原文链接:https://tbgraph.wordpress.com/2017/11/17/neo4j-marvel-social-graph-algorithms-community-detection/
译者言:本文较长,但内容清晰,后面有动手的东西,有兴趣可以交流。
在本系列第一篇在Neo4j中构建漫威世界的社交网络中我们从英雄到漫画的二分图推导出英雄到英雄的一分图。接着在第二篇在Neo4j中对漫威社交网络进行初步分析中得到一些基本的网络信息以帮助我们了解正在处理的网络情况。
在本篇中我将会在漫威英雄的网络上使用Louvain算法和标签传播算法(LPA),发现一些有趣的社群。
本文中的可视化是使用Gephi来进行呈现,关于Gephi的更多信息可以看我之前的文章《Neo4j to Gephi》(https://tbgraph.wordpress.com/2017/04/01/neo4j-to-gephi/)。关于社群可视化还可以使用neovis.js(https://github.com/johnymontana/neovis.js)。
图映射
Neo4j图算法一般是在图的子集上进行,而这个子集通常是一个虚拟图,Neo4j图算法加载这种图有两种办法。第一种简单的办法是通过指定结点的标签和关系的类型将其加载到图算法中。
但是,如果我们要运行的逻辑是在一个特定的子图上,而仅使用结点标签和关系类型无法描述出这个子图,同时也不想去修改实体图,这时要怎么办呢?
不用担心,我们还可以使用Cypher语句来指定要加载的子图。使用查询结点的Cypher语句代替结点标签参数,使用查询关系的Cypher语句来代替关系类型参数。
但是注意,在参数中一定要指明 graph:'cypher'。
如下示例:
CALL algo.unionFind(
//第一个Cypher语句指定了要加载的结点。
'MATCH (p:User)
WHERE p.property = 'import'
RETURN id(p) as id',
//第二个Cpyher语句指定要加载的关系
'MATCH (p1:User)-[f:FRIEND]->(p2:User)
RETURN id(p1) as source, id(p2) as target,f.weight as weight',
{graph:'cypher',write:true})
通过Cypher语句映射和加载子图,可以非常好的描述要运行算法的子图。不仅如此,我们还可以剔除一些关系,间接的映射一个虚拟图用于运行算法,而那些剔除的关系又并不会从实际图中删除。
Cpyher映射使用场景:
* 过滤结点和关系
* 加载间接关系
* 映射双向图
* 相似性阈值(后面详情介绍)
社群识别
在对各种网络的研究过程中,如计算机网络、社交网络以及生物网络,我们发现了许多不同的特征,包括小世界特性,重尾分布以及聚类等等。另外,网络都有一个共同的特征即社群结构,也就是连通和分组。而现实网络世界的连通并不是随机或同质的,而是存在着某种自然的联系。
社群识别算法在一个全连通的图上运行,效果并不会很好。因为大多数据结点都是紧密连接的,他们是属于一个社群的。在这些的图上运行算法,最终结果就是:得到一个覆盖图大部分区域的大社群和一些边边角角小社群。
这时我们可以使用相似性阈值来进行调控,将大于某个值的关系保留,而小于此值的关系将会剔除。而这个虚拟图就可以通过Cypher语句轻松的映射出来了。
在本文中,我会将漫威社交网络中KNOWS的weight作为阈值,将其设置到100,大于100的关系将会保留,小于100的关于将会剔除,这样,得到的社群将会非常紧密。
连通分量
连通分量或并查集算法都是找到相互连接的结点集,或者称之为岛,而在这个集合中的所有点都是可以相互连通的。
在图论中,无向图的连通分量(或者仅分量)是一个子图,其中此子图任何两个顶点通过路径相互连接。
当我遇到一个新的网络时,我第一时间想知道是:这个网络有多少个连通分量,以及他们每个都包含多少结点。在漫威英雄的网络中,当前我们已经把KNOWS的weight阈值设置到100了,而前一篇文章的阈值是10,因此,本文得到的连接肯定要比前一篇文章()中的连接要少。
