接下来要着重介绍pandas的输入输出对象,输入输出通常可以划分为几个大类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据,利用Web API操作网络资源。
读写文本格式的数据
read_csv和read_table可能会用到的多:
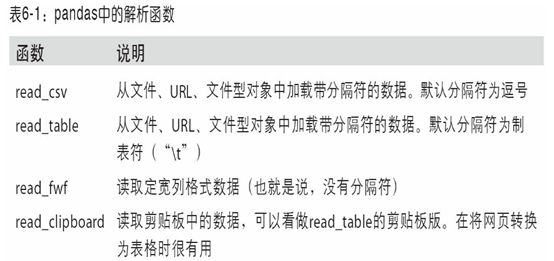
我将大致介绍一下这些函数在将文本数据转换为DataFrame时所用到的一些技术。这些函数的选项可以划分为以下几个大类:
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)
类型推断(type inference)是这些函数中最重要的功能之一,也就是说,你不需要指定列的类型到底是数值、整数、布尔值,还是字符串。日期和其他自定义类型的处理需要多花点工夫才行。首先我们来看一个以逗号分隔的(CSV)文本文件
In [1]: from pandas import Series,DataFrame
In [2]: import pandas as pd
In [3]: import numpy as np
In [4]: !type ex1.csv
a,b,c,d,message
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
由于该文件以逗号分隔,所以我们可以使用read_csv将其读入一个DataFrame
这里的type用的是Windows系统将文本的原始内容打印到屏幕上,如果您使用UNIX shell命令,cat也可以达到同样的效果。
In [7]: df=pd.read_csv('ex1.csv')
In [8]: df
Out[8]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
也可以用read_table,但是需要指定分隔符
In [9]: pd.read_table('ex1.csv',sep=',')
Out[9]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
并不是所有文件都有标题行。看看下面这个文件
In [10]: !type ex2.csv
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
读入该文件的办法有两个。你可以让pandas为其分配默认的列名,也可以自己定义列名
In [11]: pd.read_csv('ex1.csv',header=None)
Out[11]:
0 1 2 3 4
0 a b c d message
1 1 2 3 4 hello
2 5 6 7 8 world
3 9 10 11 12 foo
In [12]: pd.read_csv('ex2.csv',header=None)
Out[12]:
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
In [13]: pd.read_csv('ex2.csv',names=['a','b','c','d','message'])
Out[13]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
假设你希望将message列做成DataFrame的索引。你可以明确表示要将该列放到索引4的位置上,也可以通过index_col参数指定"message"
In [14]: names=['a','b','c','d','message']
In [15]: pd.read_csv('ex2.csv',names=names,index_col='message')
Out[15]:
a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可
In [16]: !type csv_mindex.csv
key1,key2,value1,value2
one,a,1,2
one,b,3,4
one,c,5,6
one,d,7,8
one,e,9,10
two,a,11,12
two,b,13,14
two,c,15,16
two,d,17,18
In [17]: parsed=pd.read_csv('csv_mindex.csv',index_col=['key1','key2'])
In [18]: parsed
Out[18]:
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
e 9 10
two a 11 12
b 13 14
c 15 16
d 17 18
有些表格可能不是用固定的分隔符去分隔字段的(比如空白符或其他模式)。
In [22]: list(open('ex3.txt'))
Out[22]:
[' A B C\n',
'aaa -0.264438 -1.026059 -0.619500\n',
'bbb 0.927272 0.302904 -0.032399\n',
'ccc -0.264273 -0.386314 -0.217601\n',
'ddd -0.871858 -0.348382 1.100491\n']
可以手动对数据进行规整,这里的字段是被数量不同的空白字符间隔开的。在这种情况下,可以用正则表达式表达\s+表示
In [23]: result=pd.read_table('ex3.txt',sep='\s+')
In [24]: result
Out[24]:
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
由于列名比数据行的数量少,所以read_table推断第一列应该是DataFrame的索引。
这些解析器函数还有许多参数可以帮助你处理各种各样的异形文件格式(参见表6-2)。比如说,你可以用skiprows跳过文件的第一行、第三行和第四行
In [31]: !type ex4.csv
# hey!,,,,
a,b,c,d,message
# just wanted to make things more difficult for you ,,,,
"# who reads CSV files with computers,anyway?",,,,
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
In [32]: pd.read_csv('ex4.csv',skiprows=[0,2,3])
Out[32]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
缺失值处理是文件解析任务中的一个重要组成部分。缺失数据经常是要么没有(空字符串),要么用某个标记值表示。默认情况下,pandas会用一组经常出现的标记值进行识别,如NA、-1.#IND以及NULL等
In [33]: !type ex5.csv
something,a,b,c,d,message
one,1,2,3,4,NA
two,5,6,7,8,world
three,9,10,11,12,foo
In [34]: result=pd.read_csv('ex5.csv')
In [35]: result
Out[35]:
something a b c d message
0 one 1 2 3 4 NaN
1 two 5 6 7 8 world
2 three 9 10 11 12 foo
In [36]: pd.isnull(result)
Out[36]:
something a b c d message
0 False False False False False True
1 False False False False False False
2 False False False False False False
na_values可以接受一组用于表示缺失值的字符串
In [37]: result=pd.read_csv('ex5.csv',na_values=['NULL'])
In [38]: result
Out[38]:
something a b c d message
0 one 1 2 3 4 NaN
1 two 5 6 7 8 world
2 three 9 10 11 12 foo
可以用一个字典为各列指定不同的NA标记值
In [39]: sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
In [40]: pd.read_csv('ex5.csv', na_values=sentinels)
Out[40]:
something a b c d message
0 one 1 2 3 4 NaN
1 NaN 5 6 7 8 world
2 three 9 10 11 12 NaN


逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
In [4]: result=pd.read_csv('examples/ex6.csv')
In [5]: result
Out[5]:
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
5 1.817480 0.742273 0.419395 -2.251035 Q
... ... ... ... ... ..
