传过来的cookie是放在服务器A的域之下的,是不能跨域访问的,这是一种安全机制。
当你使用浏览器访问一个网站的时候,可能就会返回cookie内容,如果将cookie清空,再次访问,还是有信息传回来,所以说,cookie是服务器传给浏览器的,并且保存在本地。比如用处就是,当一个用户用登录名密码登陆后,服务器将这些信息作为cookie返回了,下一次登录的时候就可以从本地自动获取信息进行登录,不需要再输用户名和密码了。但是,同时也就出现了安全隐患,只要有人拿着电脑,就能从本地cookie中查看信息浏览记录等。
有状态请求中,第一次请求后发现没有id,服务器就会分配一个id,这个id可以是userid,也可以是任意一段随机的字符串,可以叫做sessionid。每个框架生成session的机制是不一样的,
为了解决cookie的泄露隐患,就产生了session,比如说用户注册登录之后,根据它的用户名和密码名生成sessionid,并且将这个id发给用户,浏览器将这个sessionid存在cookie中,然后再次请求服务器的时候,服务器就知道是谁在请求,取出这个用户对应的信息。
8.2 cookie与session的主要区别
- cookie是第一次打开浏览器返回信息,关闭了浏览器下一次再打开浏览器时可以携带从本地cookie中获取的信息,从而知道是同一个浏览器。而session是在一次打开浏览器之后的连续操作中,通过服务器给了指定的会话id,必须每次访问网址时都携带这个sessionid,服务器才知道这个上一个操作是同一个人在完成。
- cookie是需要去本地获取,session是会话过程中自动携带的。
- cookie是存放在客户端的,session是存在服务器端的。
服务器中识别同一个操作对象的原理:
服务器中可能有一张session表来记录访问的对象,有session_id,session_data,以及过期时间,如果当前没有浏览器正在访问这个网站,那么session表就为空。如果有账号登录成功,这个表中就会有一条记录,有服务器给用户返回的id,有用户的加密后的数据等。这个sessionid会返回给浏览器,保存在cookie当中,后面浏览器在对这个网站的页面进行访问的时候都会带着sessionid,然后服务器就不需要知道你的用户名和密码,就知道是哪个用户了。尽管sessionid放在cookie中虽然有过期时间,但是也不安全的,坏人获取了sessionid就能浏览你的信息了,可是相对于cookie中的账号名密码这种而言,还是安全的多,至少需要用sessionid模拟登录又或者必须会盗用sessionid。所以,浏览网站最后需要退出登录,就会清空sessionid信息了。
ssesion技术本身有两部分:
- 知道浏览器两次访问是同一个人,这是用cookie 保存sessionid实现的
- 在服务端的session对象的内容,可以访问到,这些变量信息时存在服务器的中的。
8.3 selenium模拟知乎登录
selenium动态网页登录,用浏览器的driver去模拟登录,登录了之后获取cookie,拿到scrapy的request中使用。
selenium是一个自动化测试框架,网站系统开发的自动化测试工具,它的测试直接运行在浏览器,像真正的用户在操作一样。selenium的核心是用JavaScript操作浏览器。
-
回归测试:修改了某一功能之后,就要去将系统的所有功能测试一遍,哪怕只修改了一个小地方。
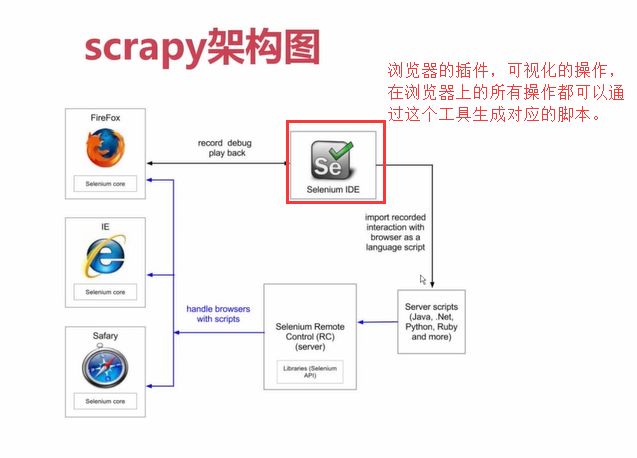
selenium操纵浏览器之间都是有一个driver的,需要下载与浏览器对应的driver
8.3.1 编写python代码使selenium去操纵浏览器网页:
- 进入虚拟环境安装selenium插件
pip install selenium
开发文档地址:https://selenium-python.readthedocs.io/api.html - 下载chrom对应的driver,网址:https://chromedriver.storage.googleapis.com/index.html?path=2.41/
- 编写代码启动selenium,运行结果正确的话应该是弹出新的浏览器,并且进入网页,控制台会打印出这个页面的html内容。
from selenium import webdriver
browser = webdriver.Chrome(executable_path="D:/PycharmProjects/chromedriver.exe")
browser.get("https://www.baidu.com")
# browser.page_source就是运行js之后F12看到的html页面
print(browser.page_source)
若弹出的浏览器界面出现这个内容:Data:,,可能的问题有chrom版本与driver的版本不对应,将chrom更新为最新版本即可。
