Real-time analytics is currently an important issue. Many different domains need to process data in real time. So far there have been multiple technologies trying to provide this capability. Technologies such as Storm and Spark have been on the market for a long time now. Applications derived from the Internet of Things (IoT) need data to be stored,processed, and analyzed in real or near real time. In order to cater for such needs, Flink provides a streaming data processing API called DataStream API.
(当前Real-time分析是一个非常重要的问题。很多领域都需要实时地处理数据。截止目前,有很多技术来提供这种数据的实时处理能力。象Storm Spark这种技术很早就已经出现了。源于互联网的应用程序需要实时或准实时地存储,处理及分析它们的数据。为满足这些需求,Flink提供了流数据处理API 叫DataStream API)
In this chapter, we are going to look at the details relating to DataStream API, covering the following topics:
(在这一节,我们着眼于DataStream API相关的一些细节,覆盖以下几个topic)
- Execution environment
- Data sources
- Transformations
- Data sinks
- Connectors
- Use case -sensor data analytics
Any Flink program works on a certain defined anatomy as follows:
Flink应用程序基于确定的结构工作。如下图所示:

We will be looking at each step and how we can use DataStream API with this anatomy.
我们会研究这里的每一步,以及我们怎么使用DataStream API。
Execution environment
In order to start writing a Flink program, we first need to get an existing execution environment or create one.
Flink应用程序,首先,我们需要获得一个execution environment,或者创建一个execution environment。
Depending upon what you are trying to do, Flink supports:
- Getting an already existing Flink environment
- Creating a local environment.
- Creating a remote environment。
根据你的想法(获取还是新建?)Flink 支持: - 获取一个存在的
Flink environment - 创建一个本地的
Flink environment - 创建一个远程的
Flink environment
Typically, you only need to use getExecutionEnvironment (). This will do the right thing based on your context. If you are executing on a local environment in an IDE then it will start a local execution environment . Otherwise, if you are executing the JAR then the Flink cluster manager will execute the in a distributed manner.
(典型的,你只需要用getExecutionEnvironment ()方法,Flink 会基于你的上下文获取正确的Flink environment。如果 你在本地IDE执行它将启动一个local execution environment。否则,如果你执行JAR,那么Flink cluster Manager会以分布式方式运行。)
If you want to create a local or remote environment on your own then you can also choose do so by using methods such as createLocalEnvironment () and createRemoteEnvironment (string host, int port, string, and . iar files).
如果你想在自己的环境中创建一个local environment 或remove environment,你可以选择这两个方法:
- createLocalEnvironment ()
- createRemoteEnvironment (string host, int port, string, and . jar files)
Data sources
Sources are places where the Flink program expects to get its data from. This is a second step in the Flink program's anatomy. Flink supports a number of pre-implemented data source functions. It also supports writing custom data source functions so anything that is not supported can be programmed easily. First let's try to understand the built-in source functions.
Sources是Flink应用程序预期获取数据的地方。这是Flink 程序结构的第二步。Flink会支持一些预先实现的Sources方法。而对于不支持的Sources,它提供自定义方法,所以很容易通过编程实现。首先,我们先了解一下build-in(内建)的Source 方法。
Socket-based
DataStream API supports reading data from a socket. You just need to specify the host and port to read the data from and it will do the work:
DataStream API支持从socket读数据。你只需要指定host和post即可,它
sockeTextStream(hostName,port);//译者注:default delimiter is "\n"
You can also choose to specify the delimiter:
sockeTextStream(hoatName,port,delimiter)
You can also specify the maximum number of times the API should try to fetch the data sockeTextStream (hostName, port, delimiter, maxRetry)
File-based
You can also choose to stream data from a file source using file-based source functions in Flink. You can use readTextFile (string path) to stream data from a file specified in the path. By default it will read TextInputFormat and will read strings line by line
你可以用file-bases source方法从文件中读取流。具体用readTextFile(String path)方法从指定的文件中获取stream。该方法默认用TextInputFormat一行一行地读取内容。
If the file format is other than text, you can specify the same using these functions:
如果文件的format不是text,而是其他的format,你可以指定FileInputFormat参数
方法如下
readFile(FileInputFormat inputFormat,string path)
Flink also supports reading file streams as they are produced using the readFileStream ().function:
Filnk 的readFileStream ()支持在文件流产生时读取
//译者注 @deprecated Use {@link #readFile(FileInputFormat, String, FileProcessingMode, long)} instead'
readFileStream (string filepath,
long inkervalMillis,FileMonitorincEunction. watchTvpe watchType).
