一.爬取中国诗词网
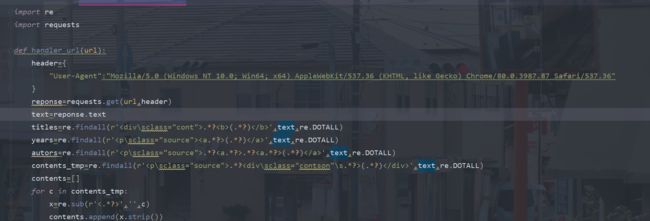
import re
import requests
def handler_url(url):
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
reponse=requests.get(url,header)
text=reponse.text
titles=re.findall(r'.*?(.*?)',text,re.DOTALL)
years=re.findall(r'(.*?)',text,re.DOTALL)
autors=re.findall(r'.*?.*?(.*?)',text,re.DOTALL)
contents_tmp=re.findall(r'.*?(.*?)
',text,re.DOTALL)
contents=[]
for c in contents_tmp:
x=re.sub(r'<.*?>','',c)
contents.append(x.strip())
poems=[]
for value in zip(titles,years,autors,contents):
title,year,autor,content=value
poem={
"title":title,
"year":year,
"autor":autor,
"content":content
}
poems.append(poem)
for a in poems:
print(a)
def main():
base_url="https://www.gushiwen.org/default_{}.aspx"
for i in range(1,7):
url=base_url.format(i)
handler_url(url)
if __name__ == '__main__':
main()

二.爬取豆瓣热门图书
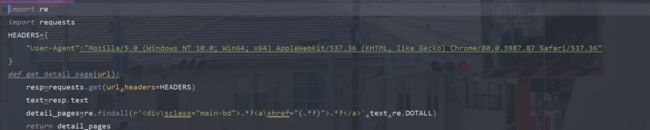
import re
import requests
HEADERS={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
def get_detail_page(url):
resp=requests.get(url,headers=HEADERS)
text=resp.text
detail_pages=re.findall(r'.*?.*?',text,re.DOTALL)
return detail_pages
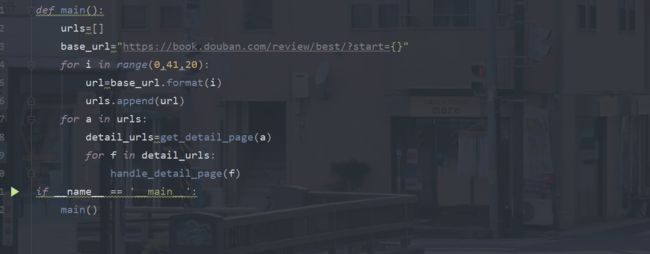
def handle_detail_page(url):
book={}
resp=requests.get(url,headers=HEADERS)
text=resp.text
titles=re.findall(r'.*?(.*?)',text,re.DOTALL)
articles_tmp=re.findall(r'.*?.*
',text,re.DOTALL)
articles=[]
for a in articles_tmp:
x=re.sub(r'<.*?>','',a)
y=x.replace('\r','').replace('\n','')
a=re.sub(r'','',y)
b=a.replace(' ','')
articles.append(b)
# print(articles)
# print(titles)
book={
'title':titles,
'article':articles
}
print(book)
def main():
urls=[]
base_url="https://book.douban.com/review/best/?start={}"
for i in range(0,41,20):
url=base_url.format(i)
urls.append(url)
for a in urls:
detail_urls=get_detail_page(a)
for f in detail_urls:
handle_detail_page(f)
if __name__ == '__main__':
main()

三.总结
这两个小的爬虫项目,网站都没有进行反爬处理,所以说对于我们爬出页面信息还是比较简单的,关键在于数据怎么解析,最近一直再看正则表达式,所以找了两个小的项目练一练,这两个小项目也可以使用beatifulsoup或者xml库进行进行,找时间再试试别的方法解析数据把~