from selenium import webdriver
from scrapy.selector import Selector
browser = webdriver.Chrome(executable_path="D:/PycharmProjects/chromedriver.exe")
browser.get("https://www.baidu.com")
# browser.page_source就是运行js之后F12看到的html页面
print(browser.page_source)
# selenium提供了元素查找,各种类型,by id/css/name等,就是将之间的选择操作变成了函数,而不是自己去写xpath等,但是不建议使用这些方法
# 因为selenium是纯python写的,速度比不上scrapy的selector,但有的时候还是会用,比如获取到某个元素之后,使用button点击操控
# 但是对页面元素提取还是建议selector
# browser.find_element()
t_selector = Selector(text=browser.page_source)
t_selector.css("...这里是选择代码...")
browser.quit()
# 浏览器中查看网页源代码和F12看到的检查网页html内容是不一样,F12包括了js等修改后的网页内容
# 不同平台上不同浏览器的启动速度是有区别的
8.3.2 selenium模拟知乎登录具体操作
报错信息:Missing argument grant_type
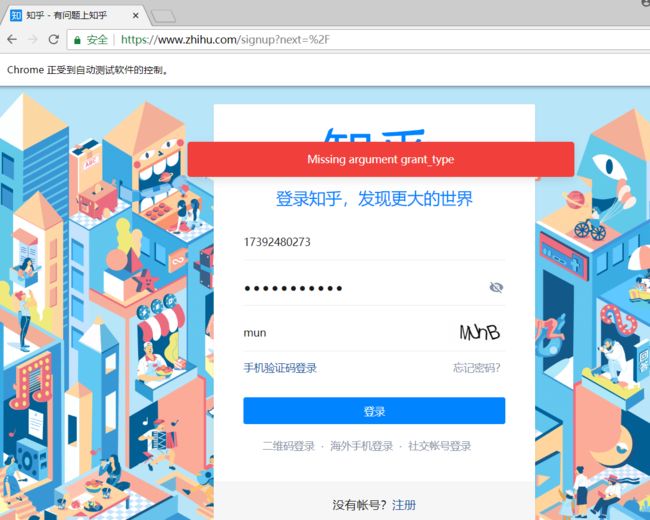
解决办法:下载PhantomJS,地址:http://phantomjs.org/download.html
PhantomJS是一个基于WebKit的服务器端JavaScript API,相当于只是一个没有可视化界面的driver,所以修改一行代码
browser = webdriver.PhantomJS(executable_path="D:/PycharmProjects/phantomjs-2.1.1-windows/bin/phantomjs.exe")。
一是登录知乎,二是学会如何用selenium爬取到网站之后能够把cookie交给scrapy的request使用
import time
import scrapy
import pickle
from selenium import webdriver
from scrapy.selector import Selector
from scrapy.http import Request
browser = webdriver.PhantomJS(executable_path="D:/PycharmProjects/phantomjs-2.1.1-windows/bin/phantomjs.exe")
browser.get("https://www.zhihu.com/signup?next=%2F")
browser.find_element_by_css_selector(".SignContainer-switch span").click()
browser.find_element_by_css_selector(".SignFlow-accountInput input[name='username']").send_keys("17392480273")
browser.find_element_by_name("password").send_keys("48298847zyy")
browser.find_element_by_css_selector(".SignFlow-submitButton").click()
print(browser.page_source)
# 模拟登录,点击登录成功之后就会立马跳转到首页,这个时候已经能获取到浏览器的cookie了,就可以用来作为验证用户的登录了,所以需要先sleep10秒,然后去获得它的cookie。
time.sleep(10)
Cookies = browser.get_cookies() # 接下来会把cookie写入文件之中
# 写入文件的好处就是下一次登录知乎的时候就不需要再登录一遍,只需要在文件中将cookie load进来,然后scrapy的request
print(Cookies)
cookie_dict={}
for cookie in Cookies:
# 写入文件
f = open('D:/PycharmProjects/ArticleSpider/cookies/zhihu/'+cookie['name']+'.zhihu','wb')
pickle.dump(cookie,f)
f.close()
cookie_dict[cookie['name']] = cookie['value']
browser.close()