译者摘选部分源码
/**
* The mode in which the {@link ContinuousFileMonitoringFunction} operates.
* This can be either {@link #PROCESS_ONCE} or {@link #PROCESS_CONTINUOUSLY}.
*/
@PublicEvolving
public enum FileProcessingMode {
/** Processes the current contents of the path and exits. */
PROCESS_ONCE,
/** Periodically scans the path for new data. */
PROCESS_CONTINUOUSLY
}
/**
* The watch type of the {@code FileMonitoringFunction}.
*/
public enum WatchType {
ONLY_NEW_FILES, // Only new files will be processed.
REPROCESS_WITH_APPENDED, // When some files are appended, all contents
// of the files will be processed.
PROCESS_ONLY_APPENDED // When some files are appended, only appended
// contents will be processed.
}
You just need to specify the file path, the polling interval in which the file path should be polled, and the watch type.Watch types consist of three types:
你只需要指定文件路径,对该文件的轮循间隔以及watch type 。
watch type包括以下三种(译者注:该方法已过期,见上文代码注释)
- FileMonitoringFunction. WatchType.ONLY_NEW_FILES is used when the system should process only new files (新文件全读)
- FileMonitoringFunction. WatchType. PROCESS_ONLY_APPENDED is used when the system should process only appended contents of files (只读append 部分)
- FileMonitoringFunction. WatchType. REPROCESS_WIIH _APPENDED is used when the system should re-process not only the appended contents of files but also the previous content in the file(有apend 全读)
If the file is not a text file, then we do have an option to use following function, which lets us define the file input format
如果不是文本文件,我们使用下面这个方法,这个方法让我们定义一个FileFormat参数
readFile (fileInputFormat, path, watchType, interval, pathFilter,typeInfo)
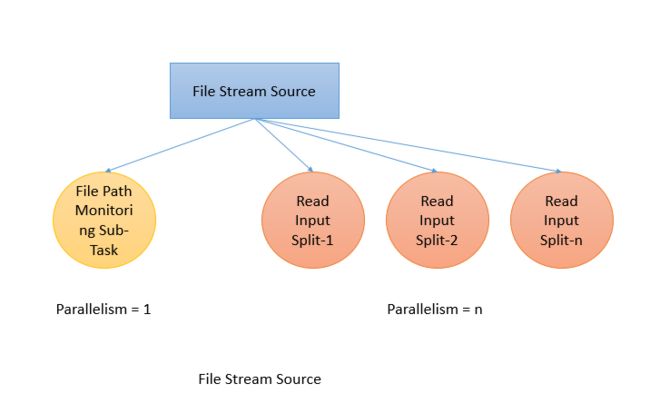
Internally, it divides the reading file task into two sub-tasks. One sub task only monitors the file path based on the WatchType given. The second sub-task does the actual file reading in parallel. The sub-task which monitors the file path is a non-parallel sub-task. Its job is to keep scanning the file path based on the polling interval and report files to be processed, split the files, and assign the splits to the respective downstream threads:
Flink 内部,它会将这个读文件的任务分成两个子任务。一个子任务只监控基于给定WatchType的file path。第二个是实际读文件的任务,这个任务会并行运行。而这个监控文件路径的任务不是并行的。它会持续根据轮循周期扫描file path。然后报告这些文件(files),分割文件,并将这些分片指给对应的下游线程。
译者注:这里path是路径还是文件?每个split 是一个大文件的切片还是对一个目录下的小文件?
Transformations
Data transformations transform the data stream from one form into another. The input could be one or more data streams and the output could also be zero, or one or more data streams. Now let's try to understand each transformation one by one.
