CockroachDB事务剖析
1简介
CockroachDB是一个支持SQL及完整事务ACID的分布式数据库。它支持两种隔离级别,分别是Serializable和Snapshot。CochroachDB实现了一个无锁的乐观事务模型,事务冲突通过事务重启或者回滚尽快返回客户端,然后由客户端决策下一步如何处理。
2 HLC
全局时钟是分布式事务的基石,cockroachDB使用HLC算法提供时钟。HLC由WallTime和LogicTime两部分组成。WallTime为节点n当前已知的最大的物理时间,通过先判断WallTime,再判断LogicTime确定两个事件的先后顺序。
在给本地节点产生的事件分配HLC时间时,WallTime部分取当前WallTime和当前物理时间最大值。如果物理时间小于或等于WallTime,LogicTime在原有基础上加一;如果物理时间大于WallTime,LogicTime归零。
节点之间的消息交换都会附带上消息产生时获取的HLC时间,当任一节点收到其他节点发送过来的消息时,取当前节点的WallTime、对端HLC时间的WallTime以及本地物理时间中的最大值。若三者相等,则取当前节点的LogicTime和对端LogicTime最大值加一;若对端WallTime最大,则取对端LogicTime加一;若本地WallTime最大,则取本地LogicTime加一。新的HLC时间更新到本地并作为本地下一个本地事件使用的HLC时间。
总而言之,WallTime表示事件发生时,当前节点所能感知到的最大物理时间,而LogicTime表示当WallTime相同时,两个事件的顺序。HLC算法可以保证如下特性:
1. 对于事件A,B,如果满足HLC.A < HLC.B,那么事件A一定发生在事件B之前,即A happen before B。
2. WallTime一定满足WallTime ≥ Node.pt。Node.pt即节点的本地物理时间。HLC只会一直增大,不会因为物理时间的波动而回退。
3. 如果发现WallTime > Node.pt,那么一定存在一个已经发生的事件X把当前节点的HLC往前推进了。
4. WallTime-Node.pt是有界的,它一定小于一个值ε。对于任意两个事件A和B,如果A happen before B,那么一定存在B.pt + ε ≥ A.pt。后面我们可以看到这个收敛的偏差ε的大小如何影响事务的冲突决策。
5. HLC可以满足全局快照的需求。这是因为当以一个HLC作为快照时间点时,这个时间会导致所有节点的HLC向前推进,因此这个时间之后发生的事件对于这个快照一定不可见,进而保证快照的读取安全有效。
3 MVCC
CockroachDB底层存储是KV,因此利用KEY + timestamp即可实现MVCC。在实际的操作中,为了快速读取到最新的数据,会把HLC取反encode到KEY的尾部,读取的时候以KEY作为前缀启动一个迭代器,这样最新的数据最先被读取到。
事务中未提交的数据比较特殊,并不会把事务时间戳encode到KEY的尾部,而是把事务相关的信息和数据一起Encode到Value中,称之为WRITE INTENT。读取的时候,未提交的数据肯定最先被Get到。
历史数据会被异步GC掉(GC的逻辑还未梳理)。
注意:对于一个需要耗时很久的读取,比如OLAP场景下,GC可能会影响到一致性快照,相关的保护代码我还没有找到(不代表没有)。
4 事务
4.1 事务隔离
CockroachDB支持两种事务隔离级别Snapshot和Serializable,简称SI和SSI,SI和SSI之间的核心区别在于事务提交时,SI允许事务的候选时间戳变大,而SSI不允许。
CockroachDB默认使用SSI隔离级别。在对性能要求较高,并且没有write skew的情况下可使用SI隔离级别。在冲突较少的情况下,SSI和SI性能相当,不需要加锁或额外写操作。在冲突激烈的情况下,SSI仍然不需要加锁,但是会有更多事务被终止。在任何长事务场景中,SI和SSI都能防止事务饿死。