# 模拟登录完成之后,就可以去请求知乎的首页,比如start_urls中的首页,dont_filter这个参数表示不会被知乎过滤掉,cookies即装了cookies身份信息
res= scrapy.Request(url='https://www.zhihu.com/',dont_filter=True,cookies=cookie_dict)
# 注意一定要在settings.py文件中,将COOKIES_ENABLE置为true
# 好处就是,request请求首页的时候会传递cookie参数,true的话,后面的知乎页面就不需要再传递,默认把cookie添加上
print("已经请求")
8.3.3 常见http code
- 200 请求被成功处理
- 301/302 永久性重定向/临时性重定向
永久重定向:之前网站的域名修改了,访问原来网页的时候重定向到新的网页;临时重定向比如未登录时想进入个人页面,就临时重定向到登录页面- 403 没有访问权限
- 404 表示没有对应的资源 比如自己输入的url不合法
- 500 服务器错误 代码出错没有捕获异常
- 503 服务器停机或正在维护
8.4 通过Request解决知乎登录
selenium模拟登录的时候只需要在相应的输入框内输入账号信息即可,若使用后台请求的方式,则需要弄清楚post的内容以及格式。根据网络状态来分析登录的时候post什么数据过去,以及post到哪个url。
需要分析登录账号,输入内容的时候,需要对哪个页面进行请求,以及post账号名以及密码等。想查看到底请求了哪个页面,可以通过错误的账号密码来查看,因为如果输入正确的账号信息,那么就会立马请求其他资源。
这一部分是对知乎改版前的内容,没有办法实践,后面会采用selenium模拟知乎登录来解决,但是这种requests方法也需要了解学习。对于老版的知乎,用手机号和邮箱号登录时请求的页面都不一样,输入错误的密码点击登录之后,post了三个参数,用户名、密码以及_xsrf,开发web系统为了保证网站安全,防止用户srf攻击的一个状态码,每次访问网站都会随机给你个状态码,必须将_xsrf和账户名密码一起传递过去才会成功。否则会报403错误,没有权限访问。所以对于老板的知乎登录,必须首先判断输入账户是什么类型的,以及xsrf值,可以从登录页面的html内容中获取。拿到三个数据,就可以对服务器作post,之后服务器就会返回cookie,在下一次访问的时候就会携带cookie中的内容,让服务器识别用户。
以下代码现在已无法测试,但是要学会这种post账户和密码来模拟登录的方法,最重要的就是登录完成之后获得cookie供后续登录以及爬取数据。
import requests
# python自带的,可以通过读本地的cookie文件,生成cookie并且附给requests的cookie
try:
import cookielib # python2
except:
import http.cookiejar as cookielib # 3
# 这种写法是python2和3的兼容写法
import re
# 使用requests的session实例化一个变量,有了这个库,每次请求都不需要request了,可以直接使用session,session表示的是某一次连接
# 有了session就不需要每次请求页面都去建立一次连接,效率更高
session = requests.session()
session.cookies = cookielib.LWPCookieJar(filename="cookies.txt")
# 经过cookielib的LWPCookieJar实例化的cookie才可以直接save
try:
session.cookies.load(ignore_discard=True)
except:
print("cookie未能正常加载")
# 注意直接使用request访问知乎页面想得到response可能得不到,原因是服务器有时候会做一些检查,判断是否属于浏览器代理发送的请求
# 所以我们需要设置代理身份
agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
header ={
"HOST":"www.zhihu.com",
"Referer":"https://www.zhihu.com",
"User-Agent":agent
}
def get_xsrf():
# 获取xsrf code
response = session.get("https://www.zhihu.com",headers=header)
match_obj = re.match('.*name="_xsrf" value="(.*?)"',response.text)
if match_obj:
return (match_obj.group(1))
else:
return ""
def is_login():
