我是一名C++软件开发程序员,今年的5月份,在一个长沙的区块链活动上认识、了解了初链,这个区块链公链项目。在活动中,听了初链CEO张剑南对于他们自己在共识算法上的创新,即混合共识的分享。
对于张总的分享,我几乎没能听懂,更不能领悟其中的真谛。但是作为一个软件开发工作者的我,能明显的感觉出来,张总绝对是一个对技术有深入研究的极客,给人踏实、谦虚的感觉,而非玩弄资本的所谓庄家们。
从那以后,我逐步对区块链的知识进行学习,去了解了各种各样的共识算法,认识它们各自的优略势。更认识到了初链的共识算法在其中的理论上的优越性,在初链的白皮书和社区开发者分享的学习心得中已经有了详细的描述(尤其是“…为问题的解决带来一丝曙光”这一段,几乎每篇学习心得里面都有,大伙应该是做梦都能背出来了吧),这里不再赘述。
为了更对初链的底层技术有个更深入的了解,我先是去了解了以太坊主要的数据结构。下面是对以太坊交易数据的主要存储结构MPT及其编码规则PLP的一些知识点的整理,望指教。
一、MPT
默克尔帕特里夏树(Merkle Patricia tree/trie),由Alan Reiner提出设想,并在瑞波协议中得到实现,是以太坊的主要数据结构,用于存储所有账户状态,以及每个区块中的交易和收据数据。
MPT是结合了Merkle Tree(默克尔树)和 Patricia Tree(帕特里夏树)的一种数据结构。
1、MT
Merkle Tree
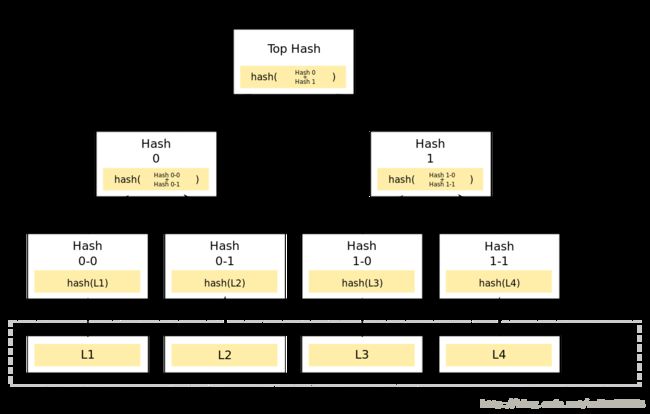
Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值。非叶节点是其对应子节点串联字符串的hash值。
在最底层,和哈希列表一样,我们把数据分成小的数据块,有相应地哈希和它对应。但是往上走,并不是直接去运算根哈希,而是把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,这样每两个哈希就结婚生子,得到了一个”子哈希“。如果最底层的哈希总数是单数,那到最后必然出现一个单身哈希,这种情况就直接对它进行哈希运算,所以也能得到它的子哈希。于是往上推,依然是一样的方式,可以得到数目更少的新一级哈希,最终必然形成一棵倒挂的树,到了树根的这个位置,这一代就剩下一个根哈希了,我们把它叫做 Merkle Root。
采用默克尔树的好处是可以方便的判断一个交易是否在区块中,比如我们将数据块L4下载下来了,那么我们如何验证L4是否是合法且完整的数据块?