在下面的示例中,我们直接使用结点标签和关系类型,所有标签为Hero的结点和所有类型为KNOWS的关系都将被加载到算法中。由于我们将阈值设置到100,所以,当前算法只考虑weight大于100的关系。
CALL algo.unionFind.stream('Hero', 'KNOWS',
{weightProperty:'weight', defaultValue:0.0, threshold:100.0,concurrency:1})
YIELD nodeId,setId
RETURN setId as component,count(*) as componentSize
ORDER BY componentSize DESC LIMIT 10;
译者言:原文查询语句可能是基于老版本的alog库,无法运营,当前查询语句已经修复
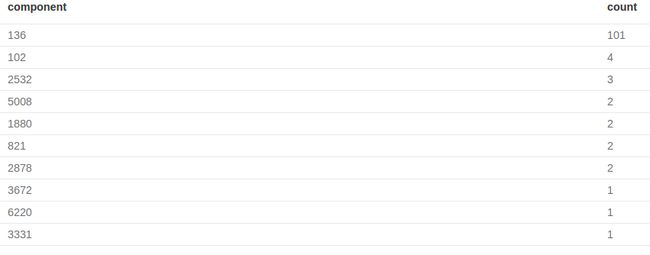
正如我所料,漫威英雄网络是一个稀疏图,有1个大社群和6小社群组成,大社群有101个英雄,而小社群基本也就2~4个英雄。这表示,在6439个英雄中,有116个英雄至少一个KNOWS关系的weight值是大于100的。
如果想在浏览器中仔细浏览那个包含101英雄的大社群,会很容易发现隐藏在这里面的一些直观的东西以及社群之间的桥梁结点。接下来我们将尝试使用Louvain算法和标签传播算法来看看这个116个英雄的子图的社群结构。
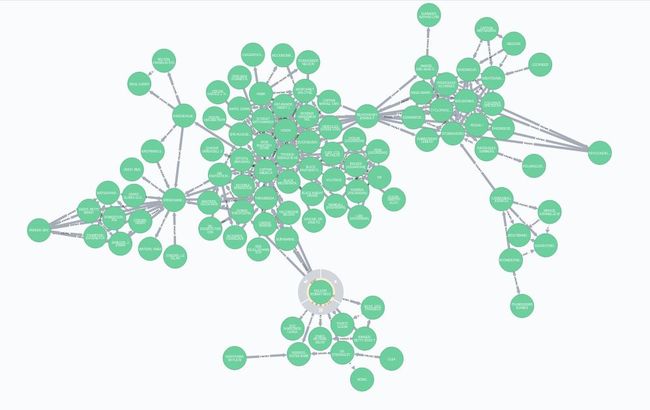
Louvain
社群就是网络中结点集合,它们彼此之间的连接比其他节点更紧密。Modularity是一种度量刻度,被用于衡量社群发现算法结果的质量,它能够刻画社区的紧密程度。在一个随机的网络中,将一个结点归类到某一个社群,Modularity值就是会生变化,进而给出这种分配后社区的质量。Modularity即量化了此结点与社群中其他结点的连接紧密程度。社群识别的Louvain方法,是一种基于启发式Modularity最大化的网络社群检测算法。
如前所述,我们将通过Cypher查询来仅映射weight大于110的关系到算法中。
CALL algo.louvain.stream(
// load nodes
'MATCH (u:Hero) RETURN id(u) as id',
// load relationships
'MATCH (u1:Hero)-[rel:KNOWS]-(u2:Hero)
// similarity threshold
WHERE rel.weight > 100
RETURN id(u1) as source,id(u2) as target',
{graph:"cypher"})
YIELD nodeId,community
MATCH (n:Hero) WHERE id(n)=nodeId
RETURN community,
count(*) as communitySize,
collect(n.name) as members
order by communitySize desc limit 5
我使用Gephi进行社群结果可视化,因为Gephi的表现力比表格更好,更有洞察力。
结点颜色:代表Louvain社群 结点大小:代表PageRank值 名字大小:代表中介中心性
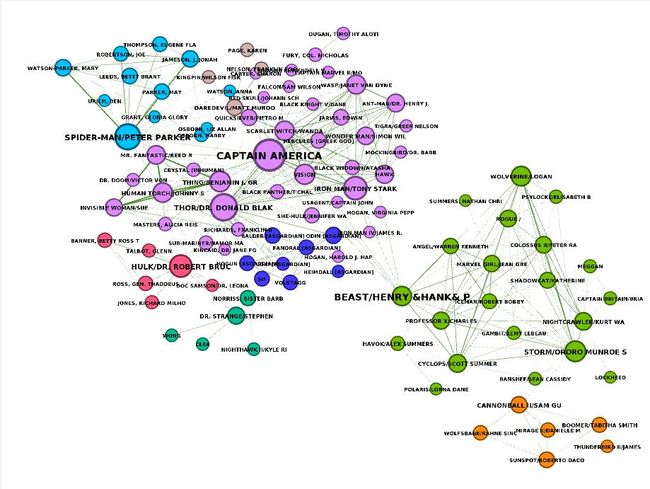
我并不是漫威漫画的专家,所以我只能根据数据来做一个简单的解释。我们总共划分出8个社群。最大的社群是紫色的社群,它由以美国队长为首的神盾局和复仇者联盟组成。在左边我们能看到神奇先生和神奇四侠也在紫色社群里。亮兰色是蜘蛛侠团队,蜘蛛侠帕克是他们与外界联系的唯一桥梁,其他人都是内部交流,与外界并无联系。深兰色是阿斯加德人,他们也是比较封闭,他们仅仅和雷神托尔有联系。哦?难以置信,绿巨人也是自己的社群(粉红色),而绿巨人是这个社群唯一与外界有联系的英雄。我们还看到野兽亨利是紫色社群与绿色社群的桥梁,位置特殊,而绿色是X-Men社群。
译者言:野兽亨利,在X-Men中就是那个全身兰色的家伙,但真没有在复仇者联盟系列电影中看到过他。
标签传播算法(LPA)