# 通过个人中心页面返回状态码来判断是否为登录状态
inbox_url = "https://www.zhihu.con/inbox"
response = session.get(inbox_url,headers = header,allow_redirects = False)
# 一般访问一个无权限的页面,如果allow_redirects为true的话,就会返回重定向之后页面的状态码,那肯定是200,就不能判断了
if response.status_code != 200:
return False
else:
return True
def get_index():
response = session.get("https://www.zhihu.com",headers = header)
# 把知乎首页文件存下来,写文件的时候一般要将unicode转化为utf8
with open("index_page.html","wb") as f:
f.write(response.text.encode("utf-8"))
print("ok")
def zhihu_login(account, passwd):
# 知乎登录
if re.match('1\d{10}',account):
print("手机号码登录")
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf":get_xsrf(),
"phone_num":account,
"password":passwd
}
else:
if "@" in account:
print("邮箱账号登录")
post_url = "https://www.zhihu.com/login/email"
post_data = {
"_xsrf": get_xsrf(),
"email": account,
"password": passwd
}
# 模拟登录不是直接使用request中的post方法,而是session
response_text = session.post(post_url, data=post_data, headers=header)
# 可以直接调用方法存下session中的cookie,将服务器返回来的cookie保存到本地,以后再登录知乎就不需要再获取cookie
session.cookies.save()
# 测试登录
# zhihu_login("手机号账户","密码")
# 第一次测试登录完成之后,就不需要再登录了,直接使用现成的cookie进入首页访问即可
# get_index()
以上就是requests完成模拟登录的方式,最后还有一个问题,如何判断用户是否是登录状态:
- 虽然对cookie进行了加载,但是第一,cookie是会失效的,第二,某些页面在登录之前可以判断用户是否已经登录。判断方法是通过,网站内某些页面是必须登录了才能进入的,否则就会显示302无权限访问,并且重定向到登录页面,因此只要访问这样的需要权限的页面,就能判断是否已经登录。
8.5 scrapy模拟知乎登录
- 首先先建立一个关于zhihu的spider,在项目工作目录以及虚拟环境下,命令
scrapy genspider zhihu www.zhihu.com - 重写start_requests()这个方法:
知乎和伯乐在线不一样,未登录状态下是无法看到数据的, 所以想要爬取知乎数据,第一步就是登录,ZhihuSpider(scrapy.Spider)是继承了spider这个类的,必须重写start_requests()这个方法,才能实现
import scrapy
import re
import json
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
headers = {
"HOST":"www.zhihu.com",
"Referer":"https://www.zhihu.com",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
def parse(self, response):
# 正常登录了之后就可以在这里完成数据解析
pass
def parse_detail(self,response):
# 进一步的解析
pass
def start_requests(self):
# 直接调用scrapy的异步ui,获得页面,需要设置回调函数,如果不设置回调函数,默认就会回到parse函数
return [scrapy.Request('https://www.zhihu.com/signup?next=%2F',headers=self.headers,callback=self.login)]
def login(self,response):
response_text = response.text