我们只需要三个步骤:
第一、算出L4的哈希值(hash 1-1)。
第二、将L4的哈希值和已知的L3(hash 1-0)的哈希值做运算得到哈希值hash1
第三、将已知的hash0和hash1做运算得到Tophash。
最后我们用计算得到的tophash和已知的tophash做比较,如果一样则L4合法且完整。
这样的一个校验过程比起将所有的数据块的哈希值重新运算一遍还是显得优化了很多。
2、PT
Patricia Tree
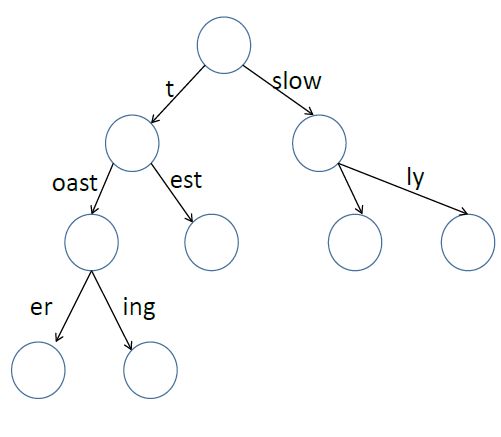
帕特里夏树可称为压缩前缀树,解决的是存储效率的问题,如上图,有相同的前缀的字符串在同一分支中,再将不同的部分分叉出来,如test和toast,都有相同的t,再分叉出est和oast两个部分。这个结构的好处是节省空间,因为每一级的键值可以是多个字符。
比如有一棵存储键值对的树,但其中的键长度有几百字符长,那么每个字符的那个层级你都需要大量的额外空间。每次查找和删除都会有上百个步骤。在这里我们引入Patricia树就让这个问题便的简单了。
3、MPT
在以太坊(ethereum)中,使用了一种特殊的十六进制前缀(hex-prefix, HP)编码,所以在字母表中就有16个字符。这其中的一个字符为一个nibble。
MPT树中的节点有四种类型:空节点、叶子节点、扩展节点和分支节点。
空节点,简单的表示空,在代码中是一个空串。
叶子节点(leaf),表示为[key,value]的一个键值对,其中key是key的一种特殊十六进制编码,value是value的RLP编码。
扩展节点(extension),也是[key,value]的一个键值对,但是这里的value是其他节点的hash值,这个hash可以被用来查询数据库中的节点。也就是说通过hash链接到其他节点。
分支节点(branch),因为MPT树中的key被编码成一种特殊的16进制的表示,再加上最后的value,所以分支节点是一个长度为17的list,前16个元素对应着key中的16个可能的十六进制字符,如果有一个[key,value]对在这个分支节点终止,最后一个元素代表一个值,即分支节点既可以搜索路径的终止也可以是路径的中间节点。
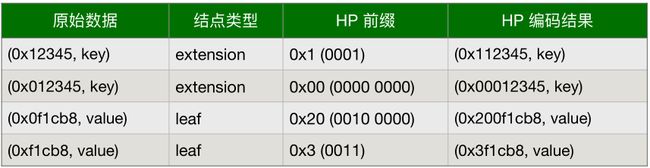
MPT树中另外一个重要的概念是一个特殊的十六进制前缀(hex-prefix, HP)编码,用来对key进行编码。因为字母表是16进制的,所以每个节点可能有16个孩子。因为有两种[key,value]节点(叶节点和扩展节点),引进一种特殊的终止符标识来标识key所对应的是值是真实的值,还是其他节点的hash。如果终止符标记被打开,那么key对应的是叶节点,对应的值是真实的value。如果终止符标记被关闭,那么值就是用于在数据块中查询对应的节点的hash。无论key奇数长度还是偶数长度,HP都可以对其进行编码。最后我们注意到一个单独的hex字符或者4bit二进制数字,即一个nibble。
HP编码很简单。一个nibble被加到key前(下图中的prefix),对终止符的状态和奇偶性进行编码。最低位表示奇偶性,第二低位编码终止符状态。如果key是偶数长度,那么加上另外一个nibble,值为0来保持整体的偶特性。
十六进制前缀(Hex-Prefix)编码如图所示:
Hex-Prefix
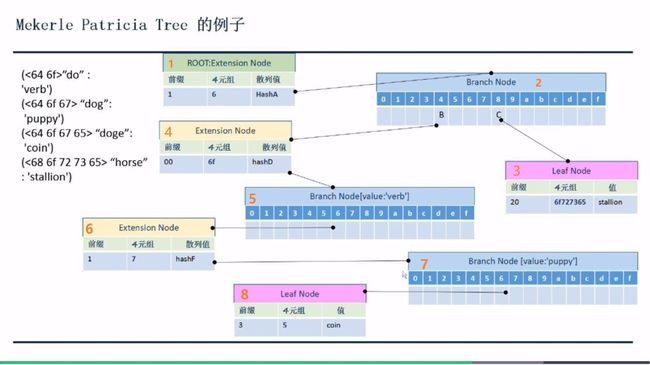
下面是MPT的一个示例。
MTP实例
下面挨个节点进行解析。
1.、根节点
因为4组数据都有公共的6,所以这个节点的值为6,长度为1,奇数;节点类型:扩展节点;所以前缀就是0001,即1。
这是个扩展节点,它的值是一个Hashvalue,它指向一个分支节点。Hashvalue,具体指的是分支节点RLP编码的结果的散列值。
2、分支节点
上面4组数据的第2位是4和8两种情况。在4的位置上存的是下面的扩展节点的散列值,在8的位置上存的是下面的叶子节点的散列值。