4.2 事务流程

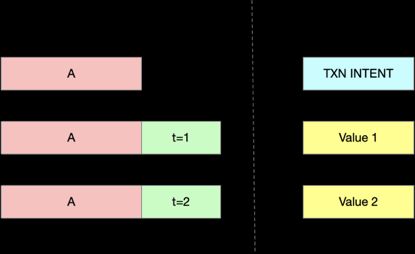
如上图所示,这是一个标准的事务过程。CockroachDB通过一张分布式的全局事务表记录事务记录。CockroachDB的range中的数据分为系统数据和用户数据(通过不同的前缀区分)。一个事务的事务记录一般存储在该事务的第一条写记录所在的range,事务记录作为系统数据而存储和用户数据区分开来。
一个事务记录包含如下核心信息:
UUID:事务记录唯一标识符
Key:事务记录的Key,用来定位事务记录的位置
Timestamp:事务提交时间
Status:事务状态,PENDING、STAGING、COMMITED、ABORTED
Priority:事务优先级
LastHeartbeat:事务协调者发送的最后一次心跳时间
说明:事务状态STAGING是介于PENDING和COMMITED之间的一种状态。它的意思是处于这种状态的事务,不能确定所有的写入都已经成功(比如协调者中途crash),这种场景下会触发RecoverTxn流程,如果确定所有的写都成功,那么状态修改未COMMITED,否则就是ABORTED。
[跟踪代码,未发现设置STAING的流程,怀疑这个还不完善,需要进一步确认]
4.3 事务原子性
事务开始时,事务协调者会创建一个唯一的事务ID(UUID),同时取一个时间戳作为事务的提交时间戳,这个时间戳可能会因为事务冲突而被修改。协调者会随机分配一个事务优先级,这个优先级在将来的事务冲突裁决时有用,事务的优先级也会因为事务的重启而发生变化。
事务的初始状态时PENDING,事务过程中所有的写都被以INTENT的方式写入range,当参与事务的记录都prepare success之后,协调者只需要修改事务记录的状态为COMMITED即可返回给客户端,单条记录的修改raft和RocksDB均可以保证,进而保证事务的原子性。协调者会将事务数据异步提交,但是无需保证一定提交(事务冲突章节会详细描述解决之道)。
CockroachDB的事务在生命周期内只需要一个时间戳,这一点不同Dgraph,tiDB等很多DB的事务做法(一次事务需要两个时间戳startTime,commitTime),在冲突很小的时候,效率比较高,不过这也使得全局快照稍微复杂一些。
4.4 两阶段事务
CockroachDB实现的是一个无锁的两阶段提交事务模型,事务冲突通过事务重启或者回滚尽快返回客户端由客户端决策下一步如何处理。CockroachDB两阶段事务具体执行过程如下所示:
1. 产生事务记录,事务状态为PENDING,也就是BeginTransactoin。
2. 参与节点以WRITE INTENT的形式写入数据,并返回候选时间戳。
3. 比较候选时间戳中最大的时间戳和事务起始时间戳是否相等,以及事务隔离级别,决定事务状态被修改为COMMITED还是ABORTED。SI隔离级别可以容忍候选和提交时间戳不一致,但是对于SSI隔离级别的事务来说,如果候选和提交时间戳不相等则事务重启。
4. 事务提交/回滚之后,残留的WRITE INTENT将被异步清理。
5. 通常情况下会选择事务中遇到的第一个写操作的Key作为事务记录的Key,此时才会真正把事务记录持久化到事务记录表中。这样做的好处是,对于只读事务不需要记录事务状态。
4.5 一阶段事务
如果一个事务所有的写提交都落在一个range上,那么CockroachDB会启动一个Fast 1PC,将所有的修改记录一次性提交给range,由raft log保证这些记录的ACID,免去写事务记录和INTENT。
4.6 事务冲突
当读写操作遇到Intent 记录或新提交的数据时就产生了事务冲突。事务冲突会导致事务重启或者事务中断。
4.6.1 事务重启
事务重启时,会分配一个新的优先级和更大的HLC,并且复用原来的事务ID,事务之前曾经写入一些Intent,这些需要显式的清理,不过一般情况下,事务重启会覆盖原来的记录,因此并不需要这样做。
4.6.2 事务中断