match_obj = re.match('.*name="_xsrf" value="(.*?)"', response.text,re.DOTALL)
# 正则表达式的规则对于一段文本,默认只匹配第一行
xsrf = ''
if match_obj:
xsrf = match_obj.group(1)
# spider的入口,必须先登录,FormRequest可以完成表单提交
if xsrf: # 如果获取不到这个xsrf码的话,就没必要登录了
post_url = "https://www.zhihu.com/api/v3/oauth/sign_in"
post_data = {
"_xsrf": xsrf,
"phone_num": "17392480273",
"password": "48298847zyy"
}
return [scrapy.FormRequest(
url= post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)]
def check_login(self,response):
# 验证服务器的返回数据判断是否成功
# 登录成功后不需要传入cookie,scrapy会默认在后面的访问中都携带cookie
text_json = json.loads(response.text)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url,dont_filter=True, headers=self.headers)
# 原理的这个self.make_requests_from_url(url)没有headeres逻辑,需要自己写,scrapy.Request如果没有写回调函数,都会去默认的parse函数中执行
"""
这里面的每一步request。我们要对它的下一步做处理,就要有callback,与python中的库request是不一样的,request库是一种同步操作,可以等其将结果返回之后再进行下一步动作
而scrapy是基于twisted框架的,所有的操作都是异步的,所以需要设置回调函数,,可以有个函数专门验证是否login成功
想要获取_xsrf,所以第一步获取首页的html信息,有两种方式:
第一种简单的,通过request请求
第二种使用scrapy提供的异步UI,直接return
"""
8.6 知乎数据存储的item设计
分析知乎数据表的结构以及设计item,知乎中只需要爬取问题以及这个问题相关的回答。知乎网站在刚开始改变样式改版的时候,可能有的问题网页是用旧版的css,有的又是新版的css,所以还必须两手操作,才能正确的解析。
8.6.1 如何在命令行中下载一个页面
如何查看旧版的页面呢,可以用scrapy shell命令。
当直接使用scrapy shell HTTPS://www.zhihu.com/question/56320032/answer/149034527直接运行可能会报500的错误,必须给它加一个header,那如何在scrapy shell,命令中添加user-agent呢。scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36" https://www.zhihu.com/question/56320032/answer/149034527,现在就能得到一个200的页面了。将返回的内容写入一个html文件中,with open("d:/zhihu.html","wb") as f: f.write(response.text.encode("utf-8"))再用浏览器打开这个文件就能查看这个页面是知乎新版本还是旧版本了。通过查看发现,应该都更换成新版了,就是问题下的回答都是通过展开的方式查看。
知乎在未登录状态下是可以访问某些问题的url的,既然未登录也能看到问题,为什么要登录呢,原因是登录状态下能看到首页的内容比较多,可以通过首页的问题url,深度挖掘跟踪获取更多的内容。第二,模拟登录时很重要的一块,有些网站在未登录状态下什么都无法查看。
安装jsonview插件,可以在chrom浏览器中看到排版整齐的数据。
8.6.2 分析知乎问答网站答案的设计
知乎回答的链接设计很有意思,当进入一个问题之后,点击查看剩余的几百条回答时,可以看到去请求了某一链接,这个链接有两个参数需要注意,limit和offset,limit表示一次请求最大回答条数,offset表示偏移量,当前从第几条开始的多少条内容,直接发送url请求就能获得返回来的数据,并且是json格式的,更利于解析,都不需要使用网页选择器等,直接将返回的数据进行筛选。paging里面的is_end参数说明了这是不是最后一条回答数据url,is_end=true说明这是最后一组答案了。Data里面全是回答的数据信息,不需要知道每个字段代表什么含义,只需要取出我们需要的字段即可。
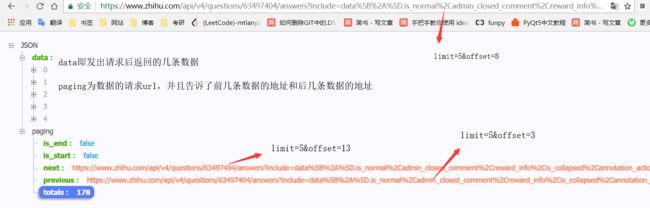