标签传播算法是由Raghavan等人于2007年首次提出,(译者言:百度百科显示此算法于2002年由Zhu等人提出)此算法是由每个结点使用其唯一标识作为标签,然后根据大多数邻居结点的标签为基础进行标签传播,每个结点再从他的邻居结点身上取出现次数最多的标签加到自己身上。LPA算法的具体步骤是这样:结点X有一些邻居结点,且每个邻居结点都有一个标签,标明他们所属的社群。然后网络中的每个结点都选择加入其大多数邻居所属的那个社群,同时再随机的断开一些连接。在开始时,每个节点都用唯一标签进行初始化,然后这些标签开始在网络中进行传播,传播的每一步,每个结点都会根据邻居标签的情况更新自己的标签,随着标签的传播,最终连接紧密的结点集合将会达成一个共识,而他们身上的标签也将不再发生变化。
与Louvaint算法类似,我们也采用Cypher语句进行图映射,在映射时仅加载weight值大于KNOWS关系。同时会将对结点进行回写,导出结果到Gephi中进行可视化展示。
CALL algo.labelPropagation(
// supports node-weights and defining
// initial communities using parameter value
'MATCH (u:Hero) RETURN id(u) as id, 1 as weight,id(u) as value',
// load relationships
'MATCH (u1:Hero)-[rel:KNOWS]-(u2:Hero)
// Similarity threshold
WHERE rel.weight > 100
RETURN id(u1) as source,id(u2) as target, rel.weight as weight',
'OUT',{graph:"cypher",partitionProperty:"lpa" })
YIELD computeMillis
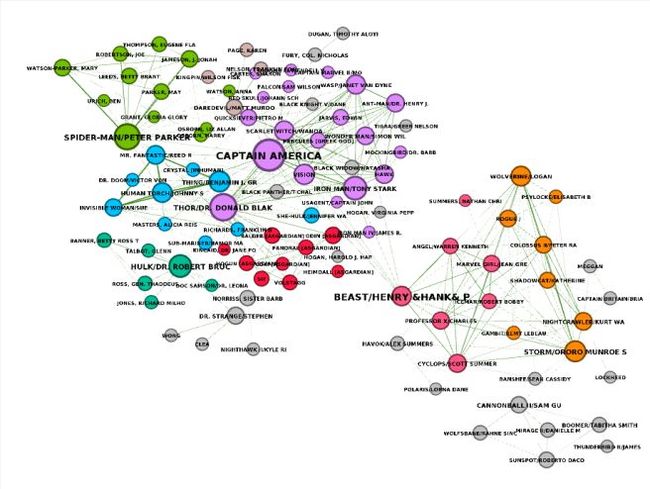
最终我们得到21个社群,包括单点社群。复仇者联盟(紫色)和神奇四侠(亮兰色)被分为两个社群了。蜘蛛侠(绿色),绿巨人(青绿色)和阿斯加德人(红色)三个社群的结果与Louvain算法一致。我们还发现X-Man被划分成两个社群,加农炮小组比Louvain的结果要稍微大点,同时也显的不那么孤立。
结点颜色:代表LPA社群 结点大小:代表PageRank值 名字大小:代表中介中心性
译者言:非常遗憾,我一直没有使用LPA算法重现出那21个社群,而得到的都是当结点社群,不知道作者是如何得到的,我已与作者进行了联系,如果有结果我会及时更新。另外,如果有朋友使用LPA推算出了任何结果,希望也给大家分享一下。当前文章的数据可以通过本系统文章的第一篇在Neo4j中构建漫威世界的社交网络获取。 我使用的查询语句如下:
CALL algo.labelPropagation.stream(
'MATCH (u:Hero) RETURN id(u) as id, 1 as weight,id(u) as value',
'MATCH (u1:Hero)-[rel:KNOWS]-(u2:Hero) WHERE rel.weight > 100 RETURN id(u1) as source,id(u2) as target, rel.weight as weight',
{graph:"cypher",iterations:10, partitionProperty : 'lpa'})
YIELD nodeId, label
with algo.getNodeById(nodeId) as node, label
return node.name , label
结论
你发现没有?Neo4j图算法库真的很神奇,用起来也简单。通过与Cypher查询语句结合进行虚拟图映射,可以简单有效的对图进行分析和理解。
本来,我打算在本文中介绍中心性算法的使用,但那样本文将会非常长,不便于阅读,所以, 我后续将会再写文章来介绍使用Cypher映射进行中心性算法的示例。敬请期待吧。
译者言:本文两个算法的介绍很清晰,作者也考虑到读者的心理负担,幸好没介绍中心性方面的算法,否则此文真的很长。