事务中断时,事务记录中的状态时Abort,这时需要将控制权交给客户端,然后删除事务已经写入的Intent,协调者并不保证一定删除这些Intent,后续的其他读写事务遇到冲突的时候会顺便删除这些记录。
[暂时还没有梳理出来事务记录表中的事务记录时什么时候被GC]
4.6.3 读写冲突
当一个读请求(时间戳Read.t,优先级Read.p)读取到INTENT记录后,会比较INTENT中的事物提交时间戳(Txn.t)和优先级(Txn.p)裁定冲突解决。
如果Read.t < Txn.t,分两种情况:
A. Read.t + ε< Txn.t,没有冲突,读操作可以继续。如果读操作遇到本事务内的一个Intent,那么这个Intent可以读。
B. Read.t < Txn.t < Read.t + ε,这种场景下不能确认Intent是否对读事务可见,因此读事务以更大的时间戳重启。
如果Read.t > Txn.t,查询写事务的事务记录,如果事务已经提交,那么Intent可见,否则,分两种情况处理
A. 如果该Intent来自于SI隔离级别的事务,则把该写事务的提交时间戳推迟(因此该Intent对读事务不可见)。实现很简单,只需更新写事务在事务记录表中的事务提交时间戳,从而保证该事务必定使用一个更大的时间戳提交。
B. 如果该Intent来自于SSI隔离级别的事务,则先比较两者优先级。如果读事务具有更高优先级,则延后写事务的提交时间戳(该写事务提交时发现提交时间戳被修改,则事务重启);如果优先级相同或更低,则读事务使用新优先级max(新随机优先级,写事务优先级-1)重启。
4.6.4 写读冲突
Range上都维护一个timestamp cache(内部分为read cache和write cache),读操作会更新这个cache,写事务结束时也会更新这个cache。
每个写操作都会访问所在节点的读缓存(Read
Timestamp Cache)。如果写操作的候选时间戳早于缓存的低水位线(最后被换出的时间戳),那么读缓存的低水位线将作为该事务新的候选时间戳;如果写操作遇到一条Key相同且读时间戳晚于当前事务候选时间戳的记录,那么Key的读时间戳将作为该事务新的候选时间戳。
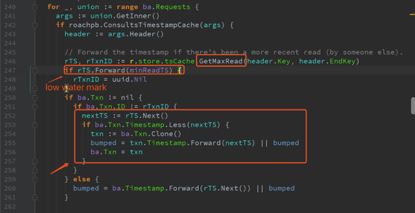
[timestamp cache中数据淘汰还需要确认]
[range lease切换是否存在问题需要确认]
4.6.5 写写冲突
如果写操作遇到未被提交的Intent:1. 如果写入Intent的事务优先级更低,则该事务被终止;2. 如果写入Intent的事务优先级相同或更高,则该事务随机等待一段时间后,以新优先级max(随机优先级,当前事务优先级-1)重启。
如果写操作遇到新提交数据:无论该已提交的数据是Intent或非Intent,当前事务以相同优先级重启,而且使用该数据时间戳作为候选时间戳。
4.7 事务异常
事务协调者在创建事务记录之后会定期向事务记录发送心跳,即修改事务记录的LastHeartBeat。如果事务协调者异常,那么最多一个心跳周期后,其他冲突的事务就会检测到这种异常,然后确认是提交事务还是终止事务。
4.8 全局快照
CockroachDB的readonly操作并不走raft流程,它通过latches来解决读操作和raft log中即将应用的写操作之间潜在的冲突,这种冲突会导致不同的副本应用相同的log获得不同的结果,同样也会破坏快照读。
具体的做法是这样,无论写操作还是读操作,都需要以事务的提交时间戳注册一个latches(详细的latches管理还没有顺理),它会等待所有小于这个时间戳的事件都处理完成(与事务冲突没关系),这个原理跟badger中的事务安全提交和读取原理类似(badger中有一个water mark模块来管理),读写操作完成后会释放这个latches。
这就保证了一个读事务会等待(等待最长时间是60秒)所有小于这个注册时间戳的读写事务都完成后才会启动。
[还未仔细推演leader切换场景下,这个逻辑的正确性]