3.、叶子节点
以68开头的只有一个了。所以这个节点上的四元组就是68后面的数字6f727365了。长度为8,为偶数。前缀是0x20。这个叶子节点的value存储了'stallion'。
4.、扩展节点
在64之后,公共的部分是6f,这个扩展节点的key即为6f,前缀为0000,即00。这个扩展节点的value存放的是一个hashvalue,指向下一个节点,一个分支节点。
5.、分支节点
646f已经表达完,这个节点的value值就是646f对应的值,'verb'。
除此之外,646f之后就是6,所以在这个分支节点的6位置上有一个散列值,指向下一个节点。
6、扩展节点
在646f6之后,公共的部分是7,其长度为1,奇数。所以前缀为0001。这个节点的value是一个散列值,指向下一个节点。
7、分支节点
646f67已经表达完,这个节点的value值就是646f67对应的值,'puppy'。
除此之外,646f67之后就是6,所以在这个分支节点的6位置上有一个散列值,指向下一个节点。
8、叶子节点
key为5,value为'coin'。长度为1,奇数,前缀0011,即3。
整个分析过程结束。
二、RLP
1、RLP简介
RLP(Recursive Length Prefix,递归的长度前缀)是一种编码规则,可用于编码任意嵌套的二进制数组数据。RLP编码的结果也是二进制序列。RLP主要用来序列化/反序列化数据。
序列化主要是指把内存表示的数据存放到数据库里面, 反序列化是指把数据库里面的Trie数据加载成内存表示的数据。 序列化的目的主要是方便存储,减少存储大小等。 反序列化的目的是把存储的数据加载到内存,方便Trie树的插入,查询,修改等需求。
RLP已经成为以太坊中对对象进行序列化的主要编码方式。RLP的唯一目标就是解决结构体的编码问题;
2、RLP定义
RLP编码的定义只处理以下两类数据:
1、字符串(string)是指字节数组。例如,空串"",再如单词"cat",以及句子"Lorem ipsum dolor sit amet, consectetur adipisicing elit"等。
2、列表(list)是一个可嵌套结构,里面可包含字符串和列表。例如,空列表[],再如一个包含两个字符串的列表["cat","dog"],在比如嵌套列表的复杂列表["cat", ["puppy", "cow"], "horse", [[]], "pig", [""], "sheep"]。
其他类型的数据需要转成以上的两类数据,才能编码。转换的规则RLP编码不统一规定,可以自定义转换规则。例如struct可以转成列表,int可以转成二进制序列(属于字符串这一类, 必须去掉首部0,必须用大端模式表示)(大端模式用文字描述是,低地址上存放高字节,高地址上存放低字节,反之为小端模式)。
从上面的数据类型定义中可以看出,RLP编码的数据是可嵌套的。从RLP编码的名字可以看出,RLP编码是递归的。
3、RLP编码规则
RLP编码的重点是给数据前面添加一个字节的前缀,而这个前缀是和数据的长度相关的。
RLP编码中的长度是数据的实际存储空间的字节大小,去掉首位0的正整数,用大端模式表示的二进制格式表示。
RLP编码规定数据(字符串或列表)的长度的长度不得大于8字节。因为超过8字节后,一个字节的前缀就不能存储了。
3.1、长度为1个字节的字符串,并且它的ASCII值在[0x00, 0x7f] 范围之间,那么其RLP编码就是字符串本身。即前缀为空,用前缀代表字符串本身;
3.2、长度是0-55字节的字符串,其RLP编码是前缀跟上(拼接)字符串本身,前缀的值是0x80加上字符串的长度。由于在该规则下,字符串的最大长度是55,因此前缀的最大值是0x80+55=0xb7,所以在本规则下前缀(第一个字节)的取值范围是[0x80, 0xb7];