对于一个答案,author的id可能是不存在的,因为知乎在回答问题的时候,可以是匿名回答的,就不需要知道id。所以必须弄清楚哪些是必须字段,哪些不是。
问题解决:“Unknown column 'comments_nums' in field list”
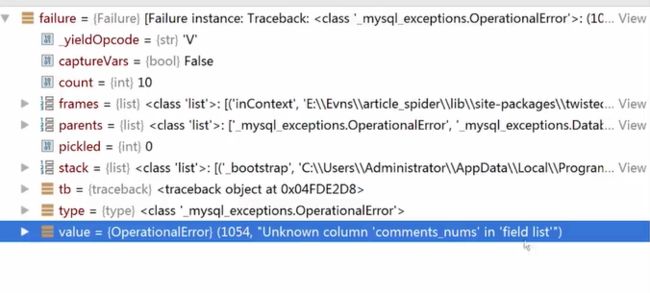
这个错误的意思是说,comments_nums这个列不存在
问题解决:“Duplicate entry ''110....' for key 1”
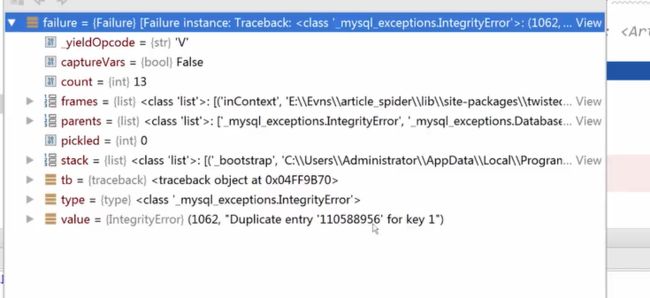
这个错误表示主键冲突,插入了重复的数据,有时候重复的数据自然可以舍去,但是有时候已经插入过的数据可能发生了更新。就需要重新插入新的数据了,简单的插入逻辑就不满足要求了。解决办法为在插入的时候检查是否重复,如果重复就进行更新。
提示:
如果爬取的过快的话,知乎会返回403错误,这个错误实际上是知乎的反爬虫机制,知乎会去检查user-agent,同一个user-agent在同一个ip地址下请求过于频繁的话,就会返回403的错误页面。在后面的反爬策略中会介绍随机更换user-agent的方法。
还有个问题:知乎登录出错的时候,会返回验证码,如何识别验证码,并且通过识别验证码发送登录请求,在如何防止爬虫被禁止的知识中介绍。
8.7 知乎验证码的输入和获取
8.7.1 request请求登录
在request模拟知乎登录的过程中,有时候会出现验证码的情况,一般验证的请求也是有一个地址的,通过F12可以查看请求的地址,对于老版的登录情况,这个地址是https://www.zhihu.com/captcha.gif?r=123456789&type=login,其中123456789是一个随机的字符串,请求这个网页就能获取验证码信息,所以需要专门去请求一次来获取。
def get_captcha():
import time
t = str(int(time.time()*1000))
# captcha_url = "https://www.zhihu.com/api/v3/oauth/captcha?lang=en"
# 新的验证码请求地址,但是返回来的已经不是图片信息了,新的办法可以多次刷新登录页面,去检查元素中获取验证码元素的img的地址,从而获得验证码页面。
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
t = session.get(captcha_url,headers = header)
with open("captcha.jpg","wb") as f:
f.write(t.content)
f.close()
现在去请求验证码的地址并不能直接获取图片的数据,以二进制的方式写入文件中,保存即获得验证码图片。想了另一种方式,就是多刷新几次登录页面就会出来验证码图片,去前端html中解析出验证码的地址,从而获得验证码图片,没有尝试,只是有这种思路。不过根据现在知乎的登录更新来看,通过request模拟登录的方法总是不能完全弄清楚知乎登录需要传入哪些参数,所以这么登录方法总是不能适应知乎登录的快速更新。
这种方法,都是需要自己去分析出请求验证码的地址,结合session获取到验证码的内容,保存为图片,然后将图片展示出来,在控制台中手动识别验证码输入,获取到控制台输入的内容post给知乎就可以完成解决验证码登录问题了。
8.7.2. scrapy中请求登录验证码
首先在登录的时候验证码默认值为空,最主要的问题是如何保证验证码的请求和上面登录页面的请求是同一次session中,scrapy框架是一个异步框架,每一次的scrapy.Requests()访问都是异步,所以如果是在请求到登录页后,直接请求验证码得到的结果肯定是错的。
其解决办法是,再增加一个登录函数,在上一步使用yield的方式就能在同一个response中,并且将其余账号密码信息都传递给yield的地址中,获得验证码进行识别,将结果填入到空的字段中,最后再次将所有内容post,就完成请求了。
def login(self,response):
response_text = response.text
match_obj = re.match('.*name="_xsrf" value="(.*?)"', response.text,re.DOTALL)
# 正则表达式的规则对于一段文本,默认只匹配第一行
xsrf = ''
if match_obj:
xsrf = match_obj.group(1)
if xsrf: # 如果获取不到这个xsrf码的话,就没必要登录了
post_data = {
"_xsrf": xsrf,
"phone_num": "17392480273",
"password": "48298847zyy",
"captcha": ""
}
import time
t = str(int(time.time() * 1000))