9997 0.523331 0.787112 0.486066 1.093156 K
9998 -0.362559 0.598894 -1.843201 0.887292 G
9999 -0.096376 -1.012999 -0.657431 -0.573315 0
[10000 rows x 5 columns]
如果只想读取几行(避免读取整个文件),通过nrows进行指定即可
In [6]: pd.read_csv('examples/ex6.csv',nrows=6)
Out[6]:
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
5 1.817480 0.742273 0.419395 -2.251035 Q
要逐块读取文件,需要设置chunksize(行数)
In [7]: chunker=pd.read_csv('examples/ex6.csv',chunksize=1000)
In [8]: chunker
Out[8]:
将数据写出到文本格式
数据也可以被输出为分隔符格式的文本。我们再来看看之前读过的一个CSV文件
In [13]: data=pd.read_csv('examples/ex5.csv')
In [14]: data
Out[14]:
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
利用DataFrame的to_csv方法,我们可以将数据写到一个以逗号分隔的文件中
In [15]: data.to_csv('out.csv')
In [16]: !type out.csv
,something,a,b,c,d,message
0,one,1,2,3.0,4,
1,two,5,6,,8,world
2,three,9,10,11.0,12,foo
还可以使用其他分隔符(由于这里直接写出到sys.stdout,所以仅仅是打印出文本结果而已)与书上不同,报错了。
In [17]: data.to_csv(sys.stdout,sep='|')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
----> 1 data.to_csv(sys.stdout,sep='|')
NameError: name 'sys' is not defined
Series也有一个to_csv方法
In [18]: dates = pd.date_range('1/1/2017', periods=8)
In [19]: ts = Series(np.arange(8), index=dates)
In [20]: ts.to_csv('tseries.csv')
In [21]: !tseries.csv
In [22]: !type tseries.csv
2017-01-01,0
2017-01-02,1
2017-01-03,2
2017-01-04,3
2017-01-05,4
2017-01-06,5
2017-01-07,6
2017-01-08,7
虽然只需一点整理工作(无header行,第一列作索引)就能用read_csv将CSV文件读取为Series,但还有一个更为方便的from_csv方法
In [23]: Series.from_csv('tseries.csv', parse_dates=True)
Out[23]:
2017-01-01 0
2017-01-02 1
2017-01-03 2
2017-01-04 3
2017-01-05 4
2017-01-06 5
2017-01-07 6
2017-01-08 7
dtype: int64
手工处理分隔符格式
大部分存储在磁盘上的表格型数据都能用pandas.read_table进行加载。然而,有时还是需要做一些手工处理。由于接收到含有畸形行的文件而使read_table出毛病的情况并不少见。为了说明这些基本工具,看看下面这个简单的CSV文件
In [26]: !type ex7.csv
"a","b","c"
"1","2","3"
"1","2","3"
对于任何单字符分隔符文件,可以直接使用Python内置的csv模块。将任意已打开的文件或文件型的对象传给csv.reader
In [27]: import csv
In [28]: f = open('ex7.csv')
In [29]: reader=csv.reader(f)
对这个reader进行迭代将会为每行产生一个元组(并移除了所有的引号)
In [30]: for line in reader:
...: print(line)
...:
['a', 'b', 'c']
['1', '2', '3']
['1', '2', '3']
为了使数据格式合乎要求,你需要对其做一些整理工作:
In [31]: lines = list(csv.reader(open('ex7.csv')))
In [32]: header, values = lines[0], lines[1:]
In [33]: data_dict = {h: v for h, v in zip(header, zip(*values))}
In [34]: data_dict
Out[34]: {'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}

json数据和web数据库方面的练习暂时放着,比较难理解,等条件充足再进行后面练习。