3.3、长度大于55个字节的字符串,其RLP编码是前缀跟上字符串的长度再跟上字符串本身。前缀的值是0xb7加上字符串长度的二进制形式的字节长度(即字符串长度的存储长度)。即用额外的空间存储字符串的长度,而前缀中只存字符串的长度的长度。例如一个长度是1024的字符串,字符串长度的二进制形式是\x04\x00,因此字符串长度的长度是2个字节,所以前缀应该是0xb7+2=0xb9,由此得到该字符串的RLP编码是\xb9\x04\x00再跟上字符串本身。因为字符串长度的长度最少需要1个字节存储,因此前缀的最小值是0xb7+1=0xb8;又由于长度的最大值是8个字节,因此前缀的最大值是0xb7+8=0xbf,因此在本规则下前缀的取值范围是[0xb8, 0xbf];
以上3个规则是针对字符串的,接下来的两个规则针对列表的。由于列表的任意嵌套的,因此列表的编码是递归的,先编码最里层列表,再逐步往外层列表编码。
3.4、列表的总长度(payload,列表的所有项经过编码后拼接在一起的字节大小)是0-55字节,其RLP编码是前缀依次跟上列表中各项的RLP编码。前缀的值是0xc0加上列表的总长度。在本规则下前缀的取值范围是[0xc0, 0xf7]。本规则与规则2类似;
3.5、列表的总长度大于55字节,它的RLP编码是前缀跟上列表的长度再依次跟上列表中各元素项的RLP编码。前缀的值是0xf7加上列表总长度的长度。编码的第一个字节的取值范围是[0xf8, 0xff]。本规则与规则3类似;
4、 RLP编码举例
4.1、整数 0('\x00') = [0x00] (规则一)
4.2、整数 1024('\x04\00') = [0x82, 0x04, 0x00] (规则二)
4.3、空字符串('null') = 0x80 (规则二)
4.4、字符串 "dog" = [0x83, 'd', 'o', 'g' ] (规则二)
4.5、字符串 "Lorem ipsum dolor sit amet, consectetur adipisicing elit" = [0xb8, 0x38, 'L', 'o', 'r', 'e', 'm', ' ', ... , 'e', 'l', 'i', 't'] (规则三)
4.6、空列表 [] = [0xc0] (规则四)
4.7、列表 ["cat","dog"] = [0xc8, 0x83, 'c', 'a', 't', 0x83, 'd', 'o', 'g' ] (规则四)
4.8、嵌套列表 [ [], [[]], [ [], [[]] ] ] = [0xc7, 0xc0, 0xc1, 0xc0, 0xc3, 0xc0, 0xc1, 0xc0] (规则四)
(注意:7、8中的嵌套长度,如7中列表字符总长为6,总字符串数为2,所以总长度应为8,所以0XC0 + 8 = 0XC8)
5、 RLP解码规则
根据RLP编码规则和过程,RLP解码的输入一律视为二进制字符数组。
5.1、首字节(prefix)的值在[0x00, 0x7f]范围之间,那么该数据是字符串,且字符串就是首字节本身;
5.2、首字节的值在[0x80, 0xb7]范围之间,那么该数据是字符串,且字符串的长度等于首字节减去0x80,且字符串位于首字节之后;
5.3、首字节的值在[0xb8, 0xbf]范围之间,那么该数据是字符串,且字符串的长度的字节长度等于首字节减去0xb7,数据的长度位于首字节之后,且字符串位于数据的长度之后;
5.4、首字节的值在[0xc0, 0xf7]范围之间,那么该数据是列表,在这种情况下,需要对列表各项的数据进行递归解码。列表的总长度(列表各项编码后的长度之和)等于首字节减去0xc0,且列表各项位于首字节之后;
5.5、首字节的值在[0xf8, 0xff]范围之间,那么该数据为列表,列表的总长度的字节长度等于首字节减去0xf7,列表的总长度位于首字节之后,且列表各项位于列表的总长度之后;
6、总结
与其他序列化方法相比,RLP编码的优点在于,当接收或者解码经过RLP编码后的数据时,根据第1个字节就能推断数据的类型、大概长度和数据本身等信息,并且能编码相当大的数据。
以上是MPT数据结构和RLP编码的简介,熟悉这两部分内容有助于掌握以太坊的整体脉络。