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
yield scrapy.Request(captcha_url,headers=self.headers,meta={"post_data":post_data},callback=self.login_after_capthcha)
def login_after_capthcha(self,response):
# 这个函数功能时将登录延迟一步,到获取验证码并且输入验证码之后,注意这里是异步的框架,所以需要通过延迟一步的方式保证和上一次的response是在同一次session中
with open("captcha.jpg", "wb") as f:
f.write(response.body)
f.close()
from PIL import Image
try:
im = Image.open("captcha.jpg")
im.show()
im.close()
except:
pass
captcha = input("输入验证码\n>")
post_url = "https://www.zhihu.com/api/v3/oauth/sign_in"
post_data = response.meta.get("post_data",{})
post_data["captcha"] = captcha
return [scrapy.FormRequest(
url= post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)]
8.8 知乎倒立文字验证码
github上有个者也的大神已经做过知乎倒立文字汉字验证码识别程序,https://github.com/muchrooms/zheye,将代码clone下来,使用git clone命令,git clone https://github.com/muchrooms/zheye.git,下载完成之后打开文件目录可以看到有一个requirements.txt文件,里面是关于这个识别程序需要用到的包,所以进入虚拟环境和当前源码目录下安装这些包。注意,如何批量安装文件中的包,使用命令pip install -r requirements.txt。如果在windows下包装包出错,都可以https://www.lfd.uci.edu/~gohlke/pythonlibs/网址下载对应的包,这里面集合了大多数windows下容易安装出错的包,然后手动安装。
github使用步骤:
- 下载源代码:
git clone https://github.com/muchrooms/zheye.git - 安装相应的包:
pip install -r requirements.txt - 测试代码是否通过:
from zheye import zheye
z = zheye()
positions = z.Recognize('path/to/captcha.gif')
运行zheye识别倒立验证码
注意在安装过程中的问题:
(1)Could not find a version that satisfies the requirement tensorflow==1.0.0
解决方法:根据报错信息提示,存在哪些版本,就将requirements.txt中包的版本更改一下,如果还是出错则手动重新安装新的版本
(2)在批量安装包到最后一个时,cmd卡死,解决办法是,不要再重复安装,应该运行测试代码的时候根据报错信息安装指定的内容。
(3)TypeError: softmax() got an unexpected keyword argument 'axis'
解决方法:这应该是由于包的更新之后,函数发生了变化,去源文件中将', axis=axis' 删除掉即可。
如果某一包已经安装过了,就会卸载掉之前下载的版本。如果要安装的版本找不到,可以先安装最新的版本。
关于知乎的文字验证码位置坐标返回来的数据是一个字典,并且坐标是先y后x,而在输入验证码后post时的数据时先x后y,并且按从左到右倒立字的顺序,所以需要用一个新的数组将里面的内容进行重组,得到最后post过去的字符串内容。

8.9 总结
以上关于知乎部分,其中登录方式使用了三种,分别是selenium模拟登录,scrapy登录以及requests登录,其中selenium最简单,后面两者都要考虑关于session是在一次会话中再次请求的验证码,或者就会出现验证码问题无法成功登录。然后关于验证码的请求也讲了两种,一种是在requests登录中,直接使用session请求即可,另一种是在scrapy中,因为这是一个异步框架,所以必须使用yield在同一个session中才能对验证码进行处理。其中还补充了关于知乎的倒立文字验证识别,使用的github上大佬的代码,整合进知乎的登录中即可。注意,最重要的要从F12中知道数据格式,有哪些数据,以及到底请求的url地址是什么。