Data transformation会将数stream从一种形式转换成另一种形式。输入的数据流可以是一个,也可以是多个;而输出也可能没有,可能是一个或多个。好了,下面我们一个一个地来理解transformation
Map
This is one of the simplest transformations, where the input is one data stream and the output is also one data stream
Map 是最简单的transformation 之一,这种transformation有输入和输出都只有一个。
In Java:
inputStream.map (new MapFunction() (){
@Override
public Integer map (Intege value) throws Exception{
return 5 *value;
}
}};
In Scala:
inputStream.map {x =>x5}
FlatMap
FlatMap takes one record and outputs zero, one, or more than one record
FlatMap 的输入只有1条记录,而输出可以是0,1或更多的记录。
In Java:
inputStream. flatMap (new FlatMaprunction() {
@override
public void flatMap (string value, collector out) throws Exception {
for (string word: value.split("")){
out.collect (word);
}
}
});
In Scala
inputStream. flatMap {atr => atr.aplit(" ") }
Filter
Filter functions evaluate the conditions and then, if they result as true, only emit the record.Filter functions can output zero records
Filter 方法会计算条件的值,然后判断结果值如果为true,则发出一条记录。该方法也可以输出0条记录。
In Java:
inputStream. filter (new FilterFunction(){
@override public boolean filter (intecer value) throws Exception {
return value!= 1;
}
});
In Scala:
inputStream.filter {-!=1}
KeyBy
KeyBy logically partitions the stream-based on the key. Internally it uses hash functions to partition the stream. It returns KeyedDataStream.
KeyBy方法会在逻辑上通过key对stream进行分区。内部会使用hash方法对流进行分区,它返回KeyedDataStream
In Java:
inputStream. KeyBy ("someKey");
In Scala:
inputStream.keyBy ("someKey")
Reduce
Reduce rolls out the KeyedDataStream by reducing the last reduced value with the current value. The following code does the sum reduce of a KeyedDataStream
Reduce会通过将最后归纳的结果值和当前的值进行归纳而推出KeyedDataStream。
In Java:
keyedInputStream. reduce (new Reducerunction() {
@override
public Integer reduce (Integer valuel, Integer value2)throws Exception {
return value1 -value2;}
});
In Scala:
keyedInputStream. reduce{_+_}
Fold
Fold rolls out the KeyedDataStream by combining the last folder stream with the current record. It emits a data stream back
Fold通过将最后folder流和当前记录组合而推出KeyDataStream,它返回数据流。
In Java:
keyedInputStream keyedstream. fold("start", new Foldrunction(){
@override public string fold(string current, Integer value) {
return current ."=" -value;
}
});
In Scala:
keyedInputStream. fold("start") ((str, i) =>str+"="+i}).
The preceding given function when applied on a stream of (1,2,3,4.5) would emit a stream like this: Start=1-2-3-4-5
前面给出的函数在(1,2,3,4.5)流上应用时将得出这样的流:Start=1-2-3-4-5
Aggregations
DataStream API supports various aggregations such as min, max, sum, and so on. These functions can be applied on KeyedDataStream in order to get rolling aggregations
DataStream API 支持多种象min,max,sum等操作。这些函数应用在KeyedDataStream上,以便进行滚动聚合。
In Java
keyedInputStream. sum (0)
keyedInputStream. sum ("key")
kevedInputStream.min (0)
keyedInputStream.min ("key")
keyedInputStream.max (0)
kevedInputStream.max ("key")
keyedInputStream.minBy (0)
keyedInputStream.minBy ("key")
keyedInputStream.maxBy (0)
keyedInputStream, maxBy ("key")
In Scala:
keyedInputStream. sum (0).
keyedInputStream. sum ("key")
keyedInputStream.min(0)
keyedInputStream. min ("key")
keyedInputStream.max (0)
keyedInputStream. max ("key")
keyedInputStream.minBy (0)
keyedInputStream. minBy ("key")
keyedInputStream.maxBy (0)
keyedInputStream. maxBy ("key")
The difference between max and maxBy is that max returns the maximum value in a stream but maxBy returns a key that has a maximum value. The same applies to min and minBy.
min和maxBy的区别是:min返回流中的最大值,而maxBy会返回具有最大值的key,对于min和minBy